





 Von Sharath Punreddy
Von Sharath Punreddy
Wie Sie wahrscheinlich wissen, verwenden SnapLogic-Datenpipelines Streams, also einen kontinuierlichen Datenfluss von einer Quelle zu einem Ziel. Durch die Verarbeitung und Extrahierung wertvoller Erkenntnisse aus Streaming-Daten kann ein Benutzer/System Entscheidungen schneller treffen als bei der herkömmlichen Stapelverarbeitung. Die Analyse von Streaming-Daten ermöglicht jetzt Analysen in nahezu Echtzeit, wenn nicht sogar in Echtzeit, einschließlich der Analyse von Twitter-Streaming-APIs.
In diesem datengesteuerten Zeitalter ist das Timing von Datenanalysen und Erkenntnissen zu einem wichtigen Unterscheidungsmerkmal geworden. In einigen Fällen verlieren die Daten mit zunehmendem Alter an Relevanz - wenn sie nicht sogar veraltet sind. Die Analyse der Daten zum Zeitpunkt ihres Eintreffens ist entscheidend für Anwendungsfälle wie die Gefühlsanalyse bei der Einführung neuer Produkte im Einzelhandel, die Erkennung betrügerischer Transaktionen in der Finanzbranche, die Vermeidung von Maschinenausfällen in der Fertigung, die Verarbeitung von Sensordaten für Wettervorhersagen, Krankheitsausbrüche im Gesundheitswesen usw. Die Stream-Verarbeitung ermöglicht eine Verarbeitung nahezu in Echtzeit, wenn nicht sogar in Echtzeit, so dass der Nutzer oder das System Erkenntnisse aus den neuesten Daten ziehen kann. Neben den herkömmlichen APIs bieten Unternehmen auch Streaming-APIs an, um Daten in Echtzeit zu verarbeiten, während sie generiert werden. Im Gegensatz zu herkömmlichen ReST/SOAP-APIs stellen Streaming-APIs eine Verbindung zum Server her und streamen die Daten kontinuierlich für die gewünschte Zeitspanne. Ist die Zeit abgelaufen, wird die Verbindung beendet. Apache Spark mit Apache Kafka als Streaming-Plattform hat sich zu einem De-facto-Industriestandard für die Stream-Verarbeitung entwickelt.
In diesem Blogbeitrag gehe ich die Schritte zum Aufbau einer einfachen Pipeline zum Abrufen und Verarbeiten von Twitter streamingAPI-Analysen durch. Sie können auch hier zum How-to-Video springen.
Twitter-Streams
Twitter hat sich zu einer wichtigen Datenquelle für die Stimmungsanalyse entwickelt. Die Twitter Streaming APIs ermöglichen den Zugriff auf globale Tweets und können in Echtzeit abgerufen werden, während die Leute tweeten. Snaplogic's "Twitter Streaming Query" Snap ermöglicht es Benutzern, Tweets basierend auf einem Schlüsselwort im Text des Tweets abzurufen. Die Tweets können dann mit Snaps wie Filter Snap, Mapper Snap oder Aggregate Snap verarbeitet werden, um sie zu filtern, zu transformieren bzw. zu aggregieren. SnapLogic bietet auch einen "Spark Script"-Snap, mit dem ein vorhandenes Python-Programm auf eingehende Tweets ausgeführt werden kann. Mit der Streaming-API-Analyse von Twitter können Tweets auch auf der Grundlage einer Bedingung an verschiedene Ziele weitergeleitet und zur Speicherung und weiteren Analyse an mehrere Ziele (RDBMS, HDFS, S3 usw.) kopiert werden.
Erste Schritte
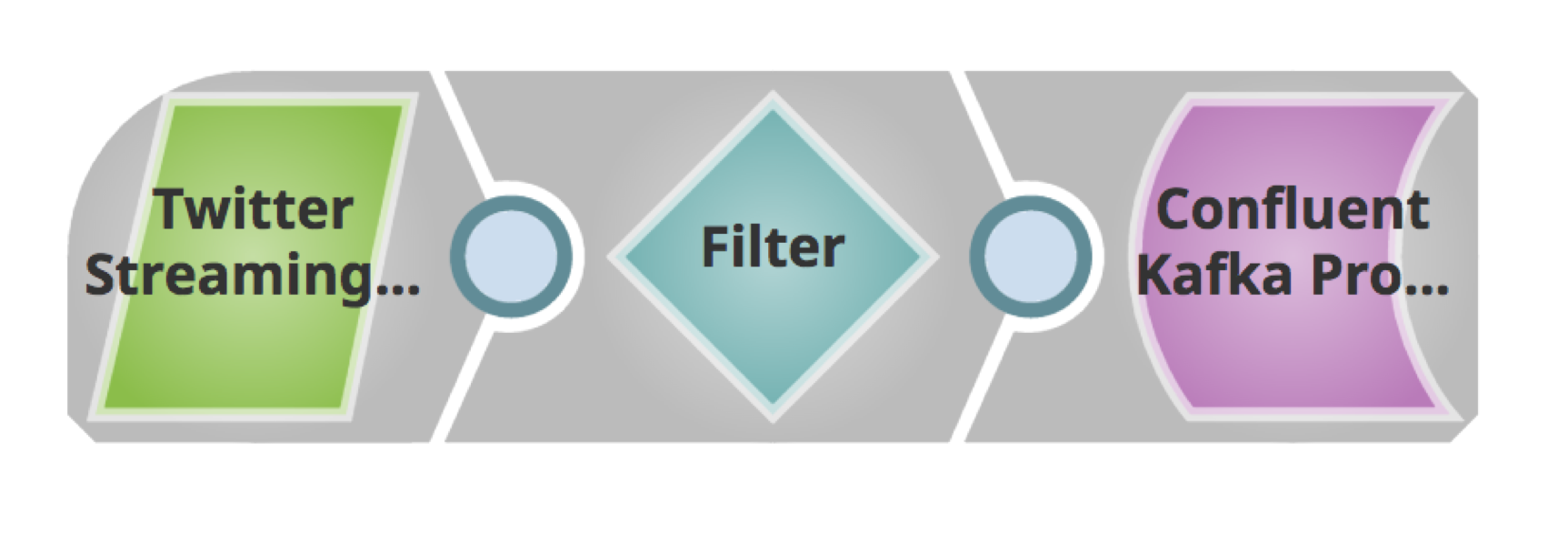
Nachfolgend finden Sie eine einfache Pipeline zum Abrufen von Tweets, zum Filtern nach der Sprache und zum Veröffentlichen in einem Kafka-Cluster.
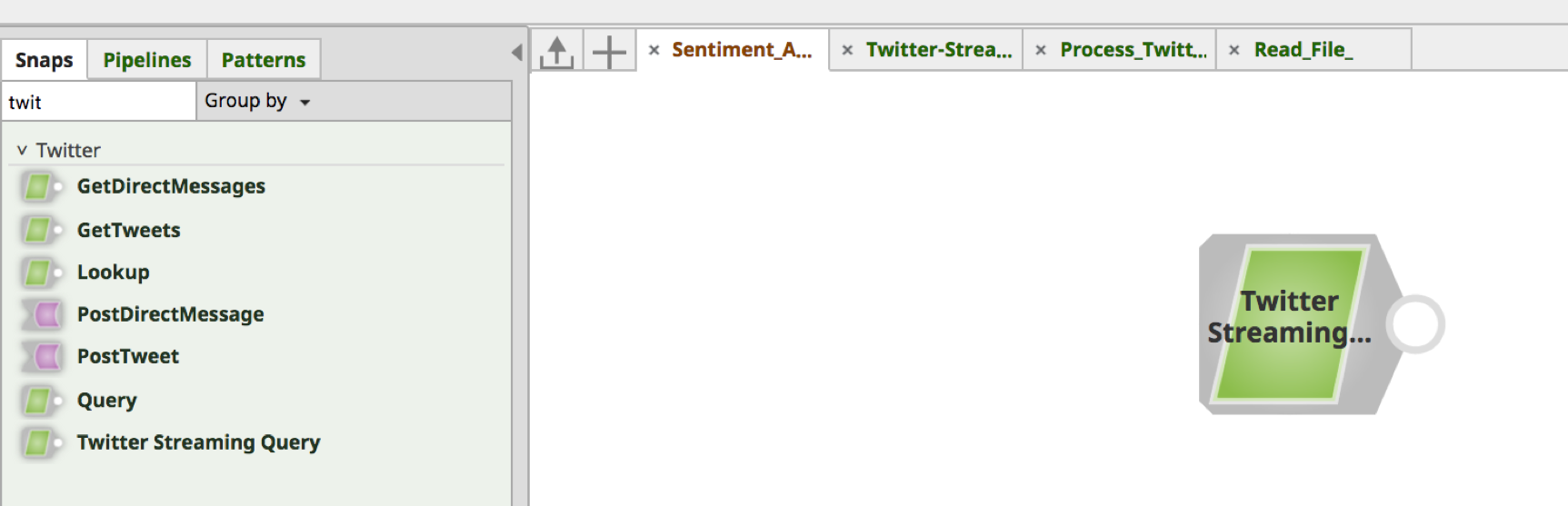
 Suchen Sie auf der Registerkarte Schnappschüsse im linken Rahmen nach dem Schnappschuss. Ziehen Sie den Schnappschuss auf die Designer-Leinwand (weißer Bereich auf der rechten Seite) und legen Sie ihn dort ab.
