






In meinem letzten Blogbeitrag habe ich den Prozess und die Schritte beschrieben, die SnapLogic befolgt hat, um datengesteuert zu werden, indem es einen internen Cloud Data Lake aufgebaut hat.
In diesem Blogbeitrag werde ich bewährte Verfahren für die Erstellung einer Data-Lake-Architektur, die für den Aufbau eines umfassenden Data Lake erforderlichen Tools und unsere Erfahrungen mit dem Aufbau unseres eigenen Data Lake vorstellen.
Der Prozess des Aufbaus einer Unternehmensdatenwolke
Für Unternehmen ist es unerlässlich, ihre aktuellen und zukünftigen Anforderungen zu verstehen, um die richtige Data-Lake-Lösung zu finden und den richtigen Data-Lake-Aufbau-Prozess zu befolgen. Bei SnapLogic haben wir fast vier Monate damit verbracht, unsere Cloud Data Lake-Lösung auf der Grundlage der folgenden Überlegungen zu entwickeln:
- Konzentrieren Sie sich auf Abfragefunktionen und nicht auf die Datenspeicherung. Einer der Hauptgründe für das Scheitern von Data Lakes ist, dass der Speicherung zu viel und den Abfragefunktionen zu wenig Bedeutung beigemessen wird.
- Durchsetzung eines "abfrageorientierten" Ansatzes. Wir erstellten Modelle auf der Grundlage dessen, was wir aus den ursprünglich ermittelten Quellen abfragen mussten, und eliminierten das Problem der Suche nach der Nadel im Heuhaufen.
- Identifizieren Sie die Personas, die den Data Lake nutzen werden, und kennen Sie die Art der Daten, nach denen sie suchen. Abfragen sind nicht generisch; es gibt verschiedene Personas, und sie sollten durch verschiedene Datenmodelle ergänzt werden.
Im Folgenden finden Sie einen Überblick über den Aufbau des Data Lake, einschließlich der Schritte, die wir zur Abfrage dieses Data Lake unternommen haben, um wichtige Geschäftskennzahlen zu generieren, damit verschiedene Teams entsprechende Maßnahmen ergreifen können.
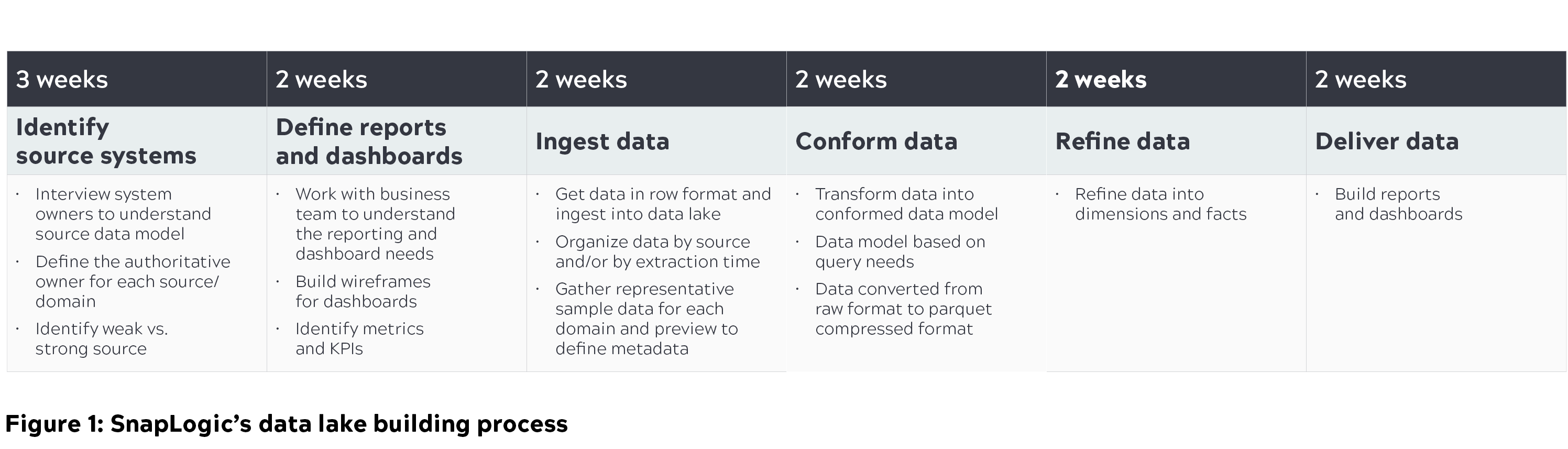
Architektur des Cloud Data Lake
Eine modulare, skalierbare und sichere Architektur mit hoher Leistung ist der Schlüssel zum Aufbau und zur Pflege eines Data Lakes in einem Unternehmen. Bei SnapLogic haben wir verschiedene Architekturdiskussionen darüber geführt, wie Data Lakes aufgebaut und skaliert werden können. Das folgende Diagramm erläutert die Basisarchitektur und unseren Gedankenprozess, wie wir uns einen skalierbaren Cloud Data Lake vorstellen.
