






Daten werden zunehmend als die Unternehmenswährung des digitalen Zeitalters erkannt. Unternehmen wollen Daten nutzen, um tiefere Einblicke zu gewinnen, die ihnen einen Wettbewerbsvorteil gegenüber ihren Konkurrenten verschaffen. Laut IDC-Prognosen wird die weltweite Gesamtdatenmenge bis 2025 auf 163 Zettabyte (ZB) ansteigen, was einer Verzehnfachung der heutigen Datenmenge entspricht. Diese potenzielle digitale Datengoldmine wird eine neue Ära der Innovation einleiten, zusätzliche Einnahmequellen erschließen, Produkte der nächsten Generation ermöglichen und Unternehmen Einblicke geben, die ihnen helfen, ihre Effizienz und Produktivität zu steigern. Diese Datenexplosion hat Unternehmen dazu veranlasst, über die Welt des traditionellen Data Warehousing hinauszugehen und zu erforschen, wie sie erfolgreich Data Lakes in der Cloud aufbauen können, um Zugang zu Daten zu erhalten und diese zu analysieren, an die sie in der Vergangenheit nicht herankommen konnten.
Der Schlüssel zur Innovation ist das Datenmanagement
Der Schlüssel zur Erschließung all dieser datengesteuerten Innovationen liegt in der Art und Weise, wie Daten erfasst, verarbeitet, verwaltet und analysiert werden. Angesichts der heutigen Datenmenge, -vielfalt und -geschwindigkeit ist es jedoch fast unmöglich, das Data Warehouse des Unternehmens zum Mittelpunkt einer Datenarchitektur zu machen. Das Enterprise Data Warehouse hat einfach nicht die Skalierbarkeit oder die Leistungsmerkmale, um die Flut an strukturierten und unstrukturierten Informationen zu bewältigen, die aus bestehenden Unternehmensanwendungen stammen und aus Echtzeitquellen wie Sensoren, Videos, Weblogs und dem Internet der Dinge (IoT) einströmen. Ein Data Warehouse kann zwar unstrukturierte Daten verarbeiten, aber nicht auf die effizienteste Art und Weise. Bei der großen Menge an Daten, die es gibt, kann es sehr teuer werden, alle Daten in einem herkömmlichen Data Warehouse zu speichern. Ein Data Lake ist ein Ort, an dem Sie Ihre strukturierten und unstrukturierten Daten speichern können, sowie eine Methode zur Organisation großer Mengen unterschiedlichster Daten aus verschiedenen Quellen. Der Data Lake nimmt die Daten sehr schnell auf und bereitet sie später auf, wenn die Benutzer auf sie zugreifen.
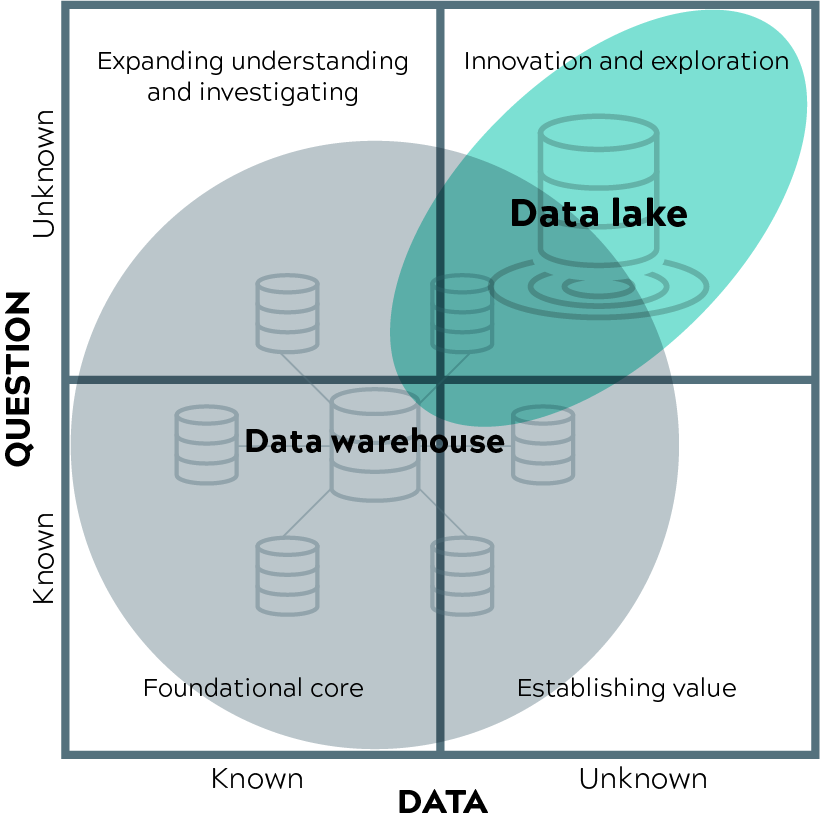
Hier ist ein von Gartner inspirierter Rahmen, um darüber nachzudenken, wo ein traditionelles Data Warehouse oder ein Data Lake am sinnvollsten ist. Es hängt davon ab, ob Sie wissen, was Sie brauchen und ob die benötigten Daten bekannt sind oder nicht.
