 Herkömmliche Daten- und Anwendungsintegrationstechnologien wurden für eine Aufwärts- und nicht für eine Abwärtsskalierung entwickelt. Wie wir in unserem jüngsten Webinar mit iRobot erörtert haben, ist Elastizität eine Schlüsseleigenschaft von Cloud Computing, und wir bei SnapLogic glauben, dass dies eine wichtige Voraussetzung für eine Enterprise Integration Platform as a Service (iPaaS). Bisher wurden in dieser Reihe von Beiträgen über worauf es bei einer modernen Integrationsplattform ankommthaben wir über die Notwendigkeit einer voll funktionsfähiger Satz cloudbasierter Funktionen (und eine Software-definierte Architektur) und eine eine einzige Plattform für Anwendungen, Daten und API-Integrationsfälle. In diesem Beitrag gehen wir auf die Vorteile der iPaaS-Anforderung nach elastischer Skalierung ein. Das Gegenteil von elastisch ist "starr"Und das ist eine der größten Herausforderungen, mit denen alte Integrationstechnologien konfrontiert sind, wenn es darum geht, mit den heutigen sozialen, mobilen, analytischen, cloudbasierten und dem Internet der Dinge (SMACT) Anforderungen. Wenn wir angekündigt der SnapLogic Elastic Integration Platform im Jahr 2013 haben wir das Konzept der Drei-Wege-Elastizität eingeführt:
Herkömmliche Daten- und Anwendungsintegrationstechnologien wurden für eine Aufwärts- und nicht für eine Abwärtsskalierung entwickelt. Wie wir in unserem jüngsten Webinar mit iRobot erörtert haben, ist Elastizität eine Schlüsseleigenschaft von Cloud Computing, und wir bei SnapLogic glauben, dass dies eine wichtige Voraussetzung für eine Enterprise Integration Platform as a Service (iPaaS). Bisher wurden in dieser Reihe von Beiträgen über worauf es bei einer modernen Integrationsplattform ankommthaben wir über die Notwendigkeit einer voll funktionsfähiger Satz cloudbasierter Funktionen (und eine Software-definierte Architektur) und eine eine einzige Plattform für Anwendungen, Daten und API-Integrationsfälle. In diesem Beitrag gehen wir auf die Vorteile der iPaaS-Anforderung nach elastischer Skalierung ein. Das Gegenteil von elastisch ist "starr"Und das ist eine der größten Herausforderungen, mit denen alte Integrationstechnologien konfrontiert sind, wenn es darum geht, mit den heutigen sozialen, mobilen, analytischen, cloudbasierten und dem Internet der Dinge (SMACT) Anforderungen. Wenn wir angekündigt der SnapLogic Elastic Integration Platform im Jahr 2013 haben wir das Konzept der Drei-Wege-Elastizität eingeführt:
- Skalierung vor Ort, um Unternehmensanwendungen zu adressieren, die sich hinter der Firewall des Kunden befinden;
- Skalierung in der Cloud zur Integration von Daten aus Cloud/SaaS-Anwendungen; und,
- Der elastische Versand von Funktionen zwischen lokalen Systemen und der Cloud optimiert die Geschwindigkeit der Integrationsausführung, indem er die Daten zu den Daten bringt, anstatt die Daten zu den Daten zu schicken.
In einem Wired-Artikel beschrieb der Mitbegründer und CEO von SnapLogic, Gaurav Dhillon, den Vorteil der elastischen Integration folgendermaßen:
"Unternehmen werden immer Daten haben, die sich sowohl vor Ort als auch in der Cloud befinden. Die Kunst besteht darin, Daten über diese beiden Ebenen hinweg auf eine Art und Weise zu integrieren, die schnell, flexibel und skalierbar ist, so dass eine Vielzahl von Datentypen verarbeitet werden kann - große, relationale, halbstrukturierte oder unstrukturierte Daten - und auf verschiedene Arten bereitgestellt werden können, z. B. als Batch, ereignisbasiert oder als Streaming, indem Funktionen oder Daten beliebigen Volumens intelligent ausgeliefert werden - unabhängig davon, wo sich die Daten befinden, und zwar auf eine flexibel kontrollierte und verteilte Weise."
