





Wie SnapLogic den komplexen Prozess des Ladens von Salesforce-Daten in Amazon Redshift vereinfacht
Während ich an einem komplexen Salesforce-Datenintegrationsprojekt arbeitete, begann ich etwas zu bauen, das sich für mich zu einem Kunstwerk entwickelte. Warum ich das glaube? Ich werde es erklären. Ich habe schon mit vielen Daten- und Application Integration -Tools gearbeitet, aber keines davon verschafft mir dieselbe Art von künstlerischer Befriedigung wie die SnapLogic Intelligent Integration Platform. Es ist kein Code involviert - es geht nur um Drag & Drop und einfaches Scripting. Und doch löst die Lösung das sehr komplexe Problem des Ladens von Salesforce-Daten in das Amazon Redshift Cloud Data Warehouse.
Nach meiner Erfahrung mit anderen Integrationstools konnte keines dieses Problem auf so einfache, elegante und künstlerische Weise lösen. Tatsächlich habe ich die SnapLogic-Integrationspipeline, die ich für diesen Anwendungsfall erstellt habe, ausgedruckt und gerahmt an die Wand meines Arbeitszimmers gehängt.
Bevor ich auf die Einzelheiten der Konstruktion der Pipeline eingehe, möchte ich zunächst das Problem definieren.
Die Herausforderung: Verschieben von Salesforce-Daten nach Redshift
Vor einiger Zeit habe ich Box, einem führenden Cloud-Content-Management-Unternehmen und SnapLogic-Kunden, bei einem umfangreichen Integrationsprojekt geholfen. Das Team von Box stellte diese Anforderungen.
"Wir möchten Salesforce-Daten in ein Data Warehouse extrahieren, in diesem Fall Amazon Redshift. Aber die Salesforce-Datenobjekte werden häufig aktualisiert und neue Felder werden regelmäßig hinzugefügt. Daher müssen die Redshift "Load"-Tabellenschemata geändert und neue Felder aus Salesforce extrahiert werden. Außerdem haben wir in Redshift zahlreiche Datenbankansichten definiert, die von den "Load"-Tabellenschemata abhängen. Alle Views müssen aktualisiert werden."
Derzeit ist es ein manueller Prozess, die Redshift-Tabellenschemata so zu ändern, dass sie mit den Salesforce-Entitäten übereinstimmen, das Salesforce-SOQL-Skript zu aktualisieren, um die neuen Salesforce-Datenfelder abzurufen, Daten in Redshift-Tabellen zu laden und schließlich die abhängigen Redshift-Ansichtsschemata zu aktualisieren. Multiplizieren Sie dies mit der Anzahl der Salesforce-Entitäten, dann wird dies zu einer sehr langwierigen Aufgabe.
Und nun die Kunst!
SnapLogic-Pipeline: Code-arme Integration von Salesforce-Daten
Die erste Pipeline vergleicht die Salesforce-Entitätsfelder mit dem zugehörigen Redshift-Tabellenschema "Load", um Unterschiede festzustellen, führt eine Aktualisierung der Redshift-Tabelle "Load" durch und erstellt schließlich die Salesforce-SOQL-Anweisung.
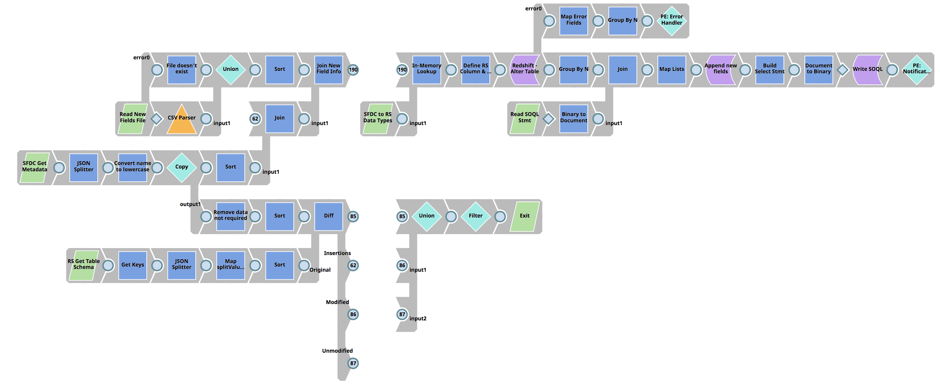
Ausführlichere Schritte:
- Verwendet die Salesforce-Metadaten-API, um alle Felder für eine Salesforce-Entität zurückzugeben
- Abrufen des Tabellenschemas für die Redshift-Ladetabelle der zugehörigen Salesforce-Entität
- Verwenden Sie den Diff-Snap, um Unterschiede zwischen Salesforce-Entitätsfeldern und Redshift-Ladetabellenspalten zu ermitteln.