Suchen Sie auf der Registerkarte Schnappschüsse im linken Rahmen nach dem Schnappschuss. Ziehen Sie den Schnappschuss auf die Designer-Leinwand (weißer Bereich auf der rechten Seite) und legen Sie ihn dort ab.
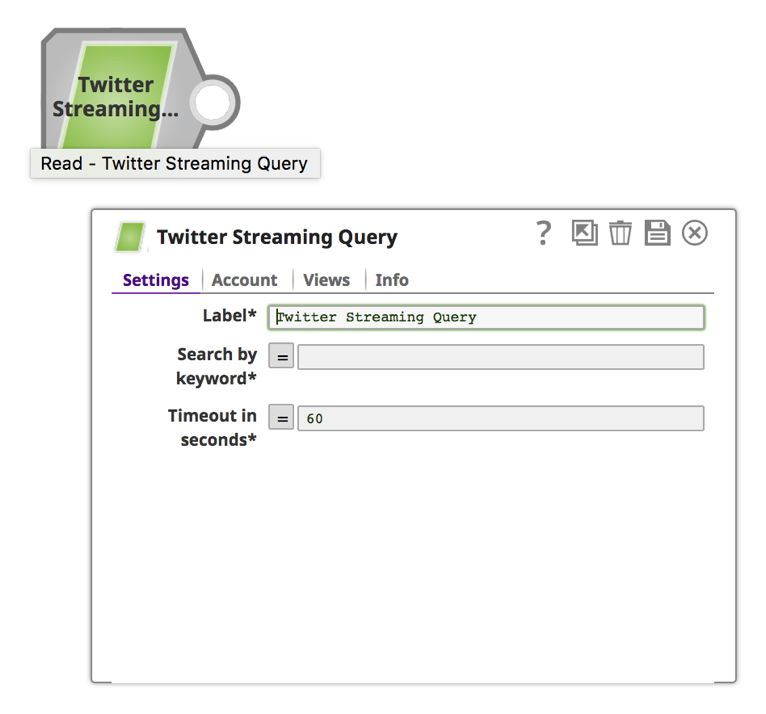
 a. Klicken Sie auf den Snap, um das Formular Snap-Einstellungen zu öffnen.
a. Klicken Sie auf den Snap, um das Formular Snap-Einstellungen zu öffnen.
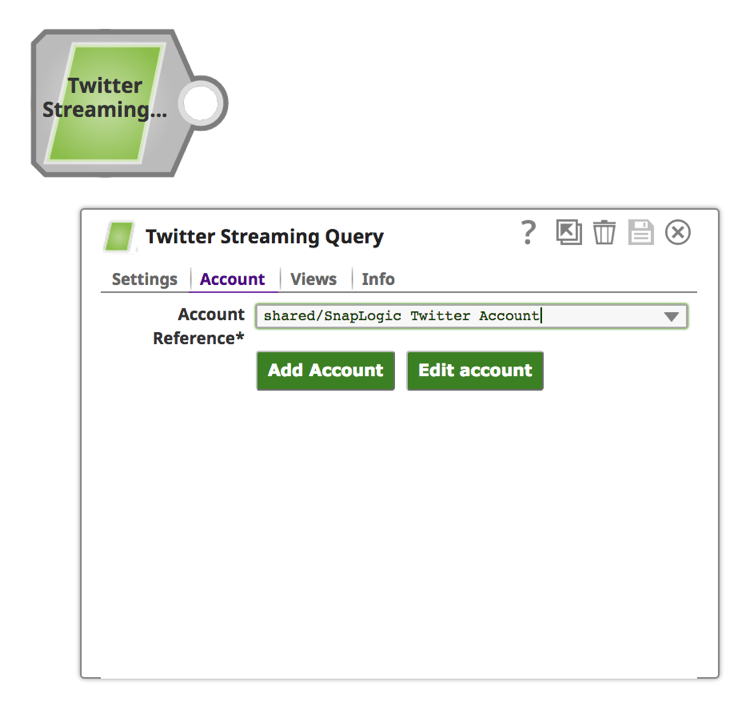
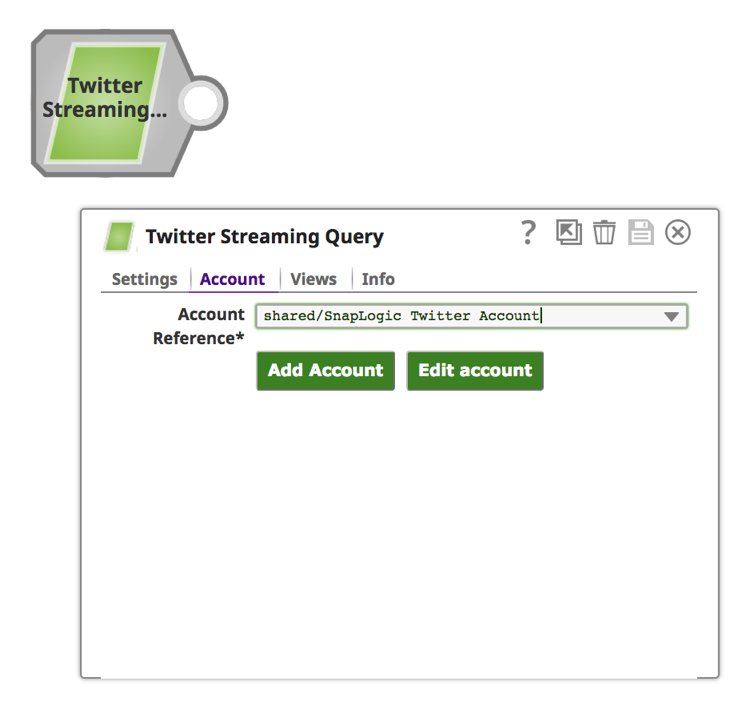
 Anmerkung: Für die "Twitter Streaming Query"-Snap und damit für die Twitter Streaming-API-Analytik ist ein Twitter-Konto erforderlich, das über den Designer während der Erstellung der Pipeline oder über den Manager vor der Erstellung der Pipeline erstellt werden kann.
Anmerkung: Für die "Twitter Streaming Query"-Snap und damit für die Twitter Streaming-API-Analytik ist ein Twitter-Konto erforderlich, das über den Designer während der Erstellung der Pipeline oder über den Manager vor der Erstellung der Pipeline erstellt werden kann.
b. Klicken Sie auf die Registerkarte "Konto".
 c. Klicken Sie auf die Schaltfläche "Konto hinzufügen".
c. Klicken Sie auf die Schaltfläche "Konto hinzufügen".