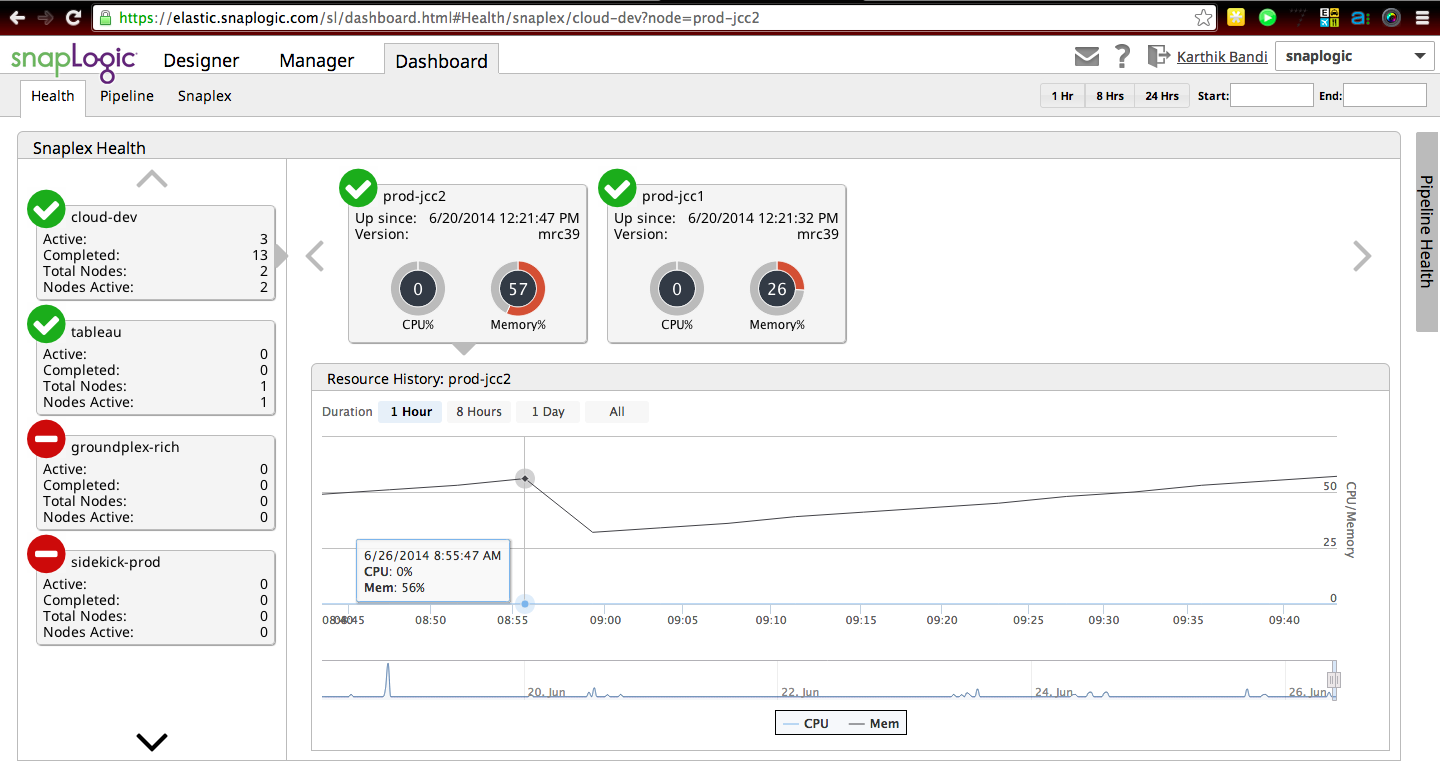
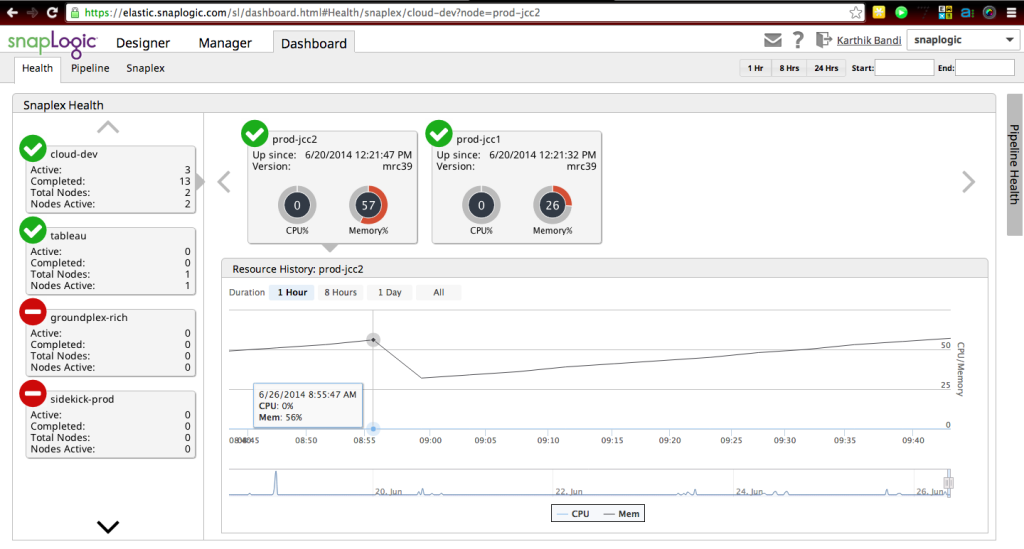
In einem kürzlich stattgefundenen SnapReduce 2.0 TechTalk erörterte Greg Benson, Chief Scientist von SnapLogic, wie immer mehr Datenmanagementaufgaben auf Hadoop laufen werden, einschließlich der Migration ihrer bestehenden Datenintegrationen und ETL-Aufgaben nach Hadoop, um sie in Hadoop-Skala auszuführen. Hier ist ein Screenshot eines SnapLogic-Dashboards, das den Zustand des Cloud-Integrationsservices überwacht und zeigt, wie das elastische Integrationsnetzwerk, Snaplex genannt, bei Bedarf an mehr Kapazität/Knoten skaliert. Wie wir in diesem Beitrag besprochen haben:
"Jeder Snaplex kann auf der Grundlage des durch ihn fließenden Datenverkehrs elastisch erweitert und verkleinert werden. Die Einheit der Skalierbarkeit innerhalb von Snaplex ist eine JVM. Die SnapLogic Integration Cloud verfügt über integrierte intelligente Funktionen zur automatischen Skalierung des Snaplex, um variable Datenverkehrslasten zu bewältigen. So wird beispielsweise jeder Snaplex mit einer vorkonfigurierten Anzahl von JVMs (z. B. einer) initialisiert. Sobald die Auslastung dieser einen JVM einen bestimmten Schwellenwert erreicht (z. B. 80 %), wird automatisch eine neue JVM hochgefahren, um die zusätzliche Arbeitslast zu bewältigen. Sobald der überschüssige Datenverkehr verarbeitet wurde und die zweite JVM nicht ausgelastet ist, wird sie wieder auf ihre ursprüngliche Größe verkleinert."
 Im nächsten Beitrag in dieser iPaaS-Anforderungsreihewerden wir über moderne Webstandards sprechen: REST und JSON.
Im nächsten Beitrag in dieser iPaaS-Anforderungsreihewerden wir über moderne Webstandards sprechen: REST und JSON.