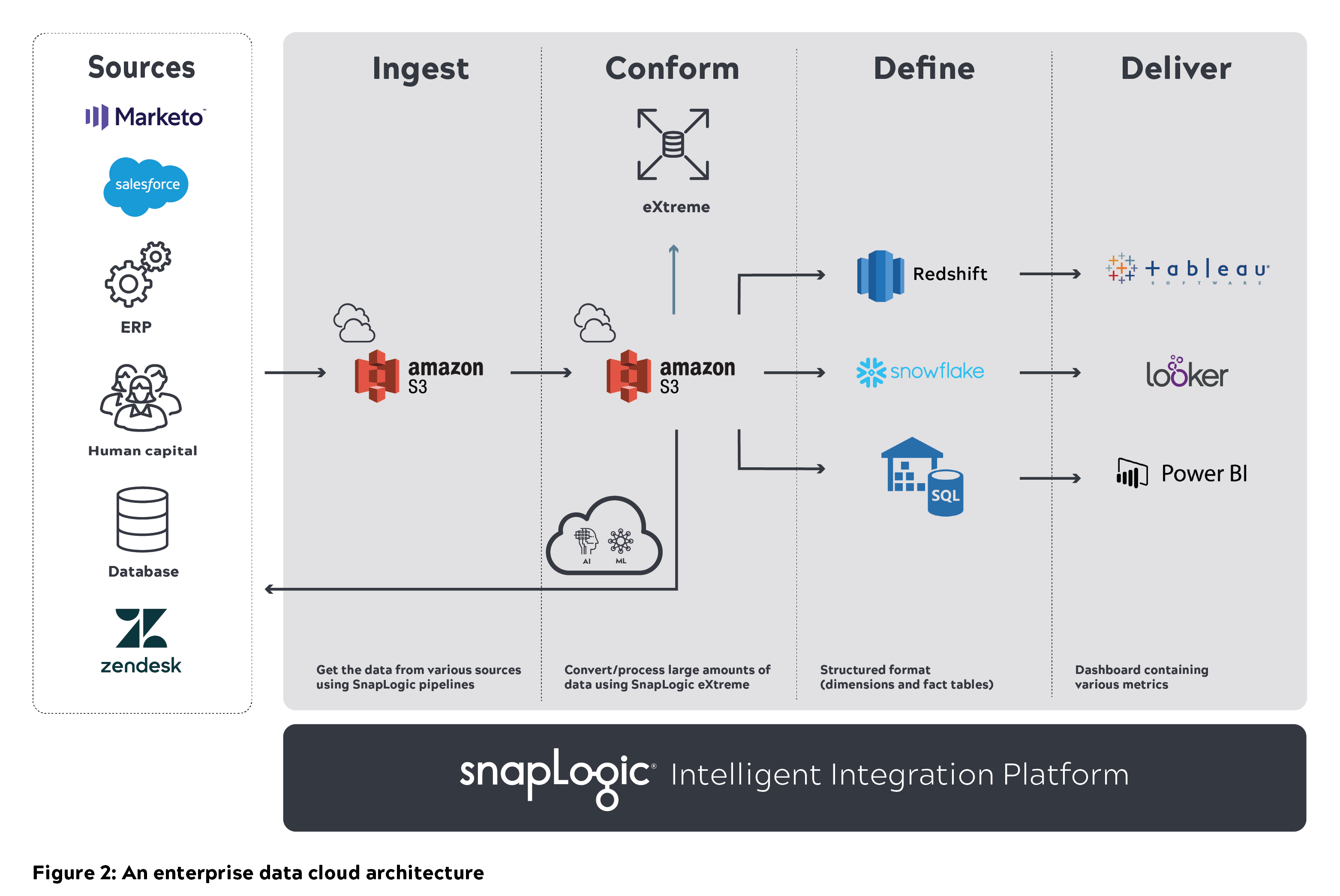
Eine generische Cloud-Data-Lake-Architektur besteht aus verschiedenen Datenquellen auf der linken Seite. Die Rohdaten aus diesen Systemen und Anwendungen werden in einen Data Lake (z. B. Amazon S3) eingespeist. Diese Daten müssen bereinigt und angepasst werden, damit Benutzer sie direkt abfragen können. Die verarbeiteten Daten werden später in einem Cloud Data Warehouse (z. B. Amazon Redshift, Snowflake oder Azure SQL Data Warehouse) gespeichert, das ebenfalls abgefragt werden kann. Der veredelte Datensatz kann später in BI-Tools wie Tableau, Looker oder Power BI eingepflegt werden.
