Ursprünglich veröffentlicht auf medium.com.
Dieser Beitrag soll einen Überblick darüber geben, wie eine Integrationsplattform als Service (iPaaS) in einem Unternehmen eingesetzt werden kann, um Datensilos zu beseitigen. Er richtet sich an Datenintegratoren und Datenarchitekten. Integrationsplattformen bieten im Wesentlichen zwei Arten von Funktionen:
- Datenintegration: Stapelverarbeitung von Daten. Die Integrationsplattform bietet Unterstützung für die Verarbeitung von Daten aus verschiedenen Speichersystemen und Dateiformaten und unterstützt die visuelle Entwicklung von Datentransformationsfunktionen.
- Application Integration: Synchronisierung von Daten zwischen Anwendungen. Die Integrationsplattform bietet Konnektoren zum Lesen und Schreiben von Daten aus verschiedenen Anwendungsendpunkten. In Kombination mit den im Rahmen der Datenintegration unterstützten Transformationen können Daten von jeder Quelle zu jedem Ziel verschoben werden, wobei die erforderlichen Transformationen durchgeführt werden.
Typisches Unternehmenslayout
Ein typisches Unternehmen betreibt mehrere Anwendungen, von denen einige als SaaS-Anwendungen und andere in den Rechenzentren des Kunden ausgeführt werden. Dieses Netzwerklayout zeigt die wenig beneidenswerte Aufgabe eines Datenintegrators, der Daten aus verschiedenen Quellen kombinieren muss.
Das gezeigte Unternehmen nutzt zwei Rechenzentren, eines im Osten und eines im Westen der USA, die jeweils einige Anwendungen (wie SAP/Oracle) und einige Datenbanken hosten. Es gibt ein IaaS-Konto (AWS/Azure/GCP), das benutzerdefinierte Anwendungen und ein Data Warehouse hostet. Es sind mehrere SaaS-Anwendungen im Einsatz (wie Workday/NetSuite usw.).
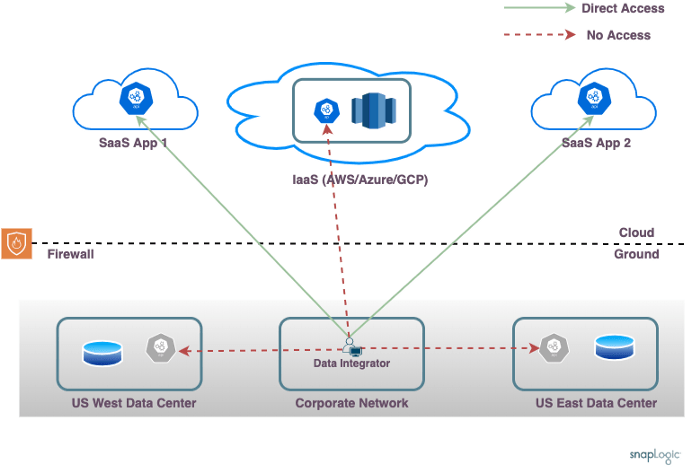
Einige der zu berücksichtigenden Komplexitäten sind:
- Unternehmensnetzwerk: Der Datenintegrator erstellt die Pipelines zur Orchestrierung der Datenverarbeitung. Das Unternehmensnetzwerk, von dem aus der Pipeline-Entwurf erfolgt (bzw. das Heimnetzwerk), hat möglicherweise keinen direkten Netzwerkzugriff auf das Rechenzentrum und die Cloud-IaaS-Konten.
- Datenlokalisierung: Die Entwicklung der Pipeline und die eigentliche Datenverarbeitung erfolgen auf verschiedenen Rechnern. Der Datenintegrator befindet sich im Unternehmensnetzwerk, aber die eigentliche Datenverarbeitung muss in der Regel auf einem der Knotenpunkte des Rechenzentrums oder auf dem IaaS-Konto erfolgen. Dies ist aufgrund der Anforderungen an die Endpunktkonnektivität erforderlich und um sicherzustellen, dass die Datenverarbeitung unter Berücksichtigung der Datenlokalität und näher an den Datenquellen erfolgt.
- Vor-Ort-Firewall: Die Knoten vor Ort befinden sich hinter einer Firewall. Es ist zwar möglich, eine Firewall-Regel zu öffnen, um eingehende Verbindungen aus dem offenen Internet zuzulassen, doch wird dies in der Regel nicht empfohlen und von den Netzwerkbetriebsteams in Unternehmen untersagt.
