Daten sind ein wichtiges Gut für jedes Unternehmen und ermöglichen es den Führungskräften, fundierte Geschäftsentscheidungen zu treffen. Allerdings sind sie auch zu einem großen Hindernis für diejenigen geworden, die den Zustand ihres Unternehmens analysieren und nach Möglichkeiten zur Verbesserung des Geschäfts suchen. Im ersten Teil meiner zweiteiligen Serie werde ich detailliert beschreiben, wie SnapLogic diese Hindernisse überwunden hat, um mit Cloud Data Lake und Self-Service-Analysen datengesteuert zu werden.
Datenbarrieren
Die Gewinnung von Erkenntnissen aus Daten kann aufgrund verschiedener Faktoren leicht entgleisen, darunter:
- Keine einzige Quelle der Wahrheit: Die Daten sind in verschiedenen Quellen und Abteilungen verstreut.
- Keine Standardisierung: Daten liegen in vielen Formen vor, z. B. strukturiert, halbstrukturiert und unstrukturiert
- Unreine Daten: Die Daten müssen vertrauenswürdig sein und erfordern daher zusätzliche Arbeit, z. B. das Entfernen von Datenduplikaten, das Auffinden fehlender Werte usw., um die Qualität zu verbessern.
- Fehlende Datenversionierung: Daten können exponentiell wachsen und schwer zu überblicken sein
Unternehmen sahen sich auch mit verschiedenen Herausforderungen konfrontiert: starre interne Prozesse, die Übernahme von langlaufenden Legacy-Technologien, keine abteilungsübergreifende Zusammenarbeit bei der gemeinsamen Nutzung von Daten, was alles zu einem manuellen und fehleranfälligen Ansatz führte.
Die oben genannten Faktoren in Kombination mit einem Mangel an Initiativen zur digitalen Transformation (Cloud-Einführung, Kulturwandel, agile Prozesse usw.) können Unternehmen daran hindern, aussagekräftige 360-Grad-Einblicke zu gewinnen. In der heutigen Wirtschaft können sich schlechte Daten auf das Kundenerlebnis, das Umsatz- und Gewinnwachstum auswirken, die Kundenabwanderung erhöhen und potenzielle Chancen verhindern.
Bei SnapLogic den Wandel zuerst mit Daten einleiten
Wir hatten bei SnapLogic ähnliche Probleme - wir trafen Entscheidungen auf der Grundlage von Erkenntnissen aus Daten, die aus unterschiedlichen Systemen und isolierten Datensätzen zusammengetragen wurden. Die Bemühungen zur Gewinnung von Erkenntnissen waren nicht gerade ideal und erforderten viele Stunden, um stapelorientierte Daten manuell zusammenzufügen. Kollegen aus verschiedenen Abteilungen, darunter auch ich, erstellten regelmäßige und einmalige Berichte, für die spezifische Daten erforderlich waren, die nicht immer ohne weiteres verfügbar waren. In einigen Fällen hatten wir weder einen ganzheitlichen Überblick darüber, wie unsere Kunden unser Produkt nutzten, noch verstanden wir die Stimmung der Kunden, um unser Portfolio zu erneuern.
Nachdem wir eine unendliche Anzahl von Berichten erstellt hatten, die jedoch nur sehr wenige Erkenntnisse brachten, wurde uns klar, dass wir ein gemeinsames, einheitliches Rahmenwerk brauchten, um die Barrieren beim Datenzugriff zu überwinden, damit wir verwertbare Erkenntnisse gewinnen und Entscheidungen auf der Grundlage von Daten treffen konnten.
SnapLogic investiert in einen Datensee
Auf der Grundlage meiner früheren Beobachtungen zu unseren Datenbeschränkungen wollte SnapLogic datenorientierter werden und investierte in eine Cloud Data Lake-Analyseinitiative. Ich leitete diese Initiative und holte die Stakeholder ins Boot, um ihre geschäftlichen Anforderungen zu verstehen und dann ein Daten-Framework zu erstellen, das diese Anforderungen erfüllen würde. Nach wochenlanger Feinabstimmung der Geschäftsanforderungen und der Formulierung unserer Datenstrategie bauten wir eine Multi-Terabyte-Cloud-Data-Lake-Lösung, um eine einzige Quelle der Wahrheit zu schaffen. Ziel war es, den wichtigsten internen Nutzern "Self-Service-Analysen" zu ermöglichen, um neue Möglichkeiten zu entdecken, Lücken zu ermitteln usw. Unser Daten-Framework basierte auf den Anforderungen von SnapLogic und den Zielen, die wir erreichen wollten. Auch wenn unsere Bedürfnisse einzigartig sind, benötigen alle Unternehmen eine Reihe von Prinzipien für einen gemeinsamen Datenrahmen, um datengesteuert zu sein.
