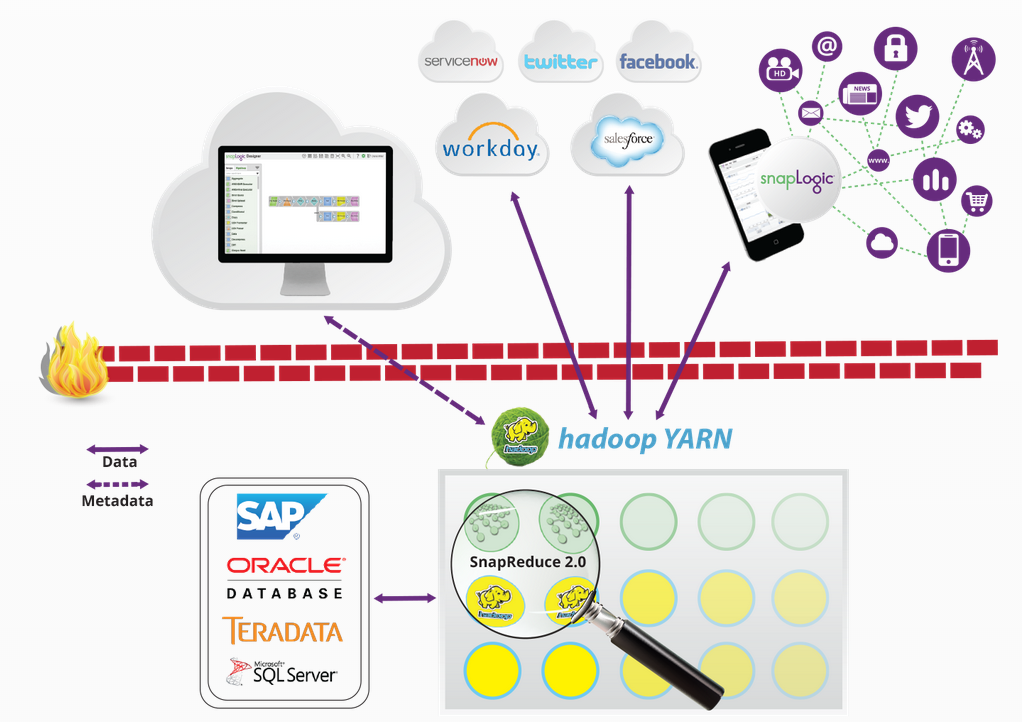
Diese Woche kündigte SnapLogic SnapReduce 2.0 an, das es der SnapLogic Elastic Integration Platform as a Service(iPaaS) ermöglicht, nativ auf Hadoop als YARN-verwaltete Ressource zu laufen, die elastisch skaliert und die Erfassung, Vorbereitung und Bereitstellung von Big Data erleichtert. Ich habe mich mit Greg Benson zusammengesetzt, der Professor für Informatik an der Universität von San Francisco ist und auch als Chief Scientist von SnapLogic arbeitet. Greg Benson forscht seit 20 Jahren auf den Gebieten verteilte Systeme, parallele Programmierung, Betriebssystemkerne und Programmiersprachen. Sein Team treibt die Innovation der Big Data-Integration von SnapLogic voran. Hier ist, was er über SnapReduce 2.0, YARN und die Möglichkeit für Kunden, von der softwaredefinierten Integrationsplattform von SnapLogic zu profitieren, zu sagen hat:
Was ist SnapReduce?
SnapReduce 1.0 machte sich Hadoop zunutze, indem es SnapLogic-Pipelines in Hadoop MapReduce-Jobs umwandelte. Diese umgewandelten Pipelines konnten ausschließlich mit vorhandenen Hadoop-Daten arbeiten. Diese Technologie war zwar leistungsfähig, eröffnete aber nicht die gesamte Bandbreite der Konnektivität von SnapLogic mit Hadoop. Mit YARN kann SnapLogic jetzt innerhalb von Hadoop ausgeführt werden und jede SnapLogic-Pipeline kann innerhalb eines Hadoop-Clusters ausgeführt werden.
