






Im ersten Artikel dieser zweiteiligen Serie habe ich drei von fünf Möglichkeiten aufgezeigt, wie Sie Ihre moderne Datenarchitektur moderner gestalten können. Aber nicht nur moderner, sondern auch weniger komplex.
Zusammenfassung der drei Fähigkeiten (wie in Teil 1 zusammengefasst), auf die Sie achten sollten:
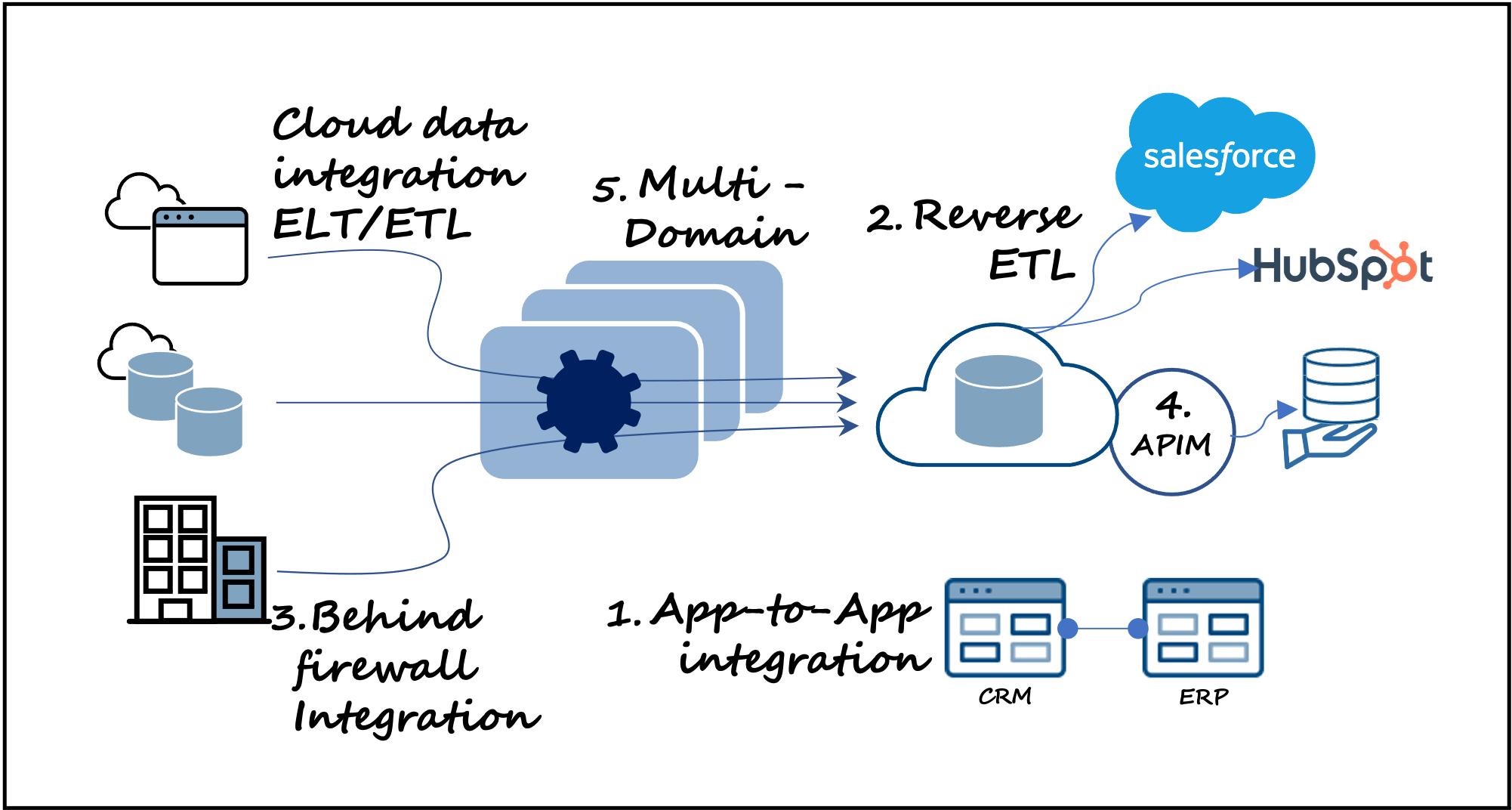
1. Datenintegration und App-zu-App-Integration kombiniert
Die Übertragung von Cloud-Daten (ELT oder ETL) in ein Cloud-Data-Warehouse wie BigQuery, Redshift, Snowflake oder andere (mit Tools wie Fivetran, Matillion, Informatica usw.) eignet sich hervorragend für Analysen und Einblicke nach der Produktion und ist ein dominanter Anwendungsfall. Die Datenintegration an sich ist jedoch potenziell einschränkend. Eine modernere Fähigkeit besteht darin, innerhalb desselben Tools die Flexibilität zu haben, Daten zwischen Anwendungen für operative Arbeitslasten zu integrieren, insbesondere wenn Echtzeitleistung erforderlich ist. Im Vergleich zum Zugriff auf Daten über ein Data Warehouse können In-App-Datenerfahrungen zudem schneller und einfacher für eine breitere Basis von Nutzern sein.