Nachfolgend finden Sie eine Reihe von Schritten, die SnapLogic durchlaufen hat, um unsere Data-Lake-Strategie zu definieren und die Zustimmung der Beteiligten zu gewinnen. Diese Schritte sind auf jedes Unternehmen anwendbar, das eine Data-Lake-Initiative durchführt.
1. Identifizierung der Herausforderung
Erkennen und akzeptieren Sie zunächst die Tatsache, dass es ein Hindernis bei der Beschaffung der richtigen Daten gibt, was bedeutet, dass Sie ineffektive tägliche Abläufe und die Unfähigkeit, wichtige Entscheidungen zu treffen, erlebt haben. Sobald die Datenprobleme erkannt sind, muss sich das Führungsteam zusammensetzen, um wichtige Dateninitiativen zu definieren, die die Geschäftsziele des Unternehmens vorantreiben. Diese Art von Initiativen kann durch Katalysatoren oder organisatorische Veränderungen angestoßen werden, z. B. durch Veränderungen der Kultur und der Führung, betriebliche Veränderungen, Verbesserung der teamübergreifenden Zusammenarbeit und agile Prozesse. Wir haben auch einige grundlegende, aber notwendige betriebliche Änderungen daran vorgenommen, wie die Daten den verschiedenen Teams, einschließlich Technik, Vertrieb, Finanzen und Marketing, zur Verfügung gestellt werden können.
2. Erstellen einer Vision für den Data Lake
Um unsere geschäftlichen Herausforderungen zu verstehen, wurden tiefere Analysen und Untersuchungen durchgeführt. Die Entwicklung einer Vision für die Datenstrategie von SnapLogic war entscheidend, um uns bei der Konzentration auf eine Reihe wichtiger Geschäftsziele zu helfen:
- Bieten Sie unternehmensweite Transparenz
- Einflussnahme auf Produktplanung, Preisgestaltung und Investitionen
- Treffen Sie fundierte Entscheidungen auf der Grundlage von Daten und nicht von Meinungen
- Erweitern oder Aufdecken von Absatzmöglichkeiten und dadurch Steigerung der Einnahmen
- Verringern Sie die Kundenabwanderung durch proaktives Handeln
- Verstehen der Customer Journey und Erkennen möglicher Lücken
- Verbesserung der Produktpositionierung
Anschließend wurden Ziele definiert, um zu vermitteln, warum der Aufbau eines Data Lake wichtig ist und wie die verschiedenen Abteilungen davon profitieren können. Bei SnapLogic haben wir klar definiert, welche Daten wir verstehen und visualisieren müssen. Dazu gehörten Datenpunkte, um die Customer Journey zu beschreiben, den Verbrauch oder die Nutzung der Nutzer zu messen, etwas über die verschiedenen Nutzer-Personas zu erfahren, die Nutzung mit Branchen, Regionen und Größen zu korrelieren usw. Indem wir diese Arten von Informationen den verschiedenen Geschäftsbereichen (LOBs) des Unternehmens zuordneten, konnten wir von den Daten profitieren, die zuvor zwar verfügbar, aber unerreichbar waren.
3. Einholung der Genehmigung der Exekutive
Die Einholung von Feedback zu unserer Vision von unseren Champions und Stakeholdern hat uns von Anfang an geholfen. Auf Feedback zu hören, bedeutet oft mehrere Iterationen, aber das ist es wert, um die Datenvision und -strategie zu verfeinern. Indem ich die Geschäftsziele der Stakeholder verstand, schuf ich eine gemeinsame Vision und verkündete, wie unsere Strategie ihnen helfen könnte, verschiedene Geschäftsvorteile zu realisieren, einschließlich Predictive Analytics.
