






Die Fähigkeit, riesige Datenmengen zu verwalten, ist für den Erfolg eines jeden Unternehmens entscheidend, obwohl die meisten hinter der Entwicklung zurückbleiben und Schwierigkeiten haben, datengesteuerte Ergebnisse zu erzielen. Selbst wenn eine große Menge an Daten zur Verfügung steht, haben laut einem im Mai 2017 in der Harvard Business Review veröffentlichten Artikel "mehr als 70 % der Mitarbeiter Zugang zu Daten, die sie nicht haben sollten, und 80 % der Zeit von Analysten wird mit dem bloßen Entdecken und Aufbereiten von Daten verbracht".
Wo kommt das maschinelle Lernen ins Spiel? Als der Bedarf an besseren Erkenntnissen aus Daten explodierte, sprachen wir mit Kunden, die Hilfe beim maschinellen Lernen suchten, und stellten fest, dass ihre Dateningenieure 70 bis 80 Prozent ihrer Zeit mit der Datenerfassung, der Datenexploration und der Datenaufbereitung im Rahmen des Lebenszyklus des maschinellen Lernens verbringen. Wir hörten auch von einem Mangel an Data-Science-Experten und nicht sehr hilfreichen, nicht integrierten und unhandlichen Datenaufbereitungstools. Wir kamen zu dem Schluss, dass maschinelles Lernen (ML) in Wirklichkeit ein Integrationsproblem ist, was SnapLogic zu einer natürlichen Plattform für ML macht. Deshalb haben wir im November SnapLogic Data Science eingeführt, um den gesamten Lebenszyklus des maschinellen Lernens zu verwalten und zu steuern.
In diesem Blog-Beitrag gehen wir einige der Funktionen des SnapLogic Data Science-Angebots durch und zeigen Ihnen, wie Datenaufbereitung und maschinelles Lernen einfach, unterhaltsam und unkompliziert sein können. Sie können auch in SnapLogic mitmachen , indem Sie sich für eine kostenlose 30-Tage-Testversion anmelden.
Eine neue Self-Service-Lösung für maschinelles Lernen
SnapLogic Data Science - unsere neueste Version als Erweiterung der intelligenten Integrationsplattform von SnapLogic - ist eine neue Self-Service-Lösung, die die Entwicklung und den Einsatz von maschinellem Lernen mit minimalem Programmieraufwand über den gesamten Lebenszyklus des maschinellen Lernens beschleunigt (siehe unten).
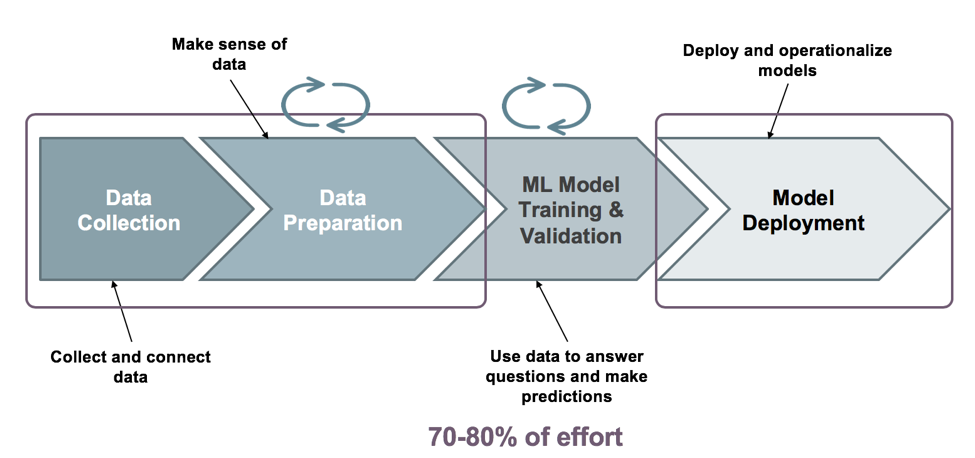
Datenerhebung und -aufbereitung
Schauen wir uns die Datenerfassung und -aufbereitung sowie die Funktionen an, die SnapLogic Data Science für diesen ML-Bucket bietet. Hier greift ein Data Engineer auf die Daten zu und stellt sie für die Verwendung durch Machine Learning-Modelle zusammen und führt das Feature Engineering durch. Sie können auch vorbereitende Operationen an Datensätzen durchführen, wie z. B. Datentypumwandlung, Datenbereinigung, Sampling, Shuffling und Skalierung. Durch diese Funktionen wird Redundanz bei der Datenvorbereitung vermieden, die manchmal durch eine Trennung zwischen Data Science- und IT/DevOps-Teams entsteht.