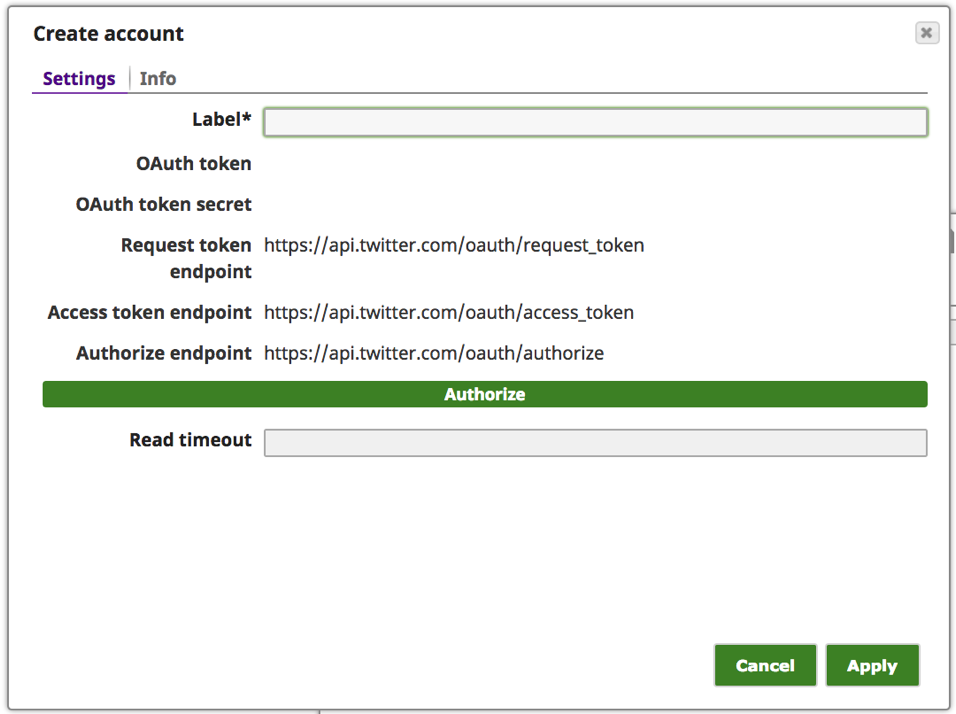
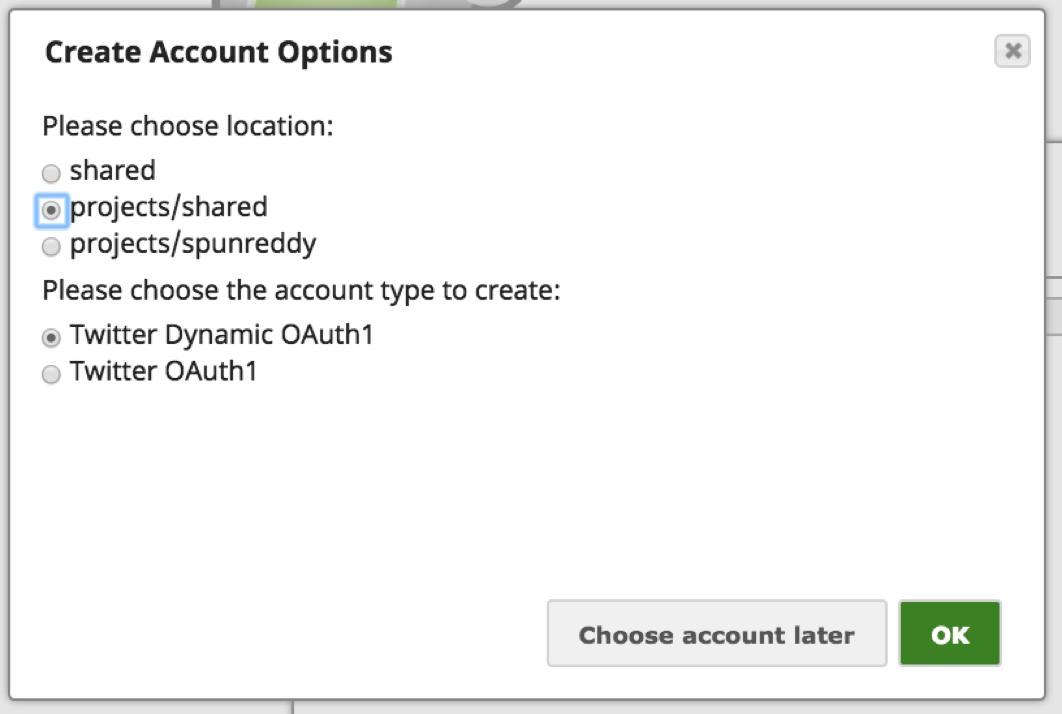 Anmerkung: Twitter bietet eine Reihe von Wege zur Authentifizierung Anwendungen auf Twitter-Konto. Das "Twitter Dynamic OAuth1" ist für Nur-Anwendungs-Authentifizierung und "Twitter OAuth1" ist für Benutzer-Authentifizierung wo der Benutzer die Anwendung durch Anmeldung bei Twitter authentifizieren muss. In diesem Fall verwenden wir den Mechanismus der Benutzerauthentifizierung.
Anmerkung: Twitter bietet eine Reihe von Wege zur Authentifizierung Anwendungen auf Twitter-Konto. Das "Twitter Dynamic OAuth1" ist für Nur-Anwendungs-Authentifizierung und "Twitter OAuth1" ist für Benutzer-Authentifizierung wo der Benutzer die Anwendung durch Anmeldung bei Twitter authentifizieren muss. In diesem Fall verwenden wir den Mechanismus der Benutzerauthentifizierung.
d. Wählen Sie eine geeignete Option auf der Grundlage der Zugänglichkeit des Kontos:
i. Für den Standort des Kontos: Bei "gemeinsam" ist das Konto für die gesamte Organisation zugänglich, bei "Projekte/gemeinsam" für alle Benutzer des Projekts und bei "Projekt/" nur für den Benutzer.
ii. Für Kontotyp: Wählen Sie die Option "Twitter OAuth1", um den Zugriff auf das Twitter-Konto des einzelnen Benutzers zu ermöglichen.
iii. Klicken Sie auf "OK".
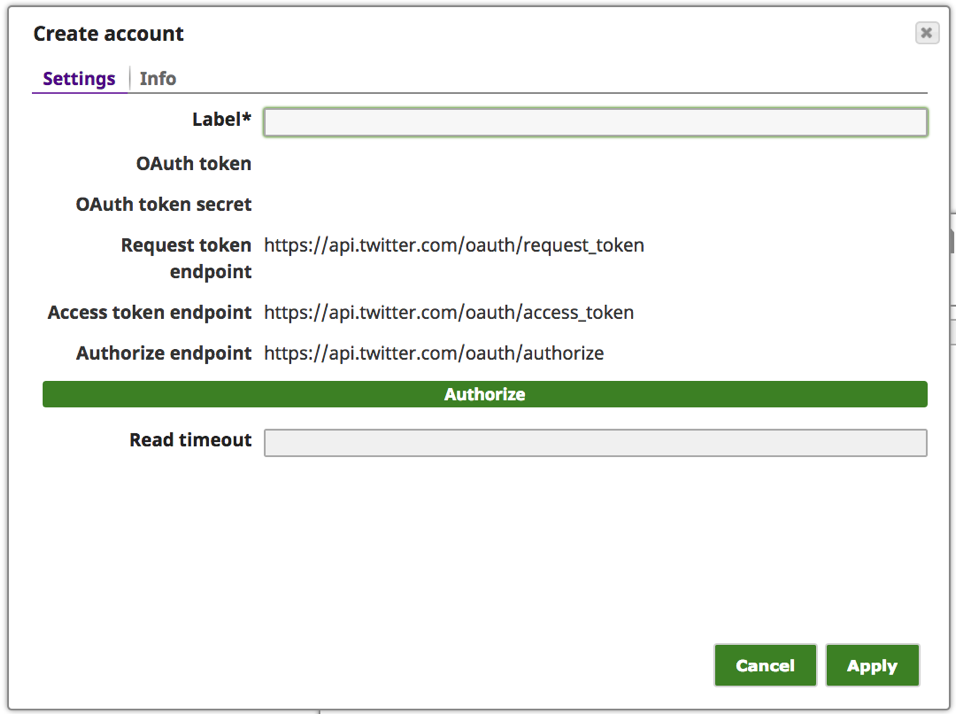 e. Geben Sie einen aussagekräftigen Text für das "Label" ein, z. B. [Twitter_von_], und klicken Sie auf die Schaltfläche "Autorisieren".
e. Geben Sie einen aussagekräftigen Text für das "Label" ein, z. B. [Twitter_von_], und klicken Sie auf die Schaltfläche "Autorisieren".