- Isolierte Netzwerke: Die Knoten im IaaS-Konto sind in der Regel nicht vom lokalen Rechenzentrum aus erreichbar und umgekehrt. Es ist zwar möglich, Direct Connect oder ein gleichwertiges Netzwerk einzurichten, um einen direkten Zugang zwischen den lokalen und den IaaS-Knoten zu ermöglichen, doch wäre eine Unternehmensnetzwerkarchitektur, die keinen direkten Zugang zwischen den Rechenzentren voraussetzt, langfristig flexibler und zuverlässiger. Außerdem können die verschiedenen Rechenzentren vor Ort möglicherweise nicht direkt miteinander kommunizieren. VPNs ermöglichen zwar den Zugang zu einigen Endpunkten, aber normalerweise nicht zu allen Endpunkten gleichzeitig. Dies gilt insbesondere für weltweit verteilte Rechenzentren und für Fälle, in denen es Endpunkte in mehreren IaaS-Regionen oder sogar bei mehreren IaaS-Anbietern gibt.
Die wichtigsten Szenarien in Bezug auf den Netzaufbau wären folgende:
- Nur SaaS: Kleinere Unternehmen nutzen möglicherweise ausschließlich SaaS-Anwendungen und keine IaaS-Anwendungen. Dies wäre für größere Unternehmen eher ungewöhnlich. Das Verschieben von Daten aus Salesforce in ein Snowflake Data Warehouse würde in diese Kategorie fallen.
- Nur Cloud: Neuere Unternehmen nutzen möglicherweise nur SaaS-Anwendungen mit einigen IaaS-Konten für benutzerdefinierte Anwendungen und haben keine lokalen Rechenzentren. Das Kombinieren von Daten aus einer RDS-Datenbank (auf die nur über das AWS-Konto des Kunden zugegriffen werden kann) mit NetSuite-Daten und das Erstellen eines Berichts würde in diese Kategorie fallen.
- Cloud und Erde: Die meisten Unternehmen verfügen über eine Kombination aus SaaS-Anwendungen, Anwendungen in der IaaS-Cloud und lokalen Anwendungen vor Ort. Größere Unternehmen verfügen möglicherweise über mehrere Rechenzentren, die geografisch verteilt sind, um Ausfallsicherheit zu gewährleisten und Mitarbeiter und Benutzer auf der ganzen Welt zu bedienen. Das Lesen von Daten aus einer lokalen SAP-Instanz und deren Zusammenführung mit Daten aus dem Redshift-Warehouse sowie das Schreiben der Ergebnisse in eine Oracle-Datenbank in einem anderen Rechenzentrum würde in diese Kategorie fallen.
Was die Integrationsanforderungen betrifft, so wäre das erste Szenario, Nur SaaS, am einfachsten zu erfüllen. Die Datenverarbeitung für diese Kategorie kann überall stattfinden, da die Endpunkte (SaaS-Anwendung) von überall aus erreichbar sind.
Das Cloud-Only-Szenario hängt von der Art der Anwendungen ab, die auf dem IaaS-Konto ausgeführt werden. Wenn ein Data Warehouse im Cloud-Konto ausgeführt wird und das Warehouse für das öffentliche Internet offen ist (gesichert durch Authentifizierungsmechanismen und nicht auf Netzwerkebene), kann die Datenverarbeitung überall ausgeführt werden. Bei benutzerdefinierten Anwendungen, die in der Cloud laufen und nicht über das öffentliche Internet erreichbar sind, muss die Datenverarbeitung im IaaS-Netz oder auf Knoten laufen, die das IaaS-Netz erreichen können.
Das Szenario " Cloud and Ground " ist im Hinblick auf die Integrationsanforderungen am komplexesten. Wenn in einem Anwendungsfall Daten zwischen einer in den USA-West laufenden Datenbank und einer in den USA-Ost oder in der Cloud laufenden Anwendung kombiniert werden müssen, besteht die Herausforderung der Integration darin, dass kein Knoten direkten Zugang zu allen erforderlichen Endpunkten hat.
iPaaS vs. traditionelle Integrationslösungen
Bei herkömmlichen Integrationslösungen werden Integrationswerkzeuge vor Ort installiert, die die Entwicklung von Datenverarbeitungspipelines ermöglichen. Dies bringt alle üblichen Herausforderungen mit sich, die mit lokalen Anwendungen verbunden sind, wie z. B. hohe Kosten für Wartung und Upgrades. Neben den üblichen Vorteilen des SaaS-Modells bietet iPaaS einige Vorteile gegenüber den vor Ort installierten Integrationstools
- Regelmäßige Updates: Auch wenn keine neuen Funktionen bereitgestellt werden müssen, muss die Integrationsplattform regelmäßig aktualisiert werden, um sicherzustellen, dass die Konnektoren zu den verschiedenen Endpunkten auf dem neuesten Stand sind und neue Konnektoren zur Verfügung stehen, was mit dem iPaaS-Modell einfacher ist.
