





In einer McKinsey-Umfrage gaben 70 % der befragten Unternehmen an, dass sie in mindestens einer Geschäftseinheit die Automatisierung eingeführt haben. Diese Zahl ist gegenüber 66 % im Jahr 2020 und 57 % im Jahr 2018 gestiegen. Die IT-Automatisierung nimmt weiter zu, dank prozessagnostischer Software und Low-Code-Datenintegrationsplattformen, die branchenübergreifend eingesetzt werden können.
Bei der IT-Automatisierung werden manuelle und sich wiederholende Aufgaben, die sowohl von technischen als auch von nichttechnischen Mitarbeitern ausgeführt werden, durch Softwaresysteme ersetzt. Die Automatisierung setzt Ressourcen frei, ermöglicht eine schnelle Skalierung, verbessert die Effizienz und gibt Ihrem Team die Möglichkeit, sich auf strategischere und kreativere Aufgaben zu konzentrieren.
Zu den allgemeinen Schwerpunktbereichen der IT-Automatisierung gehören Kundenservice, Personalwesen, Automatisierung der Gehaltsabrechnung und Datensicherheit, aber das ist noch nicht alles. Auch die Datenmigration, der ETL-Prozess in einem Unternehmen und die Datenverwaltung im Allgemeinen können automatisiert werden, um große Datenmengen zu verarbeiten und die Datenqualität und -konsistenz zu verbessern. So geht's:
Automatisierung der Datenmigration
Die automatisierte Datenmigration macht den Prozess schneller und reibungsloser und stellt sicher, dass Ihre wichtigen Prozesse und Anwendungen während der Migration wie gewohnt funktionieren. Außerdem erhalten Sie eine bessere Kontrolle über die Datenqualität und verringern das Risiko menschlicher Fehler. Laut IDC gaben 28,9 % der Befragten aus aller Welt an, dass sie im Jahr 2021 in die Anwendungsentwicklung und -migration investieren werden - damit ist dies einer der fünf wichtigsten Bereiche der IT-Automatisierung.
Durch die Automatisierung der Datenmigration machen Sie den Prozess skalierbar und ermöglichen die Migration großer Datenmengen, ohne dass der Dienst unterbrochen werden muss. So können Sie beispielsweise Hunderttausende von XML-Dateien mit sich ständig ändernden Schemata migrieren, indem Sie ein System schaffen, das strukturelle Änderungen in den Dateien erkennt und sie einer neuen Datenbank zuordnet. Eine manuelle Migration von Dateien, die sich ständig ändern, kann äußerst schwierig, wenn nicht gar unmöglich sein.
Die Migration kann Daten von lokalen Servern in die Cloud, von der Cloud auf lokale Server und von mehreren Datenbanken in ein einziges Data Warehouse verschieben, um Silos zu beseitigen.
Die Migration von Anwendungen, wie z. B. der Wechsel von Quip zu Google Docs oder Auth0 zu Okta, ist auch eine Art von Datenmigration. Die Daten, die Sie mit Ihrer aktuellen Anwendung erstellt haben, oder die Daten, die von Ihrer aktuellen Anwendung verwendet werden, müssen noch in die neue Anwendung übertragen werden.
In einem Datenmigrationsprozess müssen Sie:
- Machen Sie sich mit dem aktuellen System und dem Zielsystem vertraut.
- Entscheiden Sie, ob Sie die gesamte Migration in einem Zug oder in Phasen durchführen wollen.
- Entwicklung der für die Migration erforderlichen Anwendung(en).
- Testen Sie die Anwendung(en).
- Führen Sie die Migration nach gründlichen Tests durch.
Es ist Schritt 3, der eine automatisierte Datenmigration von einer manuellen unterscheidet. Wenn Sie zum Beispiel von Mailchimp zu HubSpot wechseln, müssen Sie das tun:
- Laden Sie Ihre E-Mail-Datenbank als CSV-Datei von Mailchimp herunter
- Laden Sie die Datei in HubSpot hoch und ordnen Sie jede Spalte der Datei ihrem Gegenstück zu
- Gehen Sie zu HubSpot und richten Sie alle automatisierten Kampagnen ein, die Sie in Mailchimp hatten.
- Stellen Sie sicher, dass alle E-Mail-Auslöser, die in Mailchimp funktionieren, auch in HubSpot funktionieren.
Um auf diese Weise automatisierte Kampagnen einzurichten, müssen Sie Dutzende von E-Mail-Vorlagen von Mailchimp herunterladen und sie in ein für HubSpot akzeptables Format konvertieren. Oder Sie müssen neue Vorlagen von Grund auf neu entwerfen.