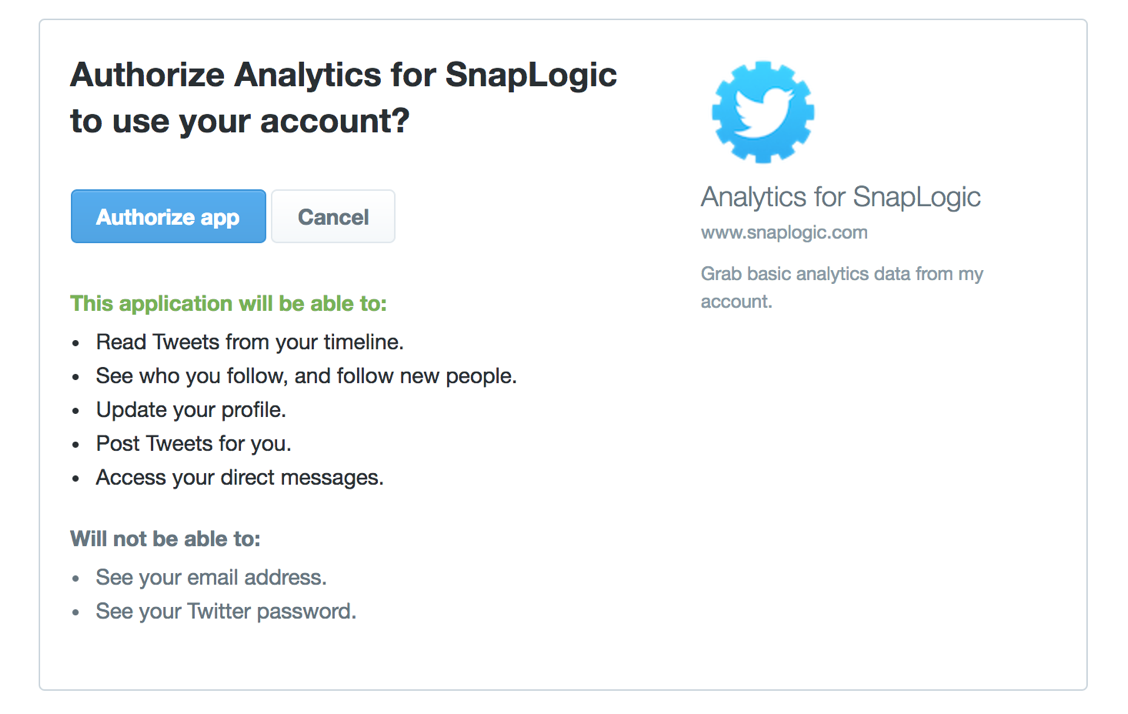 Anmerkung: Wenn ein Benutzer bei Twitter mit einer aktiven Sitzung angemeldet ist, wird er auf die Seite "Autorisieren" der Twitter-Website weitergeleitet, wo er den Zugriff auf die Anwendung gewähren kann. Wenn der Benutzer nicht angemeldet ist oder keine aktive Sitzung hat, wird der Benutzer zur Anmeldeseite von Twitter weitergeleitet, wo er sich anmelden kann.
Anmerkung: Wenn ein Benutzer bei Twitter mit einer aktiven Sitzung angemeldet ist, wird er auf die Seite "Autorisieren" der Twitter-Website weitergeleitet, wo er den Zugriff auf die Anwendung gewähren kann. Wenn der Benutzer nicht angemeldet ist oder keine aktive Sitzung hat, wird der Benutzer zur Anmeldeseite von Twitter weitergeleitet, wo er sich anmelden kann.
f. Klicken Sie auf die Schaltfläche "App autorisieren".
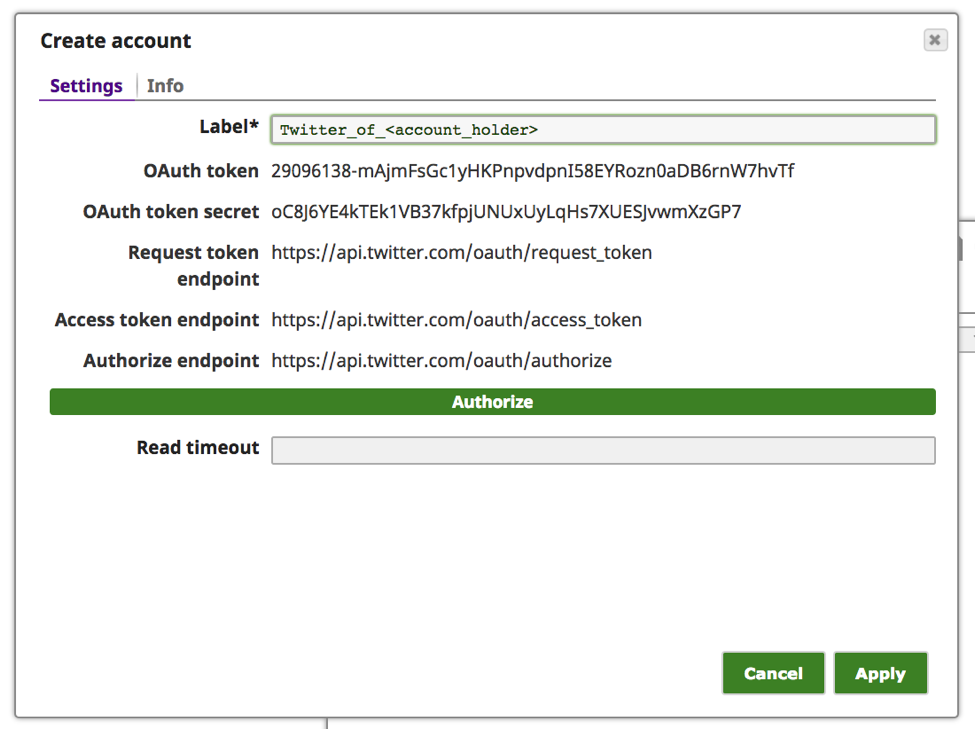 Anmerkung: Die obigen Werte "OAuth-Token" und "OAuth-Token-Geheimnis" sind nicht aktiv und dienen nur als Beispiel.
Anmerkung: Die obigen Werte "OAuth-Token" und "OAuth-Token-Geheimnis" sind nicht aktiv und dienen nur als Beispiel.
g. Zu diesem Zeitpunkt sollten das "OAuth-Token" und das "OAuth-Token-Geheimnis" ausgefüllt worden sein. Klicken Sie auf "Anwenden".
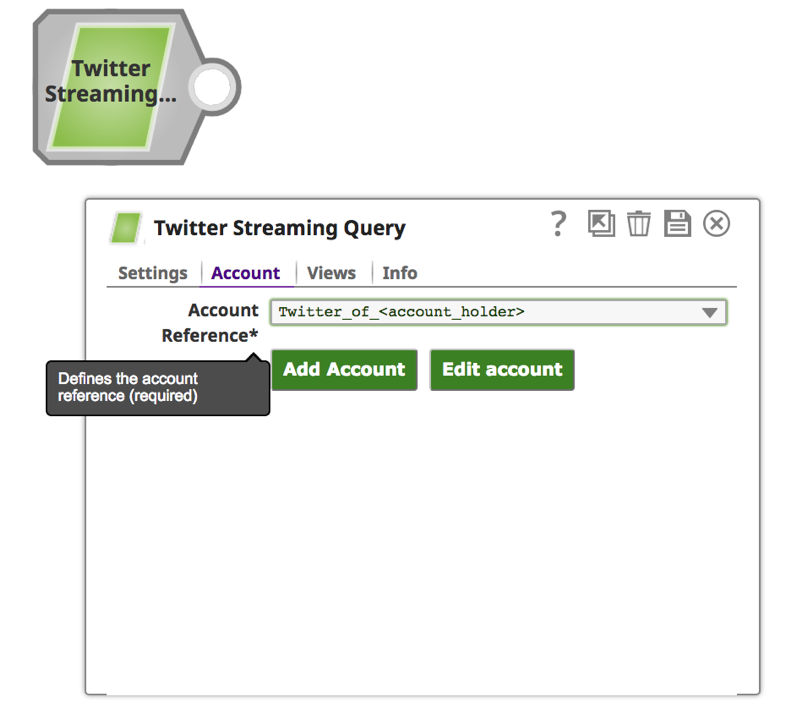 2. Sobald das Konto erfolgreich eingerichtet ist, klicken Sie auf die Registerkarte "Einstellungen", um das Suchwort und die Uhrzeit anzugeben.
2. Sobald das Konto erfolgreich eingerichtet ist, klicken Sie auf die Registerkarte "Einstellungen", um das Suchwort und die Uhrzeit anzugeben.