Das SnapLogic Data Science-Angebot umfasst drei Snap Packs - das ML Data Preparation Snap Pack, das ML Core Snap Pack und das ML Analytics Snap Pack zur Unterstützung der Datenerfassung und -aufbereitung.
- Das ML Data Preparation Snap Pack ermöglicht es Data Engineers und Data Scientists, vorbereitende Operationen an Datensätzen durchzuführen, wie z. B. Datentypumwandlung, Datenbereinigung, Sampling, Shuffling und Skalierung. Es bietet wichtige Snaps wie den Clean Missing Values Snap, der fehlende Werte in Datensätzen durch Weglassen oder Imputieren von Werten ersetzt. Außerdem gibt es den Date Time Extractor Snap, der Komponenten aus Datetime-Objekten extrahiert, die in Ergebnisfelder für weitere Analysen eingefügt werden können. Der Stichproben-Snap hilft bei der Erstellung von Stichproben-Datensätzen aus einem Eingabedatensatz unter Verwendung verschiedener Arten von Stichprobenalgorithmen wie Stratified Sampling, Weighted Stratified Sampling usw. Der Skalierungs-Snap hilft bei der Skalierung von Werten in Spalten, um Bereiche festzulegen oder statistische Transformationen anzuwenden. Mit dem Shuffle-Snap wird die Reihenfolge der Zeilendaten im Dataset randomisiert.
- Das ML Core Snap Pack ermöglicht Dateningenieuren die Durchführung von Operationen mit Machine-Learning-Datensätzen, wie z. B. Modelltraining, Kreuzvalidierung und modellbasierte Vorhersagen.
- Das ML Analytics Snap Pack unterstützt Dateningenieure bei der Durchführung von Analysevorgängen wie der Erstellung von Datenprofilen und der Überprüfung von Datentypen.
Das folgende Beispiel zeigt, wie der Snap "Fehlende Werte bereinigen" in einer Pipeline für die Datenaufbereitung verwendet werden kann. Der Snap "Fehlende Werte bereinigen" ist ein Snap des Typs "Transformieren", der dazu dient, fehlende Werte in einem eingehenden Datensatz durch Weglassen oder Imputieren von Werten zu behandeln, und unterstützt vier Ansätze: Zeile verwerfen, mit Durchschnitt imputieren, mit Popular imputieren und mit benutzerdefiniertem Wert imputieren.
