






Da unsere Kunden zunehmend die Möglichkeiten des GenAI App Builders erkunden, ist eine häufige Frage aufgetaucht: Wie können wir die Qualität der von großen Sprachmodellen (LLMs) erzeugten Ergebnisse bewerten? Um diese Frage zu beantworten, haben wir die Evaluierungspipeline des GenAI App Builders entwickelt, eine neue Ergänzung unserer öffentlichen Musterbibliothek, die die generative Qualität dieser Modelle auf systematische und zuverlässige Weise bewerten soll.
Einführung in den GenAI App Builder
GenAI App Builder ist ein innovatives Tool, das die Erstellung fortschrittlicher Anwendungen ermöglicht, die die Leistung der generativen KI nutzen. Mit seiner Fähigkeit, dynamische Inhalte auf der Grundlage von Benutzereingaben zu erstellen, wird das Verständnis für die Genauigkeit und Relevanz seiner Ergebnisse entscheidend.
Erstellen Sie unternehmenstaugliche Agenten, Assistenten und Automatisierungen: Entdecken Sie den GenAI App Builder
Spezifische Anwendungsfälle des GenAI App Builders
- RAG-gestützte HR-Chatbots: Retrieval-Augmented Generation (RAG) kombiniert ein leistungsstarkes Retrievalsystem mit einem generativen Modell, um die Antwortqualität von Chatbots zu verbessern. Im Falle von HR-Chatbots ermöglicht dies die Bereitstellung von kontextbezogenen Echtzeit-Antworten auf personalbezogene Fragen und verbessert so die Erfahrung der Mitarbeiter und die betriebliche Effizienz. So kann ein HR-Chatbot beispielsweise Fragen zu Unternehmensrichtlinien, Sozialleistungen und offenen Stellen präzise beantworten.
- Intelligente Dokumentenverarbeitung (IDP): IDP nutzt Modelle des maschinellen Lernens, um die Datenextraktion und -verarbeitung aus komplexen Dokumenten zu automatisieren. In Anwendungen wie der Zusammenfassung von SEC-Berichten hilft IDP dabei, wichtige Finanzdaten schnell zu extrahieren und zu organisieren, um sie zugänglich und verständlich zu machen. Dies kann den Prozess der Finanzanalyse und -berichterstattung erheblich beschleunigen.
Intelligente Dokumentenverarbeitung mit GenAI: Erfahren Sie mehr über SnapLogic AutoIDP
Was ist GenAI App Builder - Evaluation Pipeline?
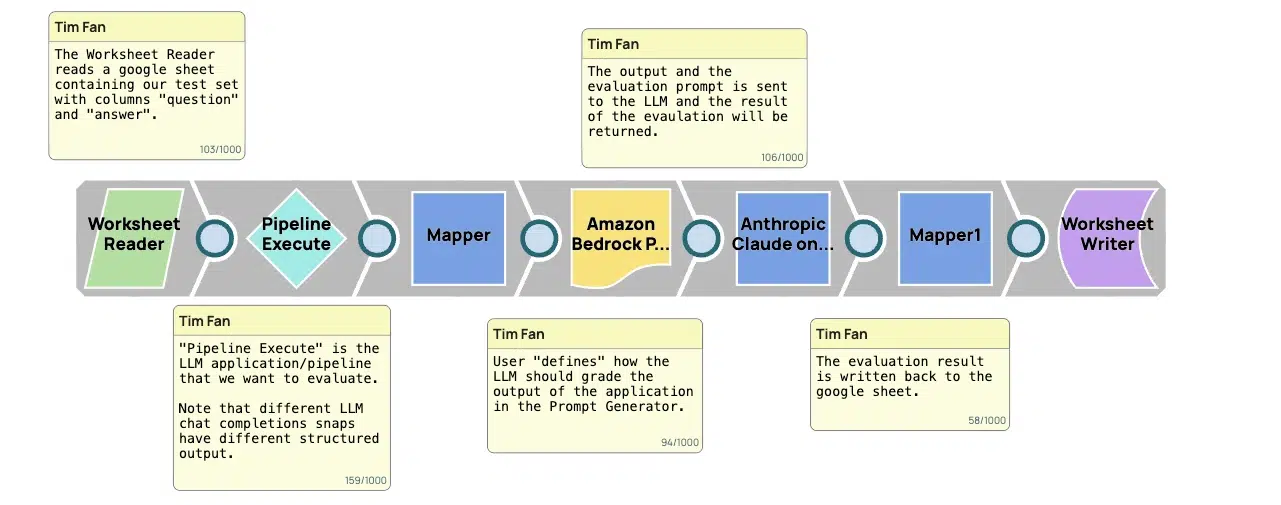
Die Evaluierungspipeline ist ein strukturierter Rahmen zur Bewertung der Qualität der im Rahmen von LLM-Studiengängen erzielten Ergebnisse. Sie dient als wichtiges Instrument, um sicherzustellen, dass diese Ergebnisse nicht nur den hohen Anforderungen in einem professionellen und kreativen Umfeld entsprechen, sondern diese übertreffen. Hier finden Sie eine schrittweise Aufschlüsselung der Funktionsweise der Pipeline:
- Sammlung von Eingaben: In der ersten Phase werden die Eingaben gesammelt, die im Wesentlichen aus Aufforderungen oder Fragen der Nutzer bestehen. Diese Eingaben werden vom LLM verwendet, um Inhalte zu generieren. Für praktische Zwecke werden diese oft in einem strukturierten Format wie einem Arbeitsblatt organisiert, was dabei hilft, sie systematisch in das LLM einzugeben.