 Anmerkung: Der Twitter Snap wird Tweets für eine bestimmte Zeitdauer abrufen. Wenn Sie einen kontinuierlichen Abruf wünschen, können Sie für "Timeout in Sekunden" den Wert "0" angeben.
Anmerkung: Der Twitter Snap wird Tweets für eine bestimmte Zeitdauer abrufen. Wenn Sie einen kontinuierlichen Abruf wünschen, können Sie für "Timeout in Sekunden" den Wert "0" angeben.
a. Geben Sie ein Stichwort und eine Zeitdauer in Sekunden ein.
3. Speichern Sie, indem Sie auf das Diskettensymbol oben rechts klicken. ![]() . Dies löst die Validierung aus und sollte zu einem Häkchen werden
. Dies löst die Validierung aus und sollte zu einem Häkchen werden ![]() wenn die Validierung erfolgreich ist.
wenn die Validierung erfolgreich ist.
4. Klicken Sie auf die Liste ![]() um eine Vorschau der Daten zu erhalten.
um eine Vorschau der Daten zu erhalten.
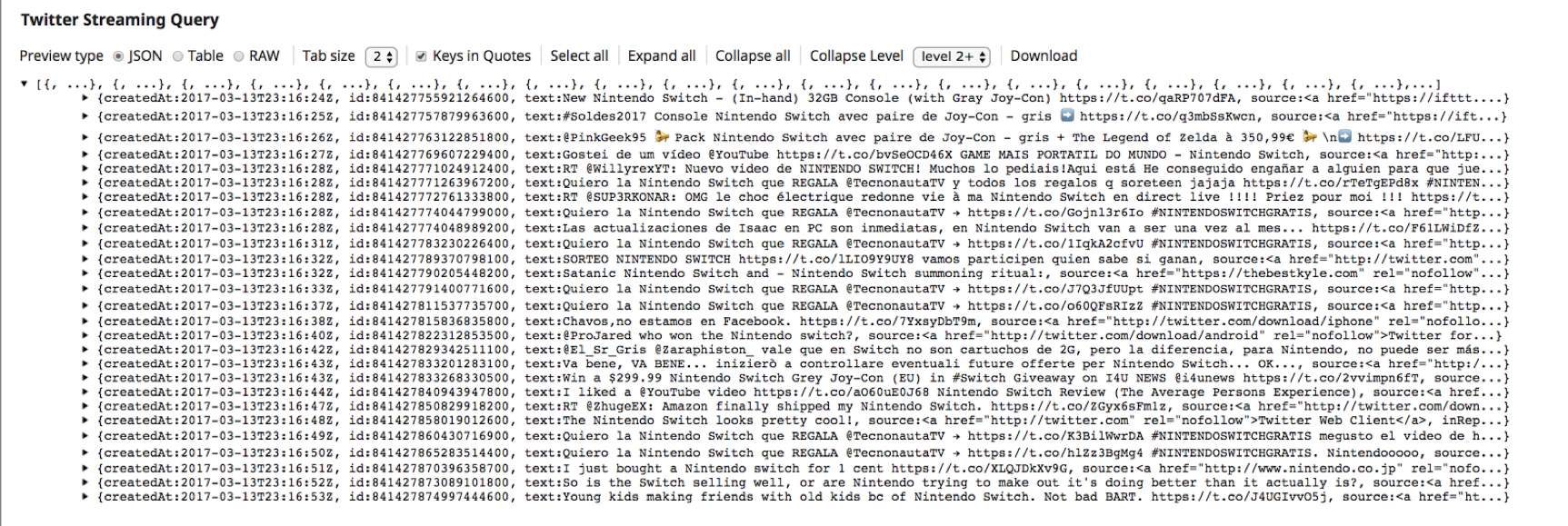 5. Dies bestätigt, dass der Snap "Twitter Streaming Query" erfolgreich eine Verbindung mit dem Twitter-Konto hergestellt hat und die Tweets abruft.
5. Dies bestätigt, dass der Snap "Twitter Streaming Query" erfolgreich eine Verbindung mit dem Twitter-Konto hergestellt hat und die Tweets abruft.
6. Der Snap "Filter" wird zum Filtern von Tweets verwendet. Suchen Sie auf der Registerkarte Snaps im linken Rahmen nach "Filter". Ziehen Sie den Snap "Filter" auf die Leinwand.
 a. Klicken Sie auf "Filter" Snap, um das Formular Einstellungen zu öffnen.
a. Klicken Sie auf "Filter" Snap, um das Formular Einstellungen zu öffnen.
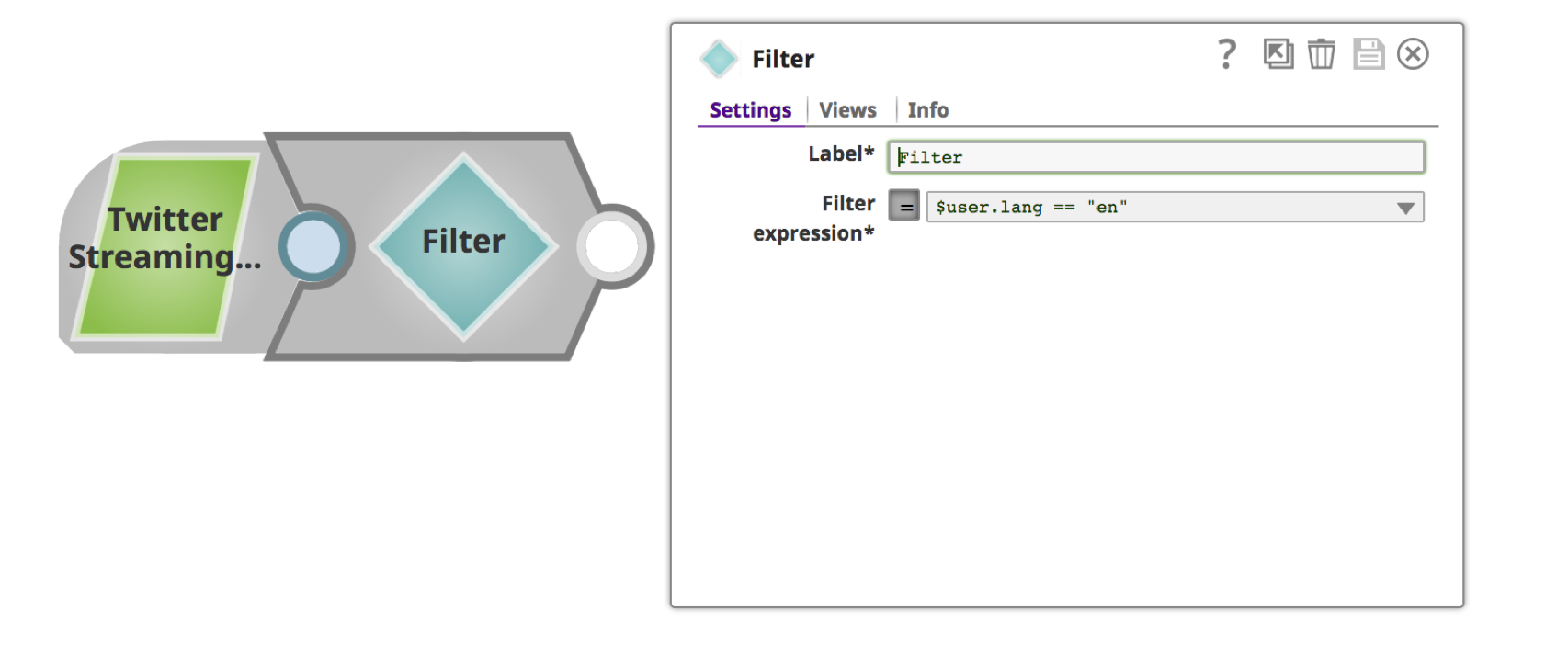 b. Geben Sie einen aussagekräftigen Namen wie "Filter nach Sprache" für das "Label" und die Filterbedingung für "Filterausdruck" an. Sie können das Dropdown-Menü für die Auswahl des Filterattributs verwenden.
b. Geben Sie einen aussagekräftigen Namen wie "Filter nach Sprache" für das "Label" und die Filterbedingung für "Filterausdruck" an. Sie können das Dropdown-Menü für die Auswahl des Filterattributs verwenden.