- Verknüpfen Sie die Ausgabe des Diff-Snap (die Unterschiede zwischen der Salesforce-Entität und der Redshift-Lasttabelle) mit den Salesforce-Metadaten, um alle Salesforce-Entitätsfeldinformationen zu erhalten
- Verwenden Sie den In-Memory-Snap und führen Sie einen Lookup durch, um den Salesforce-Feldtyp mit dem Redshift-Datentyp abzugleichen.
- Fügen Sie die neue(n) Spalte(n) mit dem Redshift Execute Snap dem Redshift Load Table Schema hinzu.
- Laden Sie die vorherige Version der Salesforce SOQL-Anweisungsdatei und fügen Sie die Liste der neuen Salesforce-Datenfelder hinzu
- Aktualisieren Sie die SOQL-Anweisungsdatei, um neue Felder aufzunehmen und in die SLDB zu schreiben.
Als Nächstes extrahieren Sie die Daten aus Salesforce mit Hilfe des SOQL-Statements und laden sie in großer Menge in Redshift:
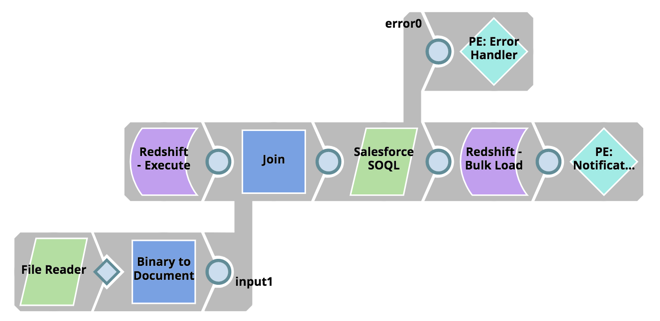
- Lesen Sie das aktualisierte SOQL Statement Script aus der SLDB
- Abrufen des letzten Änderungsdatums aus der Redshift-Ladetabelle
- Nutzen Sie die Salesforce SOQL-API unter Verwendung des Salesforce SOQL-Snap und rufen Sie alle Datensätze ab dem Datum der letzten Änderung ab
- Verwenden Sie den Redshift Bulk Load Snap, um die Daten in Redshift zu laden.
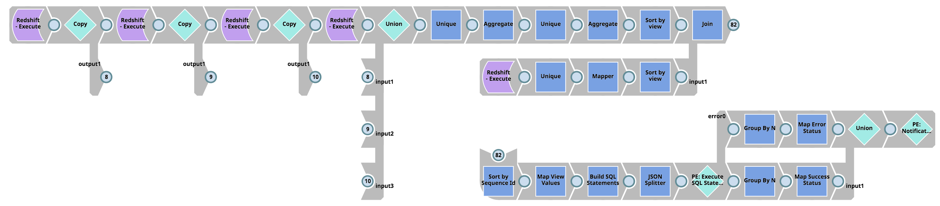
Und schließlich bestimmen Sie die Abhängigkeiten der Redshift-Tabelle "Load" View, rufen View-Schemata aus Redshift ab (d. h. die Tabelle pg_views), erstellen die SQL-Skripte zum Löschen, Erstellen und Erteilen von Berechtigungen für die Views und führen die SQL-Anweisungen in Redshift aus:
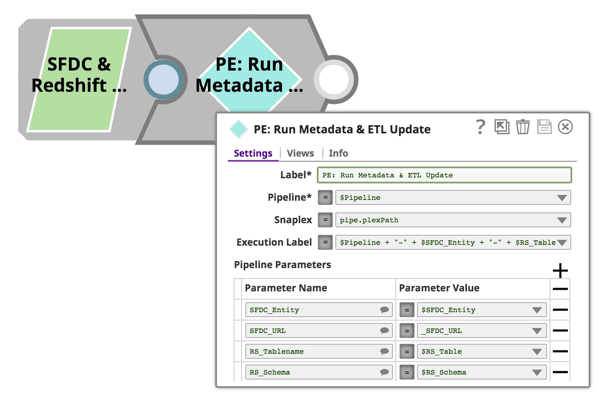
Alle oben beschriebenen Pipelines akzeptieren Pipeline-Parameter, sodass wir einen objektorientierten Ansatz verwenden und diese Pipelines für alle Salesforce-Entitäten und Redshift-Tabellen wiederverwenden können. Dies wird erreicht, indem man einfach den Pipeline Execute Snap verwendet und die Namen der Salesforce-Entitäten, Redshift-Tabellen, Pipeline-Namen usw. angibt. Auch dies wird über die Konfiguration des Pipeline Execute Snap erreicht:
In meinen Augen besteht die Kunst hier darin, dass all diese Funktionen schnell und ohne Programmieraufwand erreicht werden. Die Pipelines sind visuell ansprechend und technisch schön, wenn man die zugrunde liegende Logik und die schwere Arbeit, die die SnapLogic-Laufzeitumgebung leistet, berücksichtigt.
Möchten Sie die mehr als 500 vorgefertigten Konnektoren (Snaps) von SnapLogic nutzen, um alle Ihre unterschiedlichen Daten und Anwendungen zu integrieren? Starten Sie noch heute eine kostenlose Testversion.