2. Bidirektionale Lademuster (ETL, ELT und Reverse ETL) - Unkompliziert
Neben der Ausweitung auf App-to-App-Integrationen ist die Kombination von ETL und ELT mit Reverse-ETL-Mustern, wiederum in einer Lösung, ein modernerer Ansatz, der (im Vergleich zu Tools wie Census, Hightouch, Hevo usw.) die Flexibilität bietet, ein für Ihren spezifischen Anwendungsfall am besten geeignetes Lademuster auszuwählen. Der zusätzliche Vorteil ist die Toolkonsolidierung, wodurch Ihre Datenarchitektur vereinfacht wird.
3. Verarbeiten Sie sowohl vor Ort als auch in der Cloud gespeicherte Daten, ohne die Sicherheit zu beeinträchtigen
Daten, die in der Cloud gespeichert sind, liegen im Trend, aber für einige sicherheits- oder datenschutzsensible Unternehmen werden Daten vor Ort nicht in die Nähe einer Cloud gelangen (aus welchen Gründen auch immer). Eine modernere Lösung trennt die Datenausführung von der Datenkontrolle und ermöglicht es, dass Ihre Daten oder App-to-App-Integrationen auf einer beliebigen Infrastruktur an einem beliebigen Ort ausgeführt werden können, auch hinter einer lokalen Firewall, während Sie die flexible und flexible Cloud-Kontrolle beibehalten.
Nun zu den beiden anderen, moderneren Fähigkeiten:
4. Daten + App-to-App-Integrationen + APIs für eine modernere Dev/Ops-Erfahrung mit Datendiensten
Datenprodukte und Datendienste sind heutzutage in aller Munde. Betrachtet man jedoch noch einmal (wie in Teil 1 beschrieben) die Aufmerksamkeit, die Data Mesh und die Data Mesh-Prinzipien (domäneneigene Daten, Daten als Produkt, Self-Service-Datenarchitektur und föderierte Computer-Governance) erlangt haben, so gibt es eine Überschneidung vieler Technologien, darunter Integration und API-Management, um Data Mesh zu ermöglichen. Hinzu kommt die Bereitstellung von Datendiensten, die im Allgemeinen die Entwicklung, Bereitstellung und Verwaltung von APIs erfordert.
Die API-gesteuerte Kultur (mit Lösungen wie Apigee, Kong usw.) ist schon seit einiger Zeit ein Thema - aus der Perspektive der Anwendungsentwicklung und Softwareentwicklung. Aus dem Blickwinkel der Datenarchitektur - ob Daten nun an Ort und Stelle bleiben oder ob Pipelines für den Datenfluss gebaut werden - haben Datenprodukte, -dienste und -pipelines jedoch ihre eigenen Entwicklungsprozesse. Aus diesem Grund würde die Entwicklung von Datenprodukten, -diensten und -pipelines von den Best Practices der Anwendungsentwicklung profitieren, insbesondere von Continuous Integration and Continuous Delivery (CI/CD) und Dev-Ops.
Wenn also Integration, Domäneneigentum, Entwicklung und Betrieb von Datenprodukten, Bereitstellung von Datendiensten und APIs eine wichtige Schnittmenge bilden, dann wird die Kombination möglichst vieler dieser Funktionen in einer einzigen Plattformlösung - die auch auf Selbstbedienung ausgerichtet ist - Vorteile bei der Konsolidierung und Vereinfachung bringen. Außerdem werden sowohl technisch versierte als auch nicht technisch versierte Benutzer eine modernere, integrierte Entwicklungserfahrung machen.