7. Klicken Sie auf das Diskettensymbol ![]() um ihn zu speichern, was wiederum eine Validierung auslöst. Sie haben nun erfolgreich einen "Filter"-Snap abgeschlossen.
um ihn zu speichern, was wiederum eine Validierung auslöst. Sie haben nun erfolgreich einen "Filter"-Snap abgeschlossen.
8. Suchen Sie den Snap "Confluent Kafka Producer" auf der Registerkarte Snaps im linken Frame. Ziehen Sie den Snap auf die Leinwand und legen Sie ihn ab.
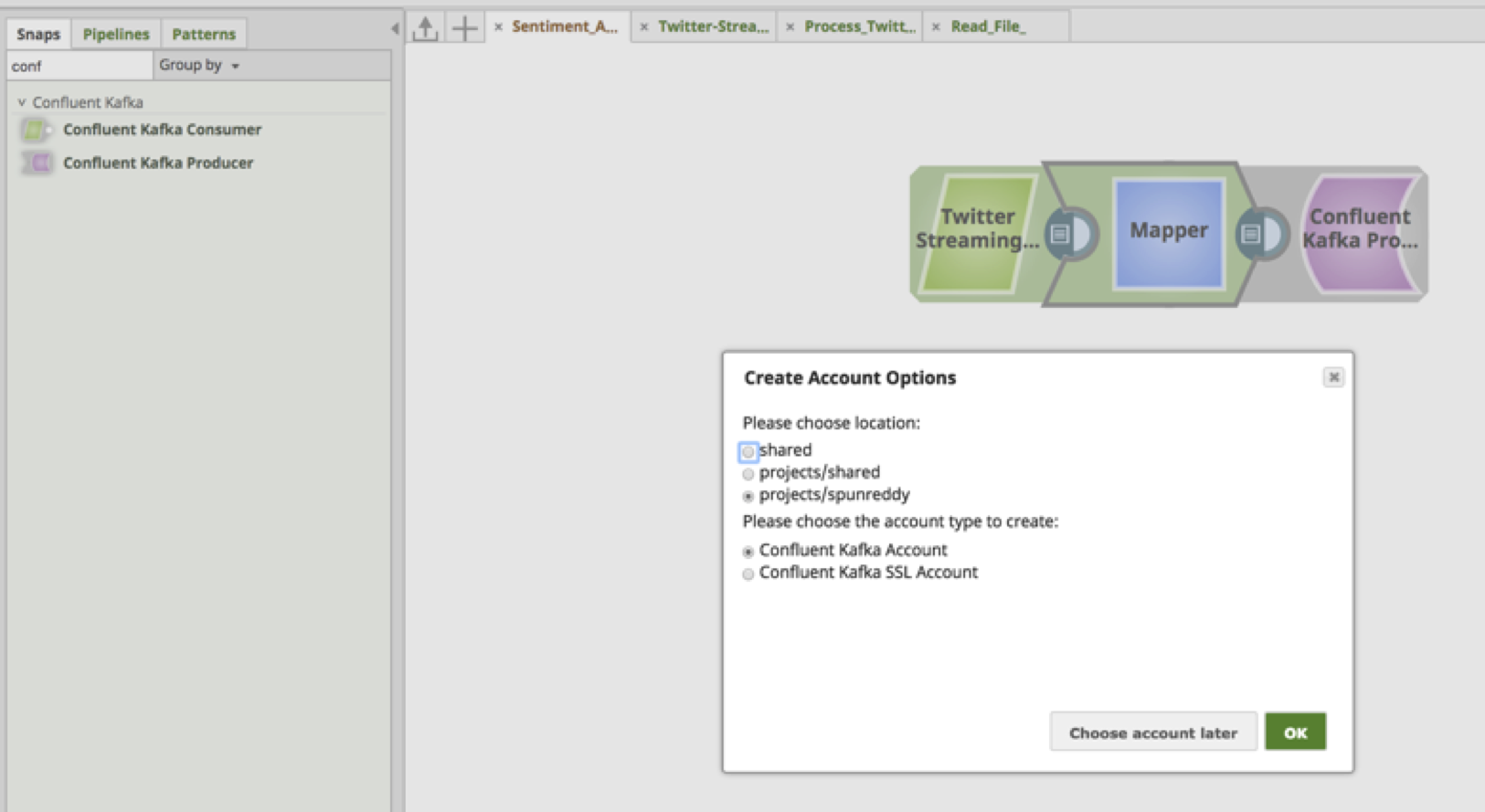 Anmerkung: Konfluent ist eine Apache-Kafka-Distribution, die für Unternehmen gedacht ist.
Anmerkung: Konfluent ist eine Apache-Kafka-Distribution, die für Unternehmen gedacht ist.
a. Der "Confluent Kafka Producer" benötigt ein Konto, um sich mit dem Kafka-Cluster zu verbinden. Wählen Sie je nach Standort und Typ des Kontos entsprechende Werte.
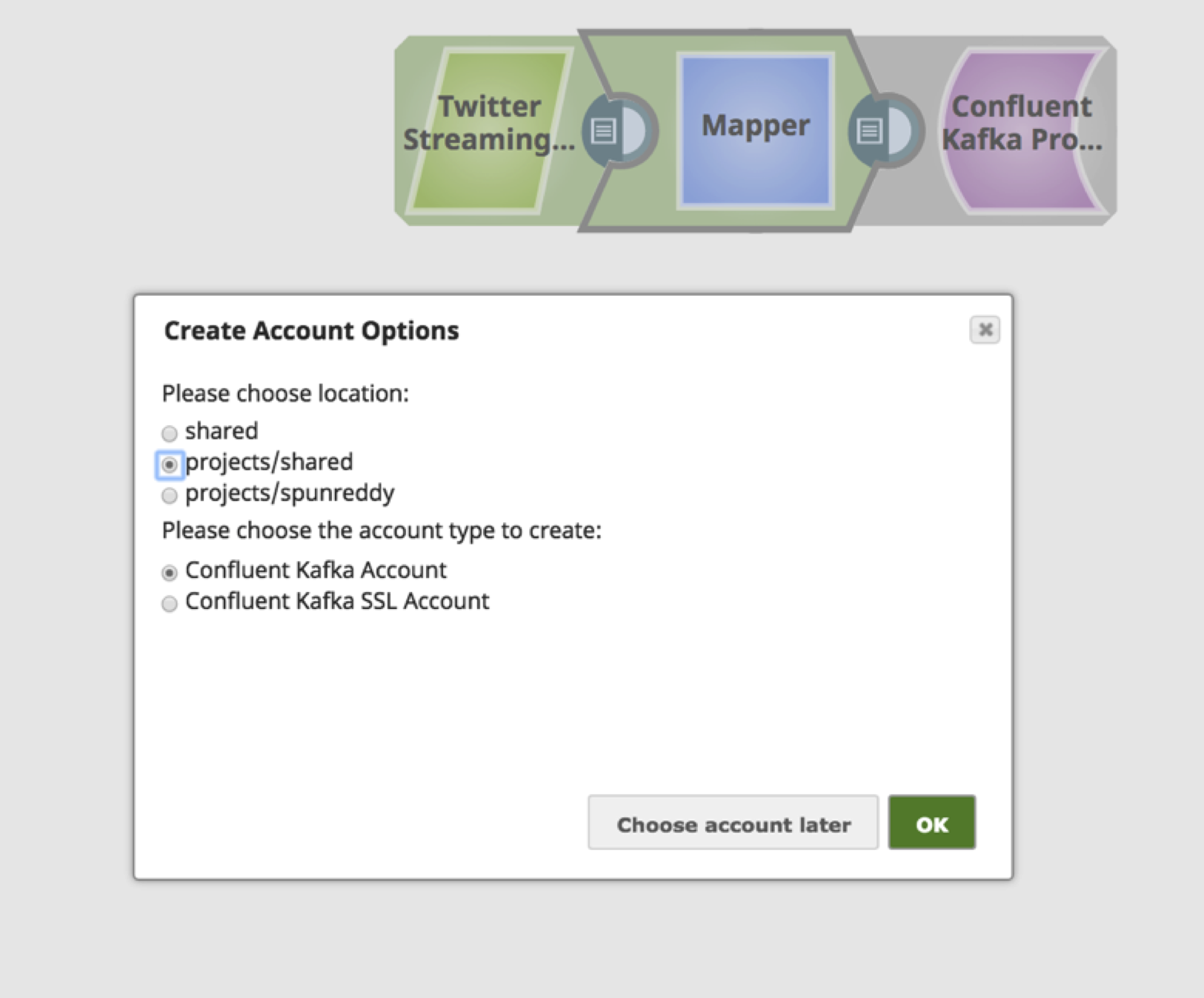 b. Geben Sie einen aussagekräftigen Text für das "Label" des/der Bootstrap-Server(s) an. Bei mehreren Bootstrap-Servern sind diese durch ein Komma zu trennen, ebenso wie der Port.
b. Geben Sie einen aussagekräftigen Text für das "Label" des/der Bootstrap-Server(s) an. Bei mehreren Bootstrap-Servern sind diese durch ein Komma zu trennen, ebenso wie der Port.
 c. Die "Schema registry URL" ist optional, wird aber benötigt, wenn Kafka die Nachricht auf der Grundlage des Schemas analysieren soll.
c. Die "Schema registry URL" ist optional, wird aber benötigt, wenn Kafka die Nachricht auf der Grundlage des Schemas analysieren soll.