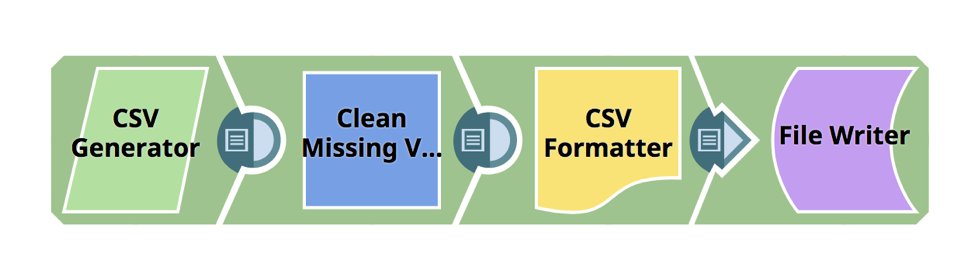
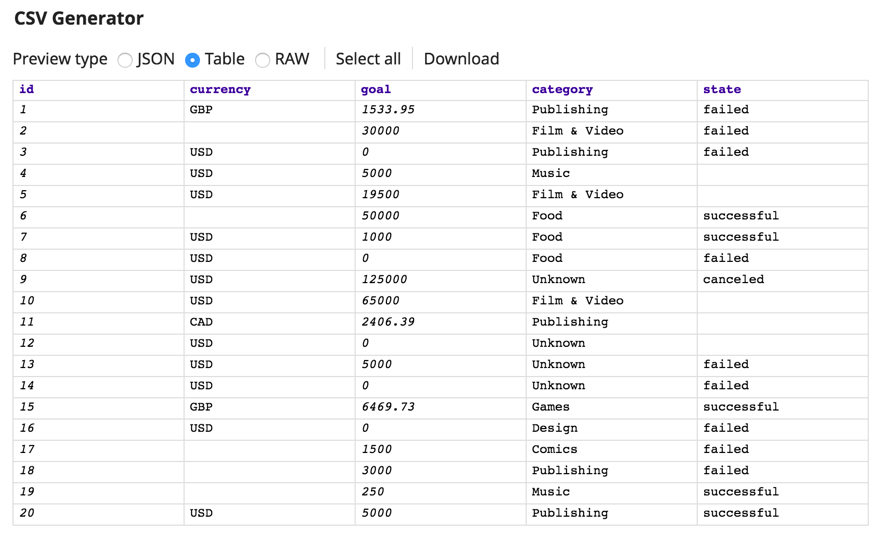
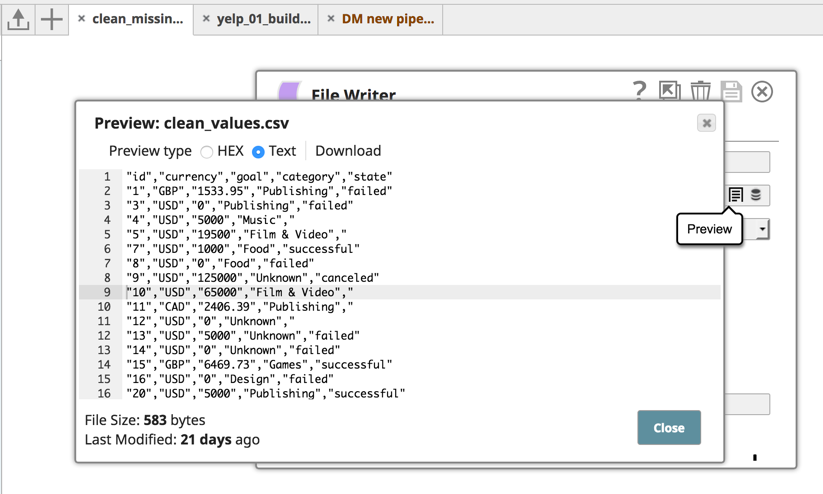
Zunächst haben wir mit dem CSV-Generator Snap eine einfache CSV-Datei, in der die Werte für die Währung fehlen - das sehen Sie in der dritten Zeile.
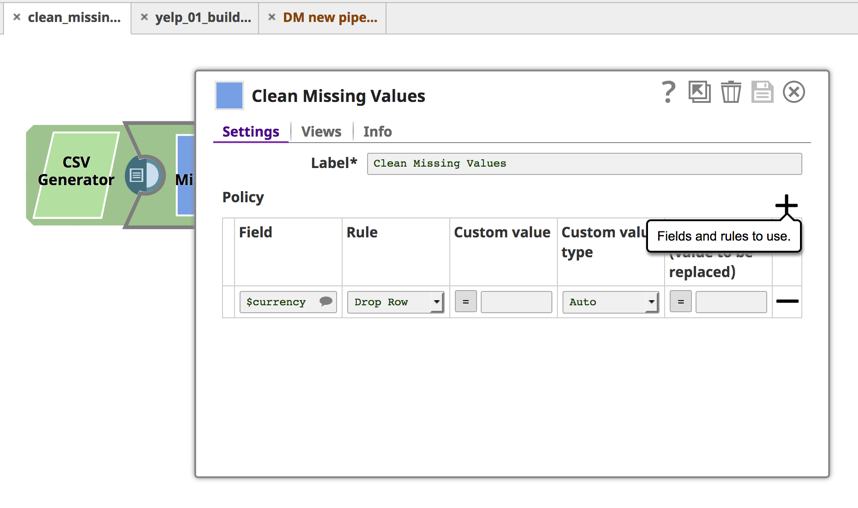
Mit dem nächsten Snap in der Pipeline, Fehlende Werte bereinigen, können Sie eine Regel definieren, die die Zeile fallen lässt, wenn der Währungswert null ist.