- Benutzerfreundlichkeit: Die herkömmlichen Integrationstools erfordern in der Regel einen Fat Client und sind möglicherweise nicht für alle Benutzer im Unternehmen verfügbar. Das iPaaS-Modell mit browserbasierten Tools bedeutet, dass die Funktionalität für alle Endbenutzer verfügbar und benutzerfreundlich ist.
- Verteiltes Modell: Der iPaaS-Ansatz ermöglicht ein verteiltes Modell im Gegensatz zu dem zentralisierten Modell, das von herkömmlichen Integrationswerkzeugen verwendet wird. Dies ermöglicht eine einfache Handhabung von verteilten Integrationsszenarien wie dem oben beschriebenen Cloud- und Ground-Modell.
Verschiedene iPaaS-Produkte verfolgen unterschiedliche Ansätze, um die oben beschriebenen Herausforderungen zu lösen. Dieses Layout zeigt den von SnapLogic verfolgten Ansatz auf hoher Ebene.
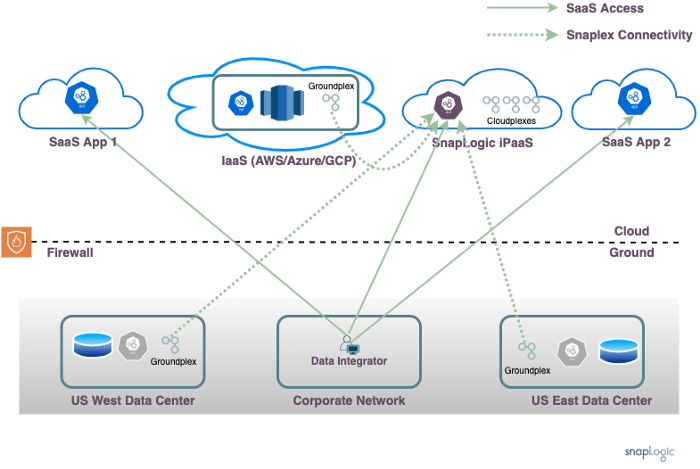
Der SnapLogic-Ansatz nutzt einen iPaaS-Dienst, der wie jeder andere SaaS-Dienst in der öffentlichen Cloud läuft. Alle Benutzerinteraktionen des Datenintegrators erfolgen über diesen Dienst. Die eigentliche Datenverarbeitung erfolgt auf dedizierten Datenverarbeitungsagenten, den sogenannten Snaplexes.
Beim Szenario " Nur SaaS " kann die gesamte Datenverarbeitung in der SnapLogic-Cloud erfolgen. Für die Datenverarbeitungsszenarien, die den Zugriff auf Daten auf dem IaaS des Kunden oder vor Ort erfordern, können Snaplex-Agentenprozesse bei Bedarf vor Ort installiert werden.
Dieser Ansatz geht auf die bereits erwähnten Probleme ein:
- Unternehmensnetzwerk: Der Datenintegrator arbeitet über das Unternehmensnetzwerk und interagiert nur mit der SnapLogic-Cloud. Der Pipeline-Entwicklungsprozess ermöglicht eine einfache Orchestrierung von Datenpipelines, die in einem beliebigen Rechenzentrum oder IaaS-Konto des Kunden laufen.
- Datenlokalisierung: Die Datenverarbeitung erfolgt auf dem Snaplex, der der Datenquelle am nächsten ist, was eine ortsbezogene Verarbeitung ermöglicht.
- Vor-Ort-Firewall: Die Snaplexe können hinter der Firewall des Kunden laufen und ausgehende Anfragen an die SnapLogic Cloud stellen. Es besteht keine Notwendigkeit, eingehende Firewall-Regeln zu öffnen.
- Isolierte Netzwerke: Die Orchestrierung von Pipelines, bei denen Daten aus einer Quelle in einem Rechenzentrum gelesen und mit Daten von einem anderen Standort kombiniert werden, wird durch das verteilte Modell erleichtert.
Die vor Ort installierten Snaplex-Agenten sind zustandslose Dienste, die sich bei Bedarf automatisch aktualisieren, indem sie mit der SnapLogic-Cloud kommunizieren. Da sie zustandslos sind, ist die Installation einfach, und es ist keine lokale Datenbank erforderlich, da der gesamte Status in der SnapLogic-Cloud verwaltet wird. Die Agenten verwenden ausgehende Verbindungen zur SnapLogic-Cloud, so dass keine Firewall-Regeln für den Zugriff geöffnet werden müssen.
Der SnapLogic-Ansatz ermöglicht den Einsatz einer einzigen Integrationsplattform im gesamten Unternehmen. Dadurch können Endbenutzer ganz einfach Datenpipelines erstellen und den Datenfluss zwischen lokalen und Cloud-Endpunkten orchestrieren, wodurch Datensilos innerhalb des Unternehmens aufgebrochen werden.