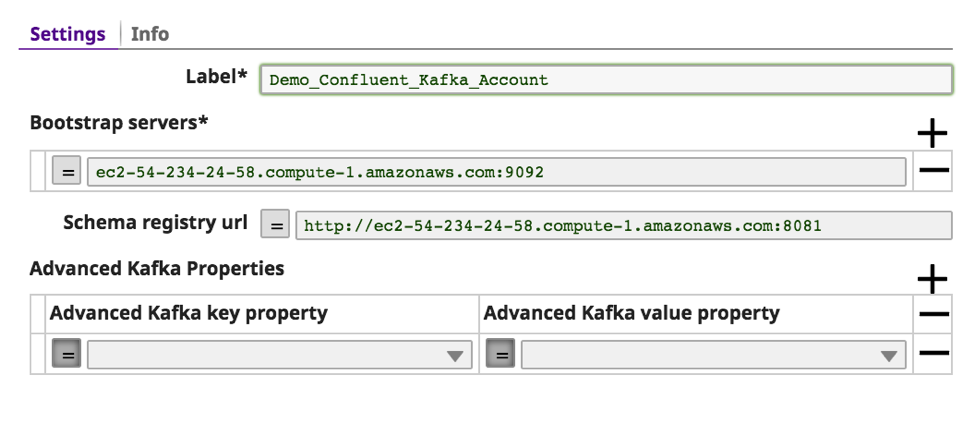 d. Die anderen optionalen Kafka-Eigenschaften können über die "Erweiterten Kafka-Eigenschaften" an Kafka übergeben werden. Klicken Sie auf "validieren".
d. Die anderen optionalen Kafka-Eigenschaften können über die "Erweiterten Kafka-Eigenschaften" an Kafka übergeben werden. Klicken Sie auf "validieren".
e. Wenn die Überprüfung erfolgreich war, sollten Sie oben die Meldung "Kontoüberprüfung erfolgreich" sehen. Klicken Sie auf "Übernehmen".
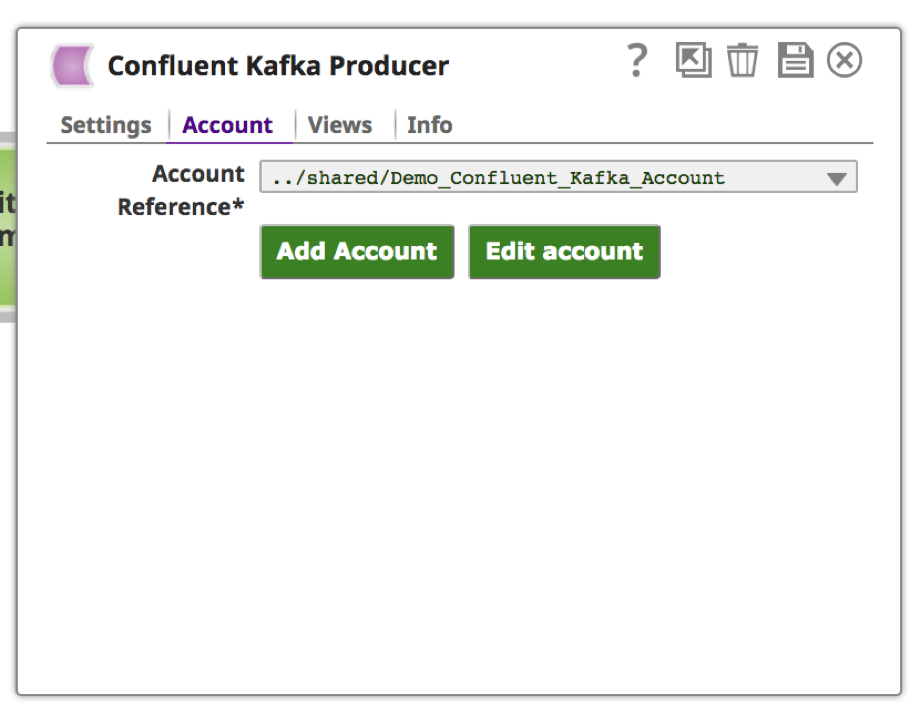 9. Sobald das Konto eingerichtet und ausgewählt ist, klicken Sie auf die Registerkarte "Einstellungen", um das Kafka-Thema und die Nachricht anzugeben.
9. Sobald das Konto eingerichtet und ausgewählt ist, klicken Sie auf die Registerkarte "Einstellungen", um das Kafka-Thema und die Nachricht anzugeben.
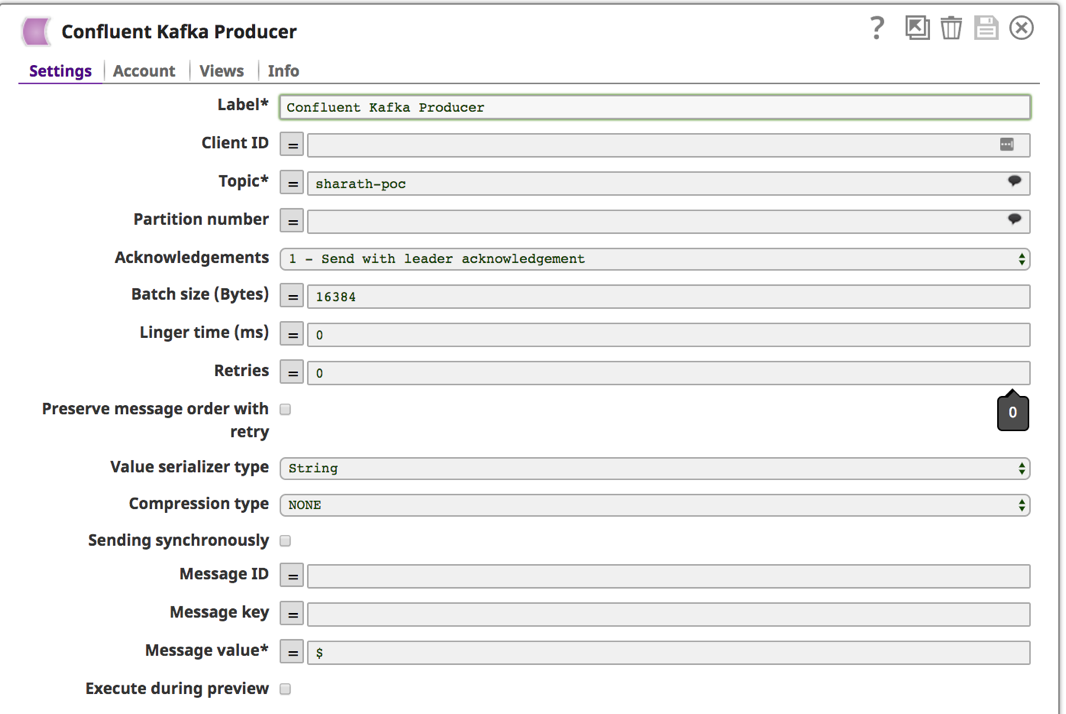
a. Sie können aus der Liste der verfügbaren Themen wählen, indem Sie auf das Sprechblasensymbol ![]() neben dem Feld "Thema". Belassen Sie die anderen Felder in der Standardeinstellung. Ein weiteres erforderliches Feld ist "Nachrichtenwert". Geben Sie "$" ein, um den gesamten Tweet und die Metadateninformationen zu senden. Speichern Sie, indem Sie auf das Diskettensymbol
neben dem Feld "Thema". Belassen Sie die anderen Felder in der Standardeinstellung. Ein weiteres erforderliches Feld ist "Nachrichtenwert". Geben Sie "$" ein, um den gesamten Tweet und die Metadateninformationen zu senden. Speichern Sie, indem Sie auf das Diskettensymbol ![]() .