Nachdem ich unsere Ergebnisse fertiggestellt hatte, stellte ich dem Führungsteam die folgenden Themen vor:
- Vision und Strategie
- Aktuelle Datenbeschränkungen und ihre Auswirkungen auf die Entscheidungsfindung
- Wirtschaftliche Treiber
- Ziele
- Vorteile für die Geschäftsbereiche
- Vorschlag für die Architektur und der Plan
- Kosten und Budget
4. Zusammenarbeit mit den Teams, um die richtigen KPIs zu erhalten
Der Ausführungsplan ist entscheidend, sobald die Data-Lake-Analytics-Initiative genehmigt ist. Durch die Zusammenarbeit mit Managern aus verschiedenen Abteilungen konnte ich wichtige Kennzahlen aufdecken, die sie für dieses Projekt benötigten. Ich habe nicht nur die Probleme und Ziele dieser Manager verstanden, sondern auch viele wichtige Leistungsindikatoren (Key Performance Indicators, KPIs) aufgedeckt, die wir in unserem ursprünglichen Ausführungsplan nicht berücksichtigt hatten. Ich bin davon überzeugt, dass die enge Zusammenarbeit mit jedem Team zu unserem Erfolg beigetragen hat. Ich habe sie ständig über unsere Fortschritte informiert, damit sie wussten, dass wir verantwortlich sind.
Eine gründliche Vorbereitung war ebenfalls der Schlüssel zu unserem Erfolg. Ich habe eine Liste mit Fragen erstellt, auf die unsere Stakeholder mit den richtigen Informationen antworten sollten. Im Folgenden finden Sie einige Fragen, die ich ihnen gestellt habe:
- Was wollen Sie über Ihre Kunden wissen? Wie oft?
- Was möchten Sie über einzelne Nutzer, bestimmte Gruppen oder den gesamten Kundenstamm wissen?
- Wie messen Sie den Erfolg Ihres Teams? Welche Schlüsselkennzahlen überwachen Sie für den Erfolg?
- Welche Art von Ausreißern würden Sie gerne sehen?

Wir haben auch allgemeine Muster und Fragen beobachtet, darunter:
- Was muss getan werden, um unser Geschäft auszubauen?
- Wie viel Prozent der Interessenten wurden zu Kunden? Warum haben sich andere nicht umgewandelt?
- Wie können wir die Weiterbeschäftigung sicherstellen?
- Wie viele Supportfälle werden pro Kunde eröffnet und gelöst?
- Wie hoch sind die durchschnittlichen Kundengewinnungskosten (CAC)?
Das Verstehen von KPIs für diese wichtigen Fragen, das Erstellen einer Liste und das Setzen von Prioritäten waren Teil der nächsten Schritte. Bei SnapLogic bestanden einige der KPIs darin, die Nutzungsmuster der Kunden und die Akzeptanz zu verstehen, festzustellen, ob ein Trend zu- oder abnimmt, und proaktive Warnmeldungen an die richtigen Teams zu senden.
5. Die richtigen Fähigkeiten einstellen
Beim Aufbau und der Weiterentwicklung von Data Lake ist es wichtig zu verstehen, welche Fähigkeiten erforderlich sind.
Bei SnapLogic haben wir ein eigenes Analyseteam eingerichtet, das ich leite und verwalte. Ich habe die Kandidaten sorgfältig geprüft, um sicherzustellen, dass ihre Fähigkeiten unsere Vision und unsere Anforderungen ergänzen würden. Unser Analyseteam besteht aus einem erfahrenen Architekten, der in der Vergangenheit viele Enterprise Data Lakes aufgebaut hat, einer Handvoll Entwickler, die Integrationspipelines und Workflows in der SnapLogic Intelligent Integration Platform (IIP) erstellen, QA, die Daten validieren, und einem Tableau-Experten, der Berichte erstellt.
6. Iteration zur Verfeinerung unseres Data Lake
Damit der Data Lake erfolgreich ist, muss er möglicherweise mehrere Iterationen durchlaufen, bevor er allen Mitarbeitern zur Verfügung gestellt wird. Unser Ziel war es, eine Basisarchitektur zu schaffen, die skalierbar, flexibel, sicher und anpassungsfähig ist, so dass die Tools in der Zukunft leicht ersetzt werden können. Wir verwendeten eine Reihe von Datenbanken und Anwendungen, um den Data Lake zu erstellen.