Tools für den Aufbau des SnapLogic Data Lake:
- Amazon S3 zum Speichern aller Rohdaten
- SnapLogic Intelligent Integration Platform (IIP) für die Datenintegration und -verarbeitung
- Snowflake Data Warehouse zur Speicherung des verfeinerten Datensatzes
- Tableau für die Berichterstattung
Infrastruktur und Benutzerberechtigungen:
- Geben Sie den Benutzern den richtigen Zugang, um Geschäftslogik zu erstellen und Pipelines auszuführen
- Geben Sie Benutzern Zugriff auf IAM-Rollen für AWS-Umgebungen und rollenbasierten Zugriff für andere zu implementierende Umgebungen
SnapLogic Unternehmensdaten-Cloud-Architektur
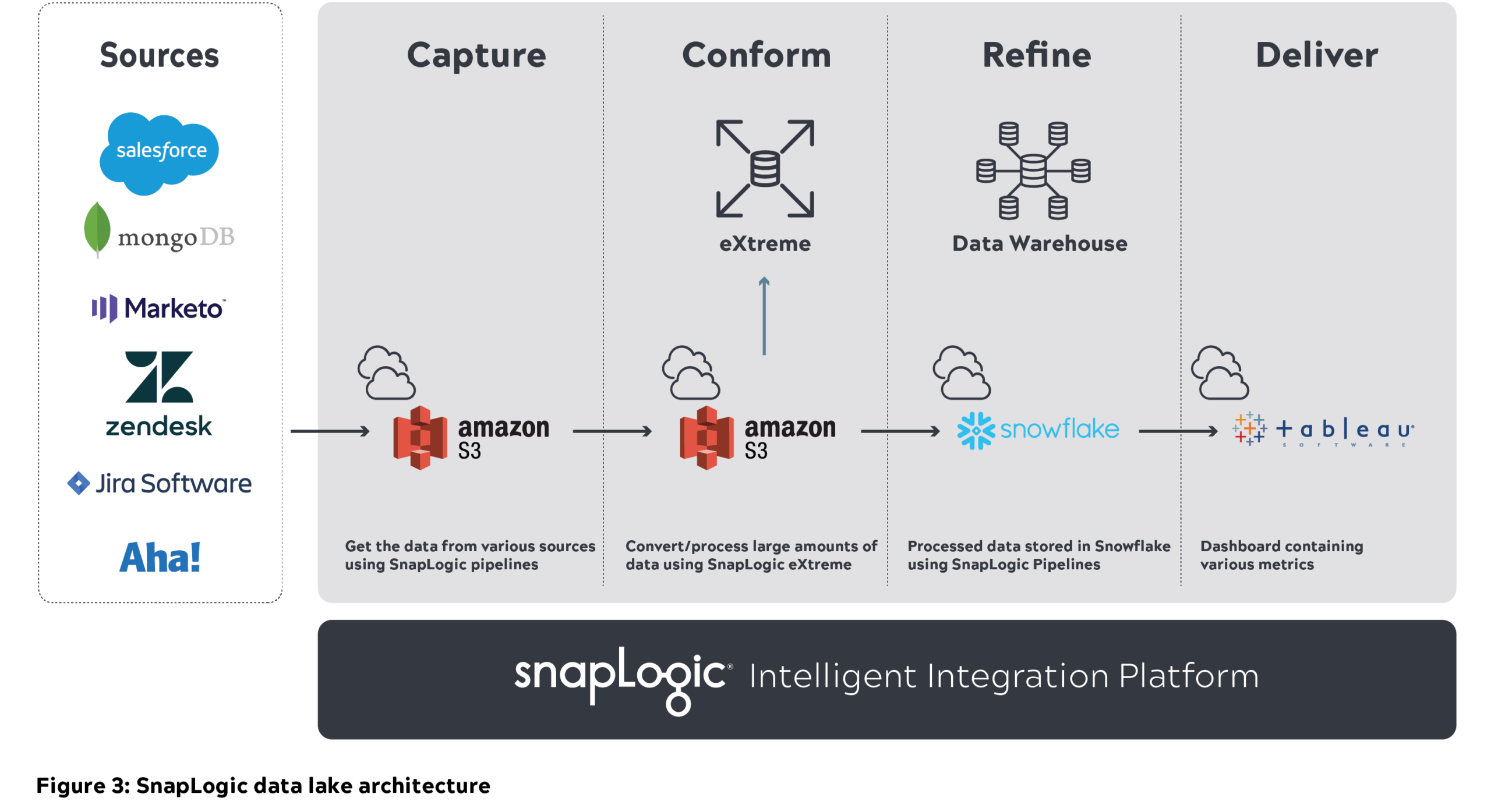
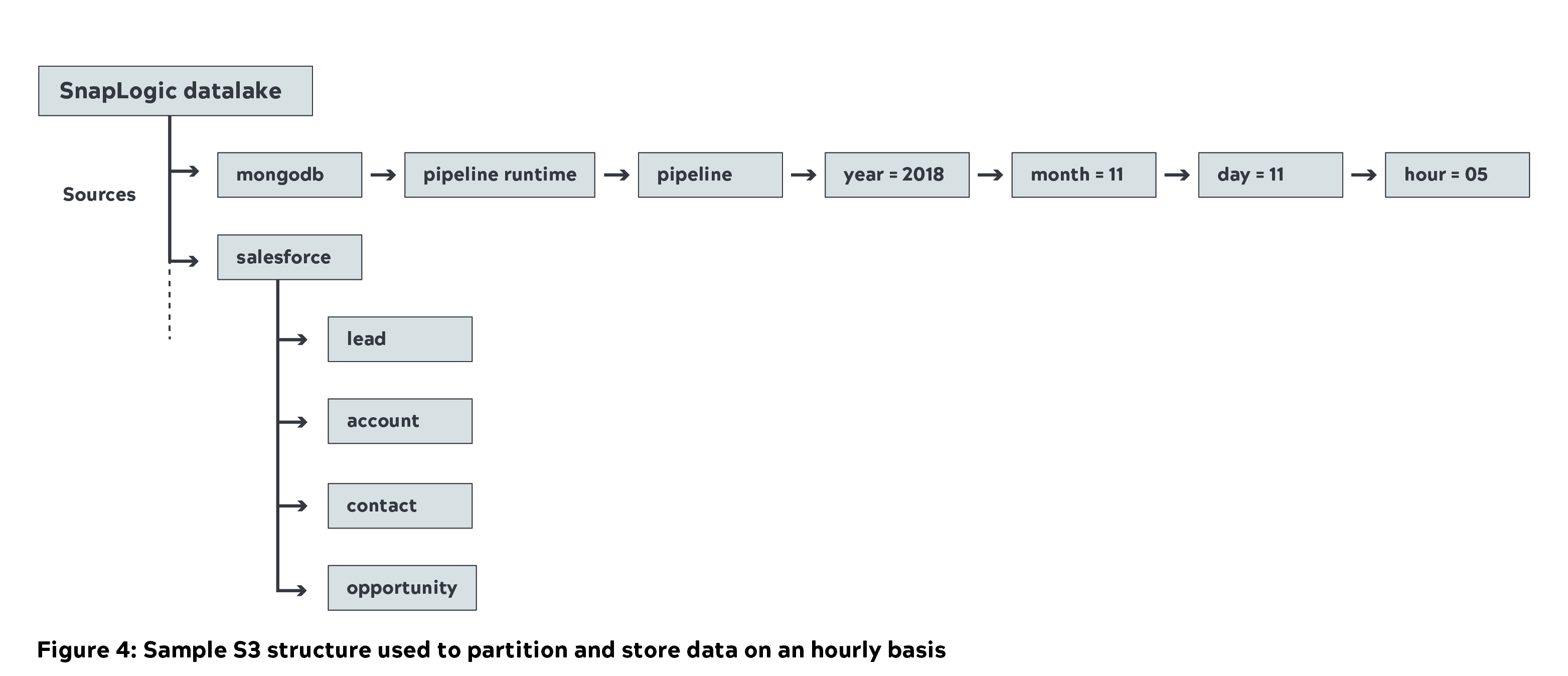
- Wir haben die einheitliche Integrationsplattform von SnapLogic verwendet, um fast 1 Petabyte (unkomprimiert) an Metadaten aus verschiedenen internen Quellen in den Amazon S3 Data Lake (Capture Layer) zu verschieben. Unten sehen Sie die Beispiel-S3-Struktur, die wir bei SnapLogic verwenden, in der die Quelldaten auf stündlicher Basis partitioniert und gespeichert werden.