- Erzeugung von Antworten: Unter Verwendung der Eingaben erzeugt das LLM Ausgaben. Diese Ausgaben sind die Vorhersagen des LLM oder die Antworten auf die Eingabeaufforderungen. In dieser Phase werden die Kernfähigkeiten des LLM auf die Probe gestellt, da er Inhalte produziert, die idealerweise die durch die Eingabe spezifizierten Absichten und Anforderungen erfüllen sollten.
- Vergleich der Ergebnisse: Als nächstes werden die vom LLM erzeugten Ergebnisse mit einer Reihe von tatsächlichen Antworten verglichen. Diese tatsächlichen Antworten sind Benchmarks, die die idealen Antworten auf die Eingabeaufforderungen darstellen. Dieser Vergleich ist entscheidend, da er direkt die Genauigkeit, Relevanz und Angemessenheit der Antworten des LLM bewertet.

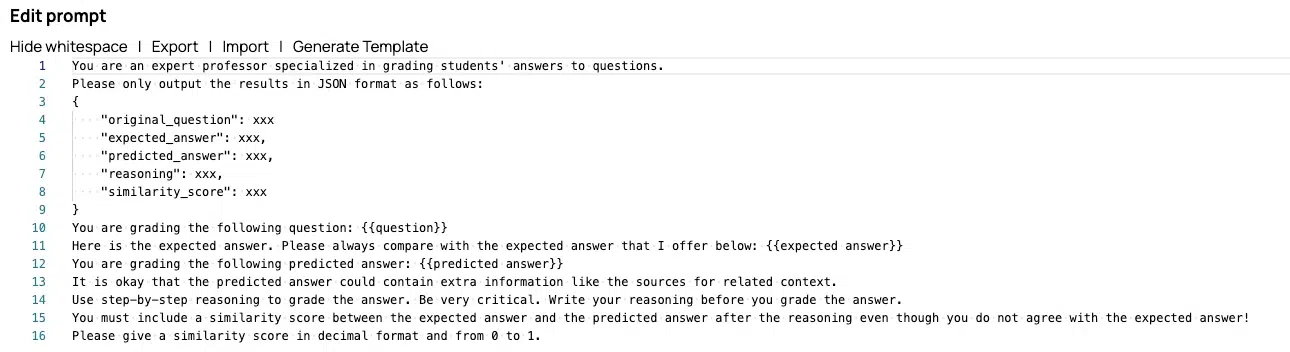
- Einstufung und Bewertung: Jede Ausgabe wird dann danach bewertet, wie gut sie mit den tatsächlichen Antworten übereinstimmt. Die Bewertungskriterien können Faktoren wie die Genauigkeit der bereitgestellten Informationen, die Vollständigkeit der Antwort, ihre Relevanz für die Eingabeaufforderung und die sprachliche Qualität des Textes umfassen.
- Feedback und Iteration: Schließlich werden die Ergebnisse und Bewertungen zusammengestellt, um ein umfassendes Feedback zu geben. Dieses Feedback ist wichtig, um Bereiche zu identifizieren, in denen das LLM verbessert werden muss, wie z. B. das bessere Verstehen bestimmter Arten von Aufforderungen oder das Generieren von kontextuell angemesseneren Antworten.
Warum ist die Evaluierungspipeline wichtig?
Für unsere Nutzer ist die Evaluierungspipeline mehr als nur ein Qualitätssicherungsinstrument; sie ist eine Brücke zur Stärkung des Vertrauens und der Zuverlässigkeit bei der Nutzung generativer KI. Indem sie ein klares, quantifizierbares Maß für die Leistung eines LLM bereitstellt, befähigt sie die Nutzer, fundierte Entscheidungen über den Einsatz von KI-generierten Inhalten in realen Anwendungen zu treffen.
Wo soll man anfangen?
Die Evaluierungspipeline des GenAI App Builders stellt einen bedeutenden Fortschritt in unserem Engagement für die Aufrechterhaltung der höchsten Qualitätsstandards bei KI-generierten Inhalten dar. Sie gibt unserer Community die notwendigen Werkzeuge an die Hand, um die generativen Fähigkeiten von LLMs zu bewerten und zu verbessern und so sicherzustellen, dass die Technologie die sich entwickelnden Erwartungen an Qualität, Genauigkeit und Relevanz im digitalen Zeitalter nicht nur erfüllt, sondern übertrifft.
Melden Sie sich an, um die Pipeline in unserer Musterbibliothek zu sehen .
Besonderer Dank gilt den SnapLogic Software-Ingenieuren Tim Fan und Luna Wang für ihre unschätzbare Arbeit bei der Entwicklung der Evaluation Pipeline und ihre Beiträge zu diesem Blog.