Das ist eine Menge manuelle Arbeit. Aus diesem Grund ist die manuelle Datenmigration nicht mehr so verbreitet. Um diese Migration zu automatisieren, müssen Sie ein Programm erstellen, das diese Aufgabe für Sie übernimmt, indem es alle Vorlagen von Mailchimp einliest und dann dieselben in HubSpot erstellt. Dazu muss das von Ihnen verwendete Programm/App in der Lage sein, sowohl mit Mailchimp als auch mit HubSpot zu kommunizieren.
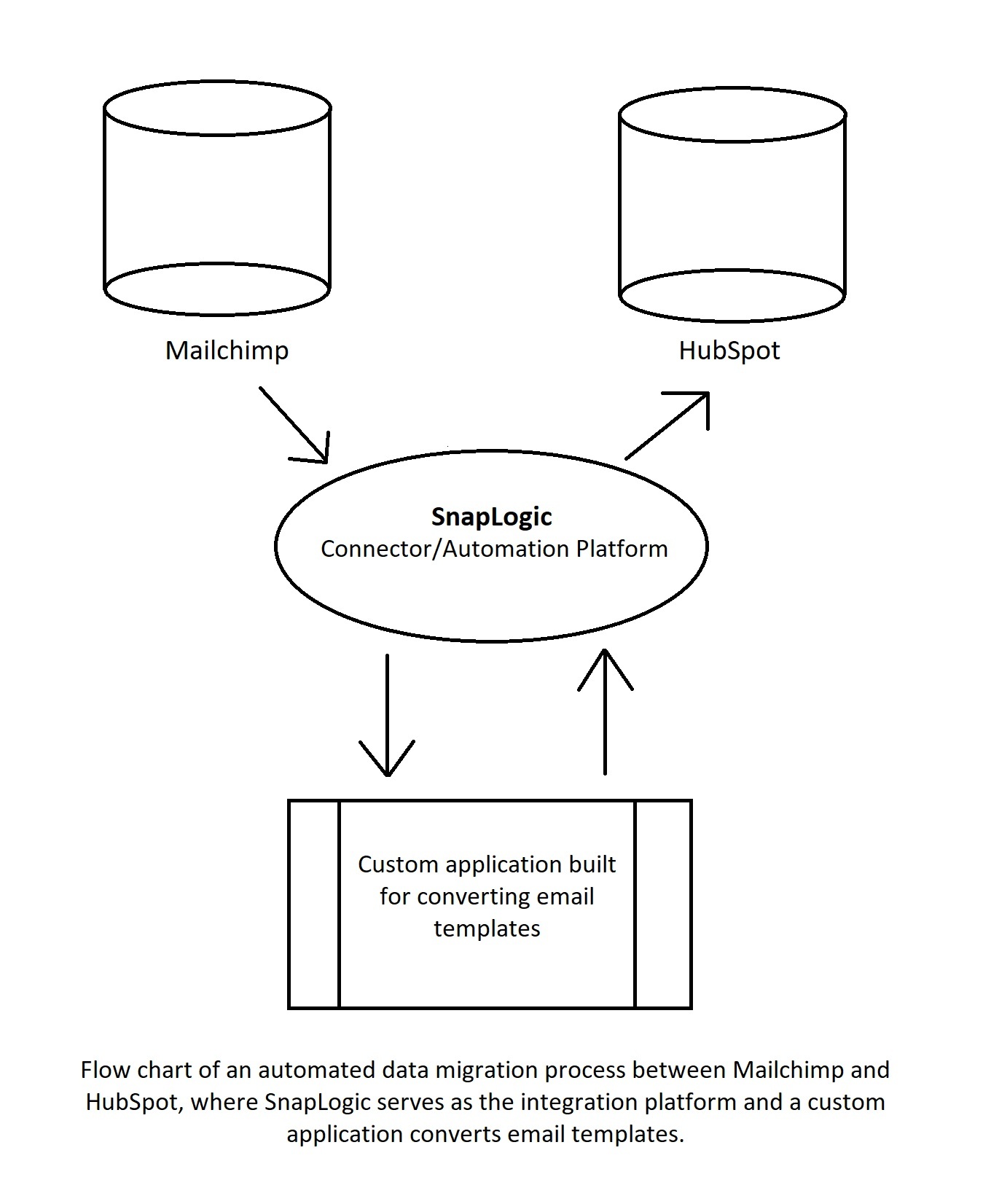
Im obigen Diagramm nimmt eine Konnektor-/Automatisierungsplattform Daten von Mailchimp auf und sendet sie an eine benutzerdefinierte Anwendung, die sie in ein für HubSpot akzeptables Formular umwandelt. Danach sendet die Plattform die Daten an HubSpot. Bei komplexeren Automatisierungen sind mehr Anwendungen und Prozesse involviert, aber die Verwendung einer Low-Code-Automatisierungsplattform hilft bei der Regulierung des Workflows und ermöglicht es verschiedenen Anwendungen, miteinander zu kommunizieren.