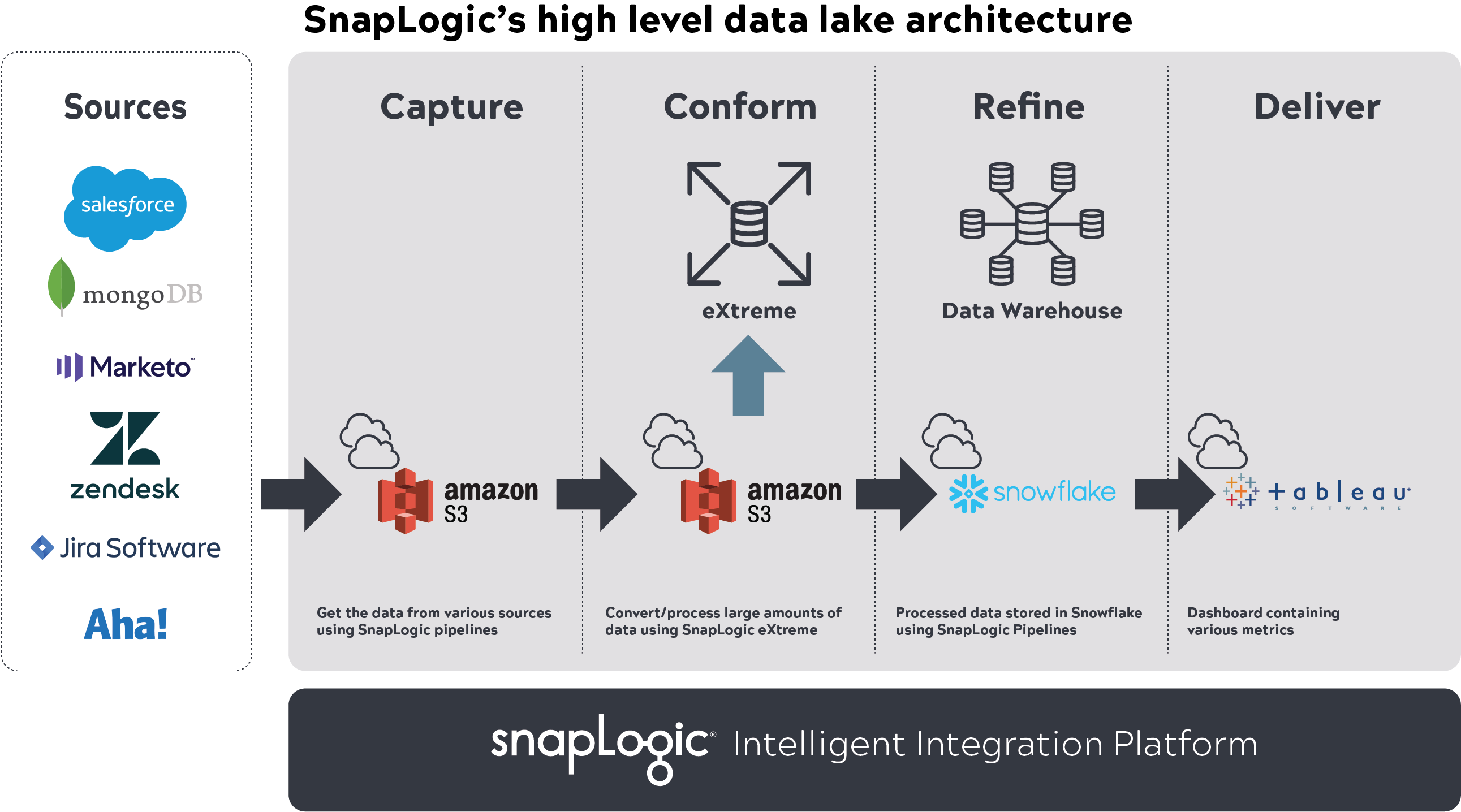
So haben wir beispielsweise Snaplogic IIP zur Erfassung und Anpassung von Multi-Terabyte-Daten in AWS S3, SnapLogic eXtreme zur Verarbeitung großer Datenmengen, Snowflake zur Speicherung verarbeiteter Daten mit SnapLogic und Tableau zur Visualisierung von Berichten verwendet.