- Die Bereinigung ist ein Zwischenschritt nach der Dateneingabe. Dabei werden doppelte und beschädigte Daten entfernt. SnapLogic-Pipelines halfen, diese doppelten Pipeline-IDs zu entfernen
- Später haben wir Big Data Snaps verwendet, um die Rohdaten in ein komprimiertes Parquet-Format als Teil der konformen Schicht zu konvertieren (eine Komprimierung von 70 % wurde erreicht). Nachfolgend sehen Sie ein Beispiel für eine S3-konforme Schicht und eine S3-Struktur

- Die Abfrage von Rohdaten und die Identifizierung des relevanten Datensatzes für Geschäftskennzahlen ist nicht einfach. Um dies zu erreichen und auch die Metadaten abzufragen, haben wir den Datenkatalog von SnapLogic verwendet.
- Außerdem haben wir den Benutzern die Möglichkeit gegeben, den angepassten Datensatz mit Amazon Athena abzufragen.
- SnapLogic eXtreme wird zur Verarbeitung von Big Data in der Cloud und zur Ableitung von Metriken (Pipeline/Snap-Ausführung und Dokumentenzahl) in Form einer Faktentabelle verwendet. Der Cluster ist auf 21 Knoten (m4,16x groß) skaliert, um die Arbeitslast zu verarbeiten.
- Snowflake wurde verwendet, um das Sternschema (Dimensionen und Faktentabellen) als Teil der Verfeinerungsschicht zu speichern. Wir verwendeten eine kleine Instanz zum Laden von Daten und eine mittlere Instanz zur Abfrage.
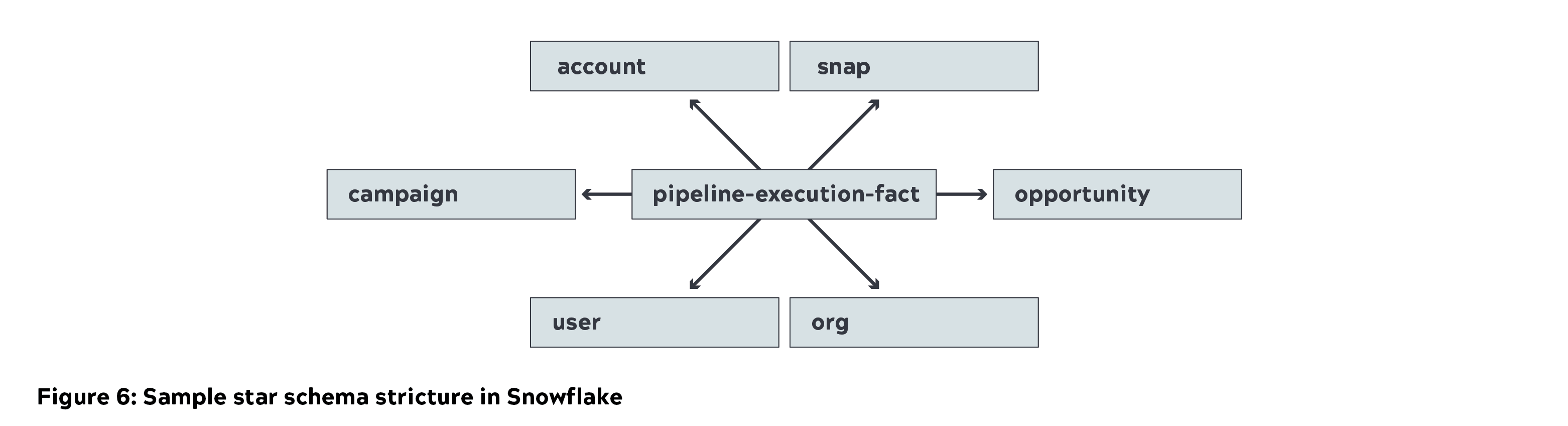
- Tableau wurde für die Erfassung und Visualisierung von Geschäftsmetriken verwendet. Die Daten wurden in Tableau zwischengespeichert, um wichtige Geschäftsmetriken zu generieren. Detaillierte Berichte wurden durch direkte Abfrage von Snowflake erstellt.