Wie stellen Sie fest, ob ein Data Lake die Herausforderungen der Datenverwaltung in Ihrem Unternehmen bewältigen kann, und wie bereiten Sie sich darauf vor, wenn dies tatsächlich der Fall sein sollte? Hier sind fünf Fragen, die Sie im Auge behalten sollten:
Wie setzt sich der Datenmix zusammen? Wenn die Geschäftsanforderungen eines Unternehmens durch die Aggregation und Analyse von tabellarischen, meist strukturierten Informationen erfüllt werden, die in transaktionsbasierten Systemen wie Enterprise Resource Planning (ERP) gespeichert sind, sind traditionelle Data Warehouses wahrscheinlich immer noch der beste Ansatz. Wenn der Datenmix jedoch beginnt, unstrukturiertes oder sogar halbstrukturiertes Material zu umfassen, und vor allem, wenn sich die Daten schnell ansammeln - denken Sie an Echtzeit- und Streaming-Daten -, dann sollte ein Data Lake als wirtschaftlichere Methode zur Bewältigung des Datenvolumens in großem Umfang in Betracht gezogen werden.
Gibt es eine klar definierte Strategie für den Data Lake? Ein großer Teil des Reizes eines Data Lake liegt in seinem nahezu unstillbaren Appetit auf die Aufnahme aller Arten von Daten und in der Flexibilität, die Sie für die spätere Nutzung aufbewahren können, ohne unbedingt zu wissen, was Sie damit tun wollen. Gleichzeitig können IT-Organisationen ohne eine Strategie, die im Vorfeld festlegt, woher die Daten stammen, wem sie dienen und wie sie verwaltet werden, wieder dort landen, wo sie angefangen haben: Sie sitzen auf einer Reihe von isolierten Systemen, die den Anforderungen des Unternehmens nicht gerecht werden und sich nicht effektiv skalieren lassen.
Haben Sie Zugang zu Big-Data-Kenntnissen? In Unternehmen gibt es viele Data-Warehouse-Experten und Unternehmensanalysten, die nicht unbedingt mit dem Big-Data-Universum vertraut sind, insbesondere mit Data Lakes. Die Vertrautheit mit neuen Open-Source-Technologien wie Hadoop, MapReduce, Flink, Flume, Kafka oder Spark ist jetzt von entscheidender Bedeutung, ebenso wie der Bedarf an Dateningenieuren, die in der Lage sind, Code zu schreiben, um Daten in großem Umfang mit Programmiersprachen wie Scala, Java und Python zu verarbeiten. Darüber hinaus werden Datenwissenschaftler benötigt, die Programmiersprachen wie Python und R nutzen können, um Daten aufzubereiten und Analysemodelle zu erstellen, die tiefere Einblicke ermöglichen. Zusätzlich zu diesen neuen Techniken und Tools müssen Unternehmen auch ihre Datenverwaltungspraktiken neu ausrichten und agile Methoden anwenden, um die Vorteile einer Data Lake-Architektur zu maximieren.
Welche zeitlichen Beschränkungen sollten berücksichtigt werden? Daten, die in ein Enterprise Data Warehouse eingespeist werden, müssen bereinigt und aufbereitet werden, bevor sie gespeichert werden können. Da die heutigen unstrukturierten Daten in verschiedenen Rohformaten in rasantem Tempo generiert werden, kann es ein mühsamer Prozess sein, die Bereinigungs- und Aufbereitungsphasen zu erreichen, wenn man noch nicht einmal ganz sicher ist, wie die Daten verwendet werden sollen. Der Data Lake ist darauf ausgelegt, unstrukturierte Daten auf möglichst kosteneffiziente Weise zu verarbeiten, wobei die Rechen- und Speicherebenen unabhängig voneinander auf elastische Weise skaliert werden können. Mit einem Data Lake-Ansatz können die Benutzer ihre Daten so schnell wie möglich einspeisen, so dass sie betriebliche Anwendungsfälle wie betriebliche Berichte, Analysen und Geschäftsüberwachung angehen können.
Wie werden Sie die Anforderungen an die Datenintegration erfüllen? In einem Bericht von Cap Gemini über den Nutzen von Big Data wurden Integrationsprobleme als eines der größten Hindernisse für den Erfolg von Big Data genannt (von 35 Prozent der Befragten). In einem anderen Bericht von TDWI wurde festgestellt, dass das Fehlen von Datenintegrationstools für 32 Prozent der Befragten ein Hindernis für eine erfolgreiche Data Lake-Implementierung darstellt. Bevor es losgehen kann, muss eine Roadmap für die Datenerfassung und -integration erstellt werden, die optimal auf das neue Paradigma abgestimmt ist.
Das Enterprise Data Warehouse wird auch weiterhin eine wichtige Komponente einer modernen Unternehmensdatenarchitektur (MEDA) bleiben , aber es sollte jetzt als eine "nachgelagerte" Anwendung betrachtet werden, als Ziel, aber nicht als Zentrum Ihres Datenuniversums. Data Lakes sind zwar kein Allheilmittel, haben aber ein enormes Potenzial, nicht nur einem breiteren Publikum den Zugang zu Daten zu ermöglichen, an die es in der Vergangenheit nicht herankam, sondern dies auch auf kostengünstige Weise zu unterstützen. Es reicht nicht aus, auf den neuesten Hightech-Zug aufzuspringen - stellen Sie vielmehr die richtigen Fragen und gehen Sie alle Überlegungen durch, um sicherzustellen, dass ein Data Lake der richtige Ansatz für die Datenanforderungen Ihres Unternehmens ist.