Wenn ich die Pipeline ausführe, zeigt der unten stehende Screenshot, wie die bereinigte Datei aussieht. Sie sehen, dass die Zeile gezielt gelöscht wurde und die Datei jetzt bereinigt ist.
Sobald die Daten bereinigt sind, können Sie den Profil-Snap verwenden, um die Daten zu profilieren und Statistiken über die eingehenden Daten zu erstellen.
Hier sehen Sie eine Pipeline, die diesen Teil des Prozesses zeigt.

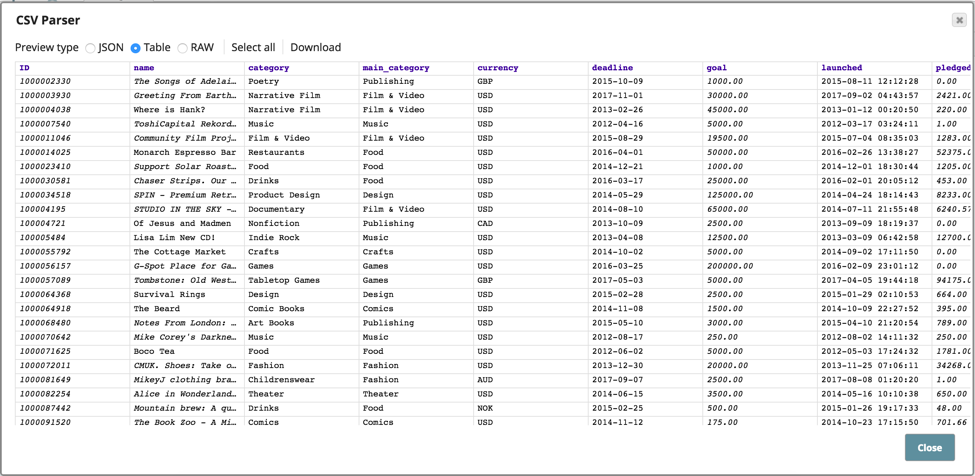
Wenn Sie sich die Datei ansehen, in der verschiedene Arten von Assets gespeichert werden, können Sie erkennen, wie die Quelldaten strukturiert sind.
Die oben gezeigte Pipeline wurde eingerichtet, um die CSV-Daten zu analysieren und zu profilieren und dann die Profilausgabe in eine JSON-Ausgabedatei zu schreiben. So sieht die Profilausgabe mit der Werteverteilung usw. aus.