Prüfung
Die in S3 (Data Lake) empfangenen Daten sollten im Vergleich zu den Quelldaten konsistent sein. Diese erforderliche Prüfung muss regelmäßig durchgeführt werden, um sicherzustellen, dass keine fehlenden Werte oder Duplikate vorhanden sind.
- Wir haben eine automatisierte Pipeline entwickelt, um die Quelldaten mit den im Data Lake gespeicherten Daten abzugleichen (Einlesen, Anpassen und Verfeinern).
- Ein Tableau-Dashboard wurde entwickelt, um die Last der im Data Lake gespeicherten Daten nahezu in Echtzeit zu überwachen und zu prüfen.
- Wann immer doppelte oder beschädigte Daten gefunden wurden, alarmierten wir das Team, um sie zu korrigieren.
Herausforderungen und Lehren
Die Beschaffung von Daten aus verschiedenen Quellen - insbesondere von produktionsbezogenen Metadaten - war aufgrund des Umfangs und der Komplexität der Daten eine der größten Herausforderungen für uns. Darüber hinaus war es eine große Herausforderung, die Daten nahezu in Echtzeit für Analysen zur Verfügung zu stellen. Das SnapLogic Engineering Team war in der Lage, diese gewaltige Aufgabe zu bewältigen und uns produktionsbezogene Metadaten nahezu in Echtzeit zur Verfügung zu stellen.
Das Verständnis der Daten erforderte Zeit und Mühe, einschließlich der Einbringung der relevanten Datensätze für die Geschäftsmetriken. Ein Teil der Quelldaten war beschädigt, und wir mussten eine Pipeline-Logik entwickeln, um sie auszuschließen. Außerdem stellten wir doppelte Pipeline-IDs in der Quelle fest, was zusätzliche Bereinigungen in der konformen Schicht erforderte.
Die korrekte Modellierung von Daten ist wichtig, wobei ein effizientes Design darauf basiert, wie der Benutzer die Daten abfragen möchte. Dies muss berücksichtigt werden, und es müssen entsprechende Tabellen in Snowflake erstellt werden.
Das Sizing-Verfahren muss sorgfältig geplant und durchgeführt werden. Dies beinhaltet:
- SnapLogic-Knoten zur Verarbeitung großer Datenmengen (anfangs sehr speicher- und CPU-intensiv).
- Die Verarbeitung großer Datenmengen in der Cloud durch SnapLogic eXtreme erfordert EC2-Instanzen mit hohem Speicher- und CPU-Bedarf. Dies kann auch je nach Anwendungsfall und Datengröße variieren.
- Richtige Snowflake-Rechen- und Speicherzuweisung. Die Datenaufnahme erfordert anfangs eine mittlere bis große Instanz mit hoher Rechenleistung.
- Tableau-Daten, die für wichtige Geschäftsmetriken zwischengespeichert werden (Executive Dashboard und Berichte auf Zusammenfassungsebene). Detaillierte Berichte können direkt in Snowflake abgefragt werden.
Innerhalb weniger Monate konnten wir mit sorgfältiger Planung und Ausführung unter Verwendung wichtiger Plattformen wie AWS, SnapLogic, Snowflake und Tableau einen Data Lake aufbauen. Und wir freuen uns darauf, unsere Reise zum Data Lake mit anderen Unternehmen zu teilen. Wenn Sie mehr erfahren möchten, lesen Sie bitte unser Whitepaper "Easing the pain of big data: modern enterprise data architecture".