ETL-ELT-Automatisierung
Die Automatisierung des ETL-Prozesses spart wertvolle Ressourcen, da die Menge des Codes, den Sie zum Extrahieren, Transformieren und Laden von Daten schreiben müssen, minimiert wird.
Daten liegen in unterschiedlichen Strukturen und Schemata in den vielen verschiedenen Anwendungen und Datenbanken Ihres Unternehmens vor. Um den Wert dieser Daten wirklich zu erschließen, müssen sie extrahiert, umgewandelt und in ein zentrales Repository (z. B. ein Data Warehouse) geladen werden, wo sie für Geschäftseinblicke analysiert werden können.
Die Konfiguration eines ETL-Prozesses erfordert viel manuelle Codierung. Jede neue Datenquelle erfordert spezielle Anweisungen für die Verbindung und Extraktion der Daten. Sobald die Daten extrahiert sind, ist eine weitere Kodierung erforderlich, um die Daten ordnungsgemäß in ein Format umzuwandeln, das für das Zieldatawarehouse akzeptabel ist. Schließlich können die Daten zur Analyse in das Warehouse geladen werden. Jede neue Pipeline zur Übertragung von Daten in das Data Warehouse erfordert weiteren manuellen Aufwand.
Ein besserer Ansatz ist die Verwendung einer spezialisierten Low-Code-Integrationsplattform, um das Gleiche zu tun. Durch die Automatisierung des ETL-Prozesses und die Nutzung der Skalierbarkeit eines Cloud-Data-Warehouses können Sie den traditionell manuellen ETL-Ansatz effektiv in einen modernen ELT-Ansatz umwandeln. Bei diesem Ansatz wird die Datenextraktion und das Laden durch standardisierte Datenpipelines vereinfacht, während die Datentransformation innerhalb des Cloud Data Warehouse automatisiert wird.
Durch die Umstellung des Prozesses von ETL auf ELT wird der Ladevorgang erheblich beschleunigt, so dass Sie viel schneller zu qualitativ hochwertigeren Daten für die Geschäftsanalyse gelangen.
Automatisierung von Data Governance und Compliance
Die Automatisierung der Data Governance sorgt dafür, dass die Geschäftsanwender einen vollständigen Überblick über die Daten im Unternehmen erhalten - über ihren Speicherort, ihren Zweck, ihre Struktur und ihre Verwendung in verschiedenen Geschäftsprozessen. Die Automatisierung der Data Governance stellt auch sicher, dass Ihre Daten gesichert sind und nicht missbraucht werden.
Ein Data-Governance-Programm richtet sich an:
- Die Definitionen der einzelnen Datenpunkte
- Rolle und Zuständigkeiten der einzelnen Nutzer in Bezug auf Daten
- Die physischen und Online-Standorte der Datenquellen und -speicher
- Der Fluss und die Herkunft der Daten
- Die Regeln zum Erstellen, Manipulieren, Speichern, Abrufen, Ändern und Löschen von Daten.
Die Automatisierung von Data Governance bedeutet, den gesamten Weg der Daten durch Ihr Unternehmen abzubilden und die volle Kontrolle über alle Datenpipelines und -bestände zu erlangen.
In einem Unternehmen sind mehrere Datenpipelines im Spiel. Ein Interessent meldet sich beispielsweise für eine Produktdemo auf Ihrer Website an, wird einem Vertriebsmitarbeiter zugewiesen, nimmt an der Demo teil und wird schließlich zum Kunden. In jeder Phase dieses Prozesses wurden die Daten in einer anderen Anwendung verarbeitet, bevor sie in Ihrem Data Warehouse landeten.
- Der Interessent gab seine Kontaktinformationen in ein Formular ein und meldete sich für eine Demo an.
- Die Daten wurden aus dem Formular in die Marketing- oder Vertriebsanwendung übertragen und einem Vertriebsmitarbeiter zugewiesen.
- Der Benutzer nahm die Demo und kaufte das Produkt
- Der Datenpunkt, der den Benutzerstatus erfasst, wurde von "Interessent" auf "Kunde" geändert, und die Daten wurden in das Data Warehouse verschoben.
- Hätte der Nutzer das Produkt nach der Demo nicht gekauft, wären seine Daten an das Marketing-Tool für weitere Kampagnen zurückgegangen.