.
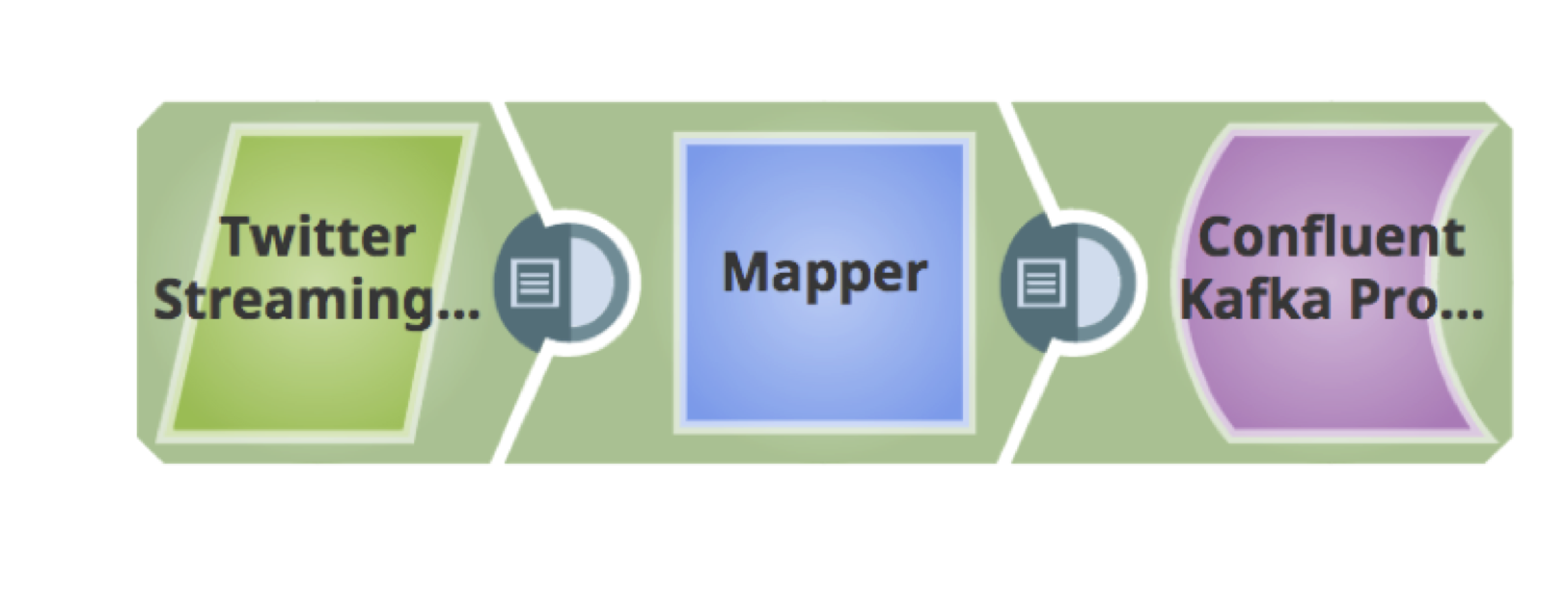 10. Dies ist eine vollständig validierte Pipeline zum Abrufen der Tweets und Laden in Kafka.
10. Dies ist eine vollständig validierte Pipeline zum Abrufen der Tweets und Laden in Kafka.
11. Jetzt ist die Pipeline so eingestellt, dass sie die Tweets empfängt und sie in das Kafka-Topic schiebt. Führen Sie die Pipeline aus, indem Sie auf die Schaltfläche "Play" in der rechten oberen Ecke klicken ![]() . Zeigen Sie den Fortschritt an, indem Sie auf die Schaltfläche "Anzeigen" klicken
. Zeigen Sie den Fortschritt an, indem Sie auf die Schaltfläche "Anzeigen" klicken ![]() .
.
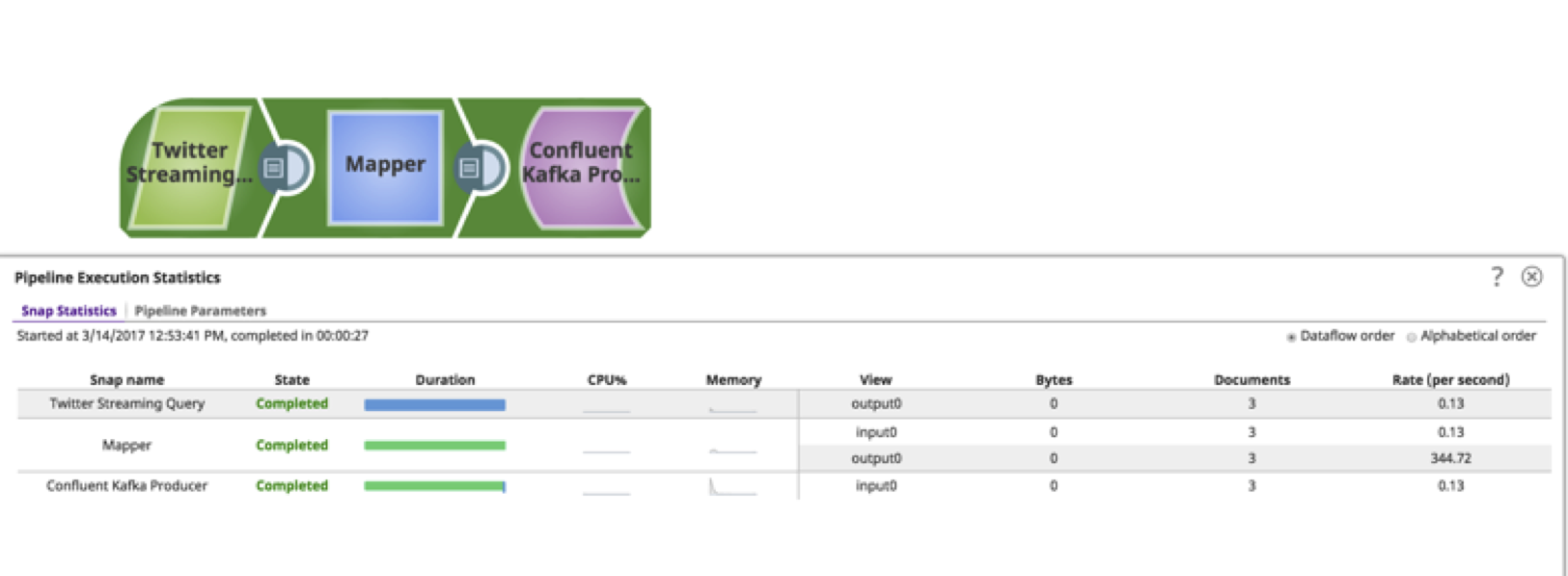 Wie Sie sehen können, lässt sich die Pipeline in weniger als 15 Minuten aufbauen, ohne dass tiefgreifende technische Kenntnisse erforderlich sind. Dieses Lernprogramm und Video bietet ein grundlegendes Beispiel dafür, was mit Hilfe dieser Snaps erreicht werden kann. Es gibt verschiedene andere Snaps, die auf die Daten wirken können, wie Filtern, Kopieren, Aggregieren, Auslösen von Ereignissen, Versenden von E-Mails und andere. Snaplogic ist stolz darauf, komplexe Technologie für Citizen Integrator bereitzustellen. Ich hoffe, Sie fanden dies nützlich!
Wie Sie sehen können, lässt sich die Pipeline in weniger als 15 Minuten aufbauen, ohne dass tiefgreifende technische Kenntnisse erforderlich sind. Dieses Lernprogramm und Video bietet ein grundlegendes Beispiel dafür, was mit Hilfe dieser Snaps erreicht werden kann. Es gibt verschiedene andere Snaps, die auf die Daten wirken können, wie Filtern, Kopieren, Aggregieren, Auslösen von Ereignissen, Versenden von E-Mails und andere. Snaplogic ist stolz darauf, komplexe Technologie für Citizen Integrator bereitzustellen. Ich hoffe, Sie fanden dies nützlich!
Sharath Punreddy ist Enterprise Solution Architect bei SnapLogic. Folgen Sie ihm auf Twitter @srpunreddy.





{kind=link}