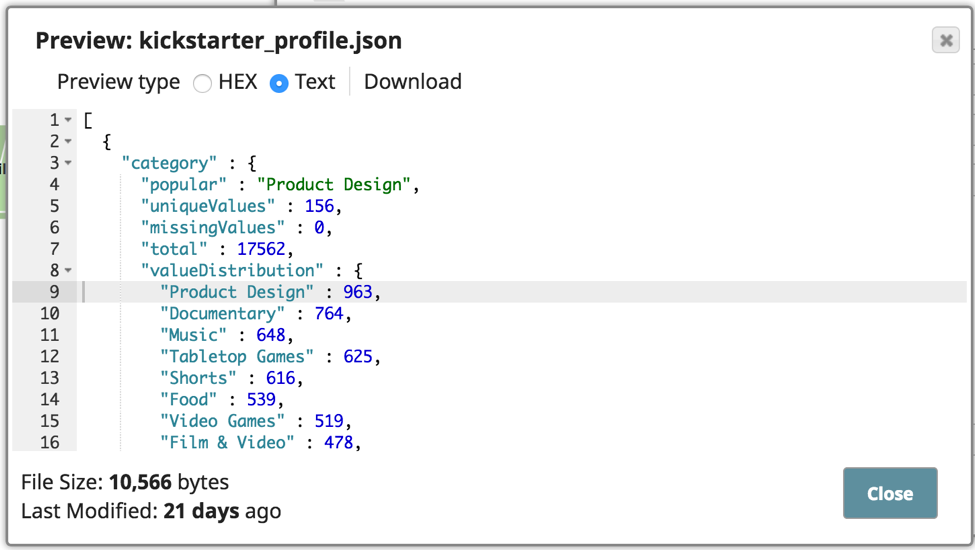
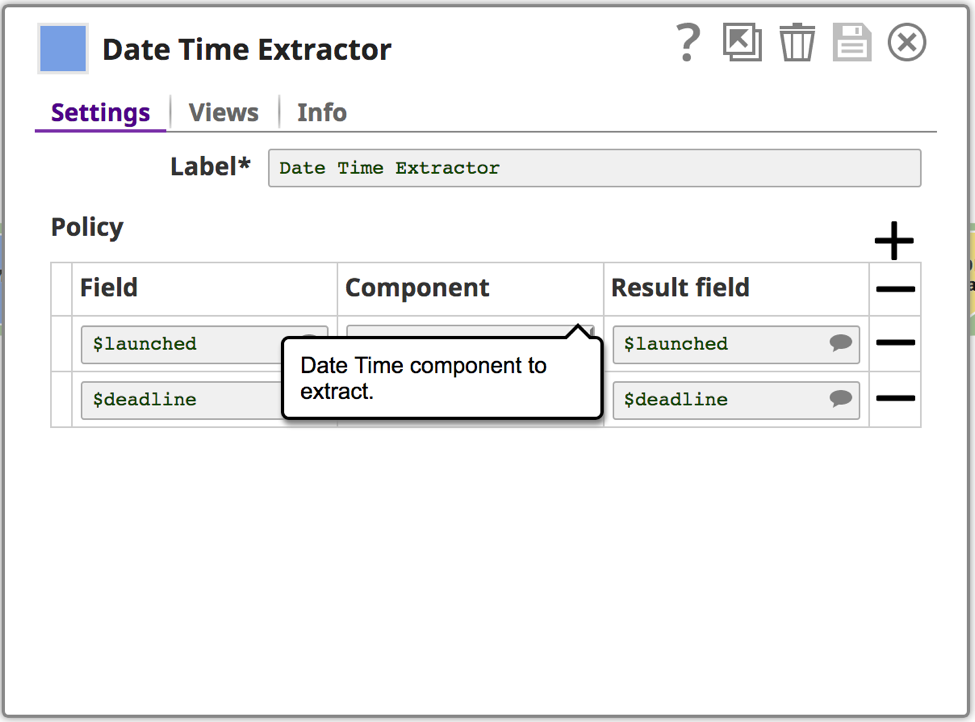
Auf diese Weise lässt sich feststellen, welche weiteren Datenbereinigungen vorgenommen werden müssen. Außerdem verwende ich den Date Extractor Snap, einen Snap des Typs Transform, der Komponenten aus Datumsdaten extrahiert und sie dem Ergebnisfeld hinzufügt. In diesem Fall extrahiere ich den Epochenwert in das Ergebnisfeld. Sie können den Snap verwenden, um die Daten vor der Aggregation oder Analyse vorzubereiten.
Befähigen Sie den Datenwissenschaftler in Ihnen
Ich hoffe, diese kurze Schritt-für-Schritt-Anleitung von SnapLogic Data Science zeigt, dass die Durchführung von Datenvorbereitungsaufgaben sowohl Spaß machen als auch einfach sein kann. Jetzt können Datenwissenschaftler schneller als bisher mit der Problemanalyse und der Erstellung ML-basierter Modelle beginnen. Und Dateningenieure können die Daten in einem Self-Service-Verfahren aufbereiten, indem sie sie aus verschiedenen Quellen integrieren und in eine nutzbare Form bringen.
Sie glauben mir nicht? Melden Sie sich für die kostenlose 30-Tage-Testversion an.