"Durch die Nutzung von SnapLogic für den Aufbau unserer KI-gestützten Plattform können wir unser Unternehmen unterstützen und unseren Mitarbeitern den Zugang zu den Daten ermöglichen, die sie benötigen, und zwar auf Knopfdruck. Mehr als 95 % aller unserer APIs werden von SnapLogic orchestriert, so dass unsere Mitarbeiter problemlos Anwendungen auf der Grundlage unserer Marko-Datenplattform erstellen können", so Brian Murphy, VP of Data beim Lebensmitteldienstleister Aramark.
5. Eine skalierbare Integrationsarchitektur von A bis Z
Wenn Sie eine Umgebung haben, die mehr als eine Domäne unterstützen muss - z. B. mehrere Niederlassungen, verschiedene Geschäftseinheiten, mehrere funktionale Teams usw. -, dann muss das Integrations-Backbone, das alles zusammenführt, skalierbar sein, um neue Domänen aufnehmen zu können.
Technisch gesehen können Sie natürlich für jeden neuen Bereich eine neue Datenarchitektur einrichten, aber das würde zu harten Grenzen und zusätzlicher Komplexität führen. Auch wenn dies manchmal notwendig sein mag, ist es besser, die Komplexität zu vermeiden, wenn man die Wahl hat. Ein modernerer Ansatz besteht daher darin, Flexibilität und Wahlmöglichkeiten in Ihre Architektur einzubauen, und zwar mit einem Integrations-Backbone, das horizontal (X-Achse) durch Hinzufügen weiterer Rechenknoten skaliert werden kann, vertikal (Y-Achse) durch Vergrößerung eines Rechenknotens oder in die Breite (Z-Achse) durch Hinzufügen weiterer Domänen (Abbildung 1). Alle Domänen wären innerhalb derselben Integrationsumgebung lose miteinander gekoppelt.
Darüber hinaus würde jeder Bereich über eigene Ressourcen verfügen, während die Kontrolle und Verwaltung der gesamten integrierten Umgebung entweder von den Geschäftsgruppen oder von der IT übernommen und verwaltet werden könnte. Flexibilität ist der Schlüssel, da Unternehmen zunehmend IT-ähnliche Technologen in Geschäftsgruppen unterbringen. Für eine solche verteilte Umgebung wäre es auch ideal, Aktivitätsmetadaten in der gesamten Umgebung zu sammeln, um die Governance zu fördern und Sicherheitsrichtlinien durchzusetzen. Metadaten und Governance sind ein eigenständiges Thema für einen zukünftigen Artikel. Bleiben Sie dran.
Moderner + weniger komplex = einfacheres Leben mit Daten
In dieser zweiteiligen Artikelserie habe ich zusammengefasst, wie die Datenintegration (in einem Cloud Data Warehouse konsolidierte Datenquellen) im Mittelpunkt der meisten Diskussionen über moderne Datenarchitekturen und moderne Datenstapel steht. Wenn ich jedoch das Privileg habe, mit Technologiemanagern der IT- und Geschäftsbereiche, Unternehmensarchitekten und Datenplattformmanagern zu sprechen, wird häufig die Sorge geäußert, dass Datenarchitekturen zu komplex und zu technisch sind, um Personen außerhalb der IT-Abteilung in die Lage zu versetzen, Daten zu integrieren und damit zu arbeiten.
Ein wichtiger Faktor ist das Vorhandensein mehrerer, sich überschneidender Tools zur Bewältigung umfassenderer Datenaufgaben, die einen Ausgleich für Tools darstellen, die nur auf ELT oder ETL oder nur auf Reverse ETL ausgerichtet sind.
Datenintegration (ELT, ETL und Reverse ETL), App-to-App-Integration und API-Verwaltung über den gesamten Lebenszyklus hinweg machen Ihre gesamte Datenarchitektur moderner (und funktionaler), aber auch weniger komplex und einfacher für ein breiteres Spektrum von Dateneigentümern und -nutzern, wenn sie in einer einzigen Integrationsplattform zusammengefasst sind. Dies gilt auch für Benutzer außerhalb der IT-Abteilung. Ein Bonus ist, wenn eine solche konsolidierte, einheitliche Lösung es Ihnen auch ermöglicht, die Kontrolle in der Cloud von der Ausführung vor Ort (hinter einer Firewall) zu trennen, und es Ihnen erlaubt, vertikal, horizontal oder breit zu skalieren, um Leistungsanforderungen zu erfüllen und Domänen hinzuzufügen.