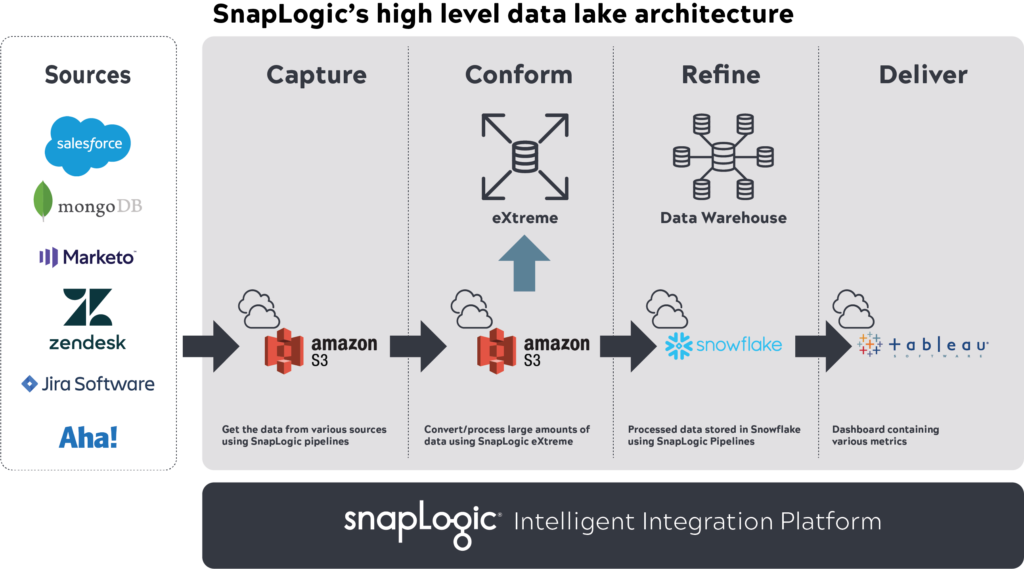
Sobald diese Anwendungen eingerichtet und definiert waren, begannen wir mit der Erfassung von KPIs und anderen von den Beteiligten gewünschten Datentypen. Wir arbeiteten mit ihnen und anderen Teammitgliedern zusammen, um die Anwendungen zu identifizieren, in denen sich die Daten befanden, wobei wir bestimmte sensible Daten ausschlossen, um die Sicherheitsvorschriften zu erfüllen. Das Analyseteam erstellte dann SnapLogic-Pipelines, um Daten aus diesen Quellen in den S3-Datensee aufzunehmen, verarbeitete sie mit SnapLogic eXtreme auf der Grundlage von Geschäftslogik, speicherte das resultierende Star-Schema-Set (Fakten, Dimensionen) in Snowflake und lieferte Erkenntnisse in Tableau. Diese Pipelines wurden automatisiert, um die Erfassung von Änderungsdaten einzubeziehen.
Das DevOps-Team erstellte dann Zugriffsprofile, damit die entsprechenden Personen Zugriff auf diese Datensätze hatten.
Es sind fortlaufende Bemühungen erforderlich, bei denen sich die Geschäftsanwender die jeweiligen Daten zu eigen machen und sie verbessern müssen, damit sie leicht in den Data Lake aufgenommen und verarbeitet werden können. Während des Aufbaus des Data Lake wurden auch verschiedene Lücken identifiziert (Datenqualität, fehlende Datensätze usw.), die von den jeweiligen LOBs behoben wurden. Die gewonnenen Erkenntnisse wurden mit den Führungskräften und verschiedenen Teams geteilt, um ein frühes Feedback zu erhalten. Anschließend haben wir den Data Lake auf der Grundlage des erhaltenen Feedbacks iteriert und verbessert.
Ergebnisse
Ich bin stolz, sagen zu können, dass die Innovationskultur von SnapLogic, die Offenheit für Veränderungen und die transparente Entscheidungsfindung uns geholfen haben, das volle Potenzial unserer Daten auszuschöpfen. Die richtigen KPIs wurden mit Hilfe eines automatisierten Cloud Data Lake und einer Self-Service-Lösung erstellt und visualisiert. Durch den Data Lake erhielten wir eine unternehmensweite Konnektivität und eine einzige Quelle der Wahrheit, konnten fehlende Teile miteinander verbinden und erhielten Transparenz über die Nutzung, die Muster und die Probleme unserer Kunden. Der Data Lake ermöglichte es uns außerdem, sinnvolle Maßnahmen auf der Grundlage von Erkenntnissen zu ergreifen, die nahezu in Echtzeit gewonnen wurden, was zu einer höheren Kundenzufriedenheit, besseren Prognosen und höheren Umsätzen führte.
Im zweiten Teil dieser Blogserie werde ich einige Best Practices zur Data Lake-Architektur und zum Aufbau eines Data Lake vorstellen. In der Zwischenzeit können Sie mehr darüber lesen, wie Sie mit denselben Technologien, die wir verwendet haben, Erkenntnisse aus Data Lakes gewinnen können.