SnapReduce 2.0 nutzt Ihre Investitionen in Hadoop, indem es Ihnen ermöglicht, Ihre Hadoop-Ressourcen für Integrationsaufgaben zusätzlich zu Ihren anderen Hadoop-Anwendungen zu nutzen. Integrationsaufgaben können nun je nach Bedarf auf die Kapazität Ihres Hadoop-Clusters skaliert werden. Darüber hinaus vereinfacht SnapReduce 2.0 die Erfassung und Bereitstellung von Hadoop-Daten mithilfe eines grafischen Designers und der Snap-Konnektivität mit einer Vielzahl von Anwendungen und Datenspeichern.
Was macht SnapReduce 2.0 einzigartig?
SnapReduce 2.0 ist einzigartig, weil es sowohl YARN-kompatibel als auch mit dem SnapLogic elastic iPaaS verbunden ist. Sie erhalten alle Vorteile der Ressourcennutzung und Skalierung von Hadoop und gleichzeitig den wartungsfreien Vorteil eines Cloud-Services. Darüber hinaus ist die native Unterstützung für hierarchische Dokumente ein wesentlicher Bestandteil von SnapLogic. Diese native Unterstützung kann genutzt werden, um JSON-Datendateien in HDFS sowie zeilenorientierte Datensätze nach Bedarf zu erstellen.
Welche Probleme werden mit SnapReduce 2.0 gelöst?
Wir sehen einige Kunden, die ihr Data Warehouse und ihren Langzeitspeicher in Hadoop verlagern wollen, weil es einen Kostenvorteil gegenüber proprietären Speicherprodukten bietet. Darüber hinaus beginnen die Kunden, die Analytik in Bezug auf Hadoop neu zu überdenken und wollen so viele Daten wie möglich mit ihrem Unternehmensdaten-Hub verbinden. Die Kunden sehen diesen Schritt als Gelegenheit, sich von ihren alten ETL-Fesseln zu lösen und auf eine moderne Plattform umzusteigen, die sowohl die Cloud als auch Big Data einbezieht.
Derzeit beschränken sich die gängigen Ansätze, Daten in Hadoop einzubringen, auf Flume für Protokolldaten, Scoop für relationale Daten und benutzerdefinierte Anwendungen für andere Arten von Daten. Jetzt wird alles, mit dem SnapLogic eine Verbindung herstellen kann, zu einer Datenquelle für Hadoop, z. B. Protokolldateien, relationale Daten, Anwendungen vor Ort und Cloud-Anwendungen. Ebenso können diese Datenquellen leicht zu Datenzielen werden. Wir machen Big Data elastisch, indem wir eine flexible Datenerfassung und -bereitstellung ermöglichen, sodass sie nicht mehr durch schwer einzurichtende und schwer zu verwendende Entwickler-Tools isoliert werden.
Wann wird SnapReduce 2.0 verfügbar sein?
Wie wir in der Pressemitteilung angegeben haben, ist die Verfügbarkeit in den nächsten Wochen geplant. Wir arbeiten derzeit mit den wichtigsten Hadoop-Vertriebspartnern an Zertifizierungen und haben ein Early-Access-Programm für einige unserer bestehenden Kunden und Interessenten mit aktiven Big-Data-Projekten gestartet. Auf der SnapLogic-Website können Sie mehr über SnapReduce 2.0 erfahren und sich für das Programm anmelden.
Das ist gut. Danke für das Update, Greg. Wir freuen uns darauf, bald mehr über diese und andere Big Data-Integrationsinitiativen von Ihrem Team zu hören!
Nächste Schritte:
- Erfahren Sie mehr über SnapReduce 2.0
- Das Elastic Data Integration Toolkit herunterladen
- Finden Sie heraus, wie wir Amazon Redshift Cloud-basierte Analysen betreiben
- Ein Video auf SnapTV ansehen
- Kontaktieren Sie uns , um Ihre Anforderungen an die Integration von Cloud und Big Data zu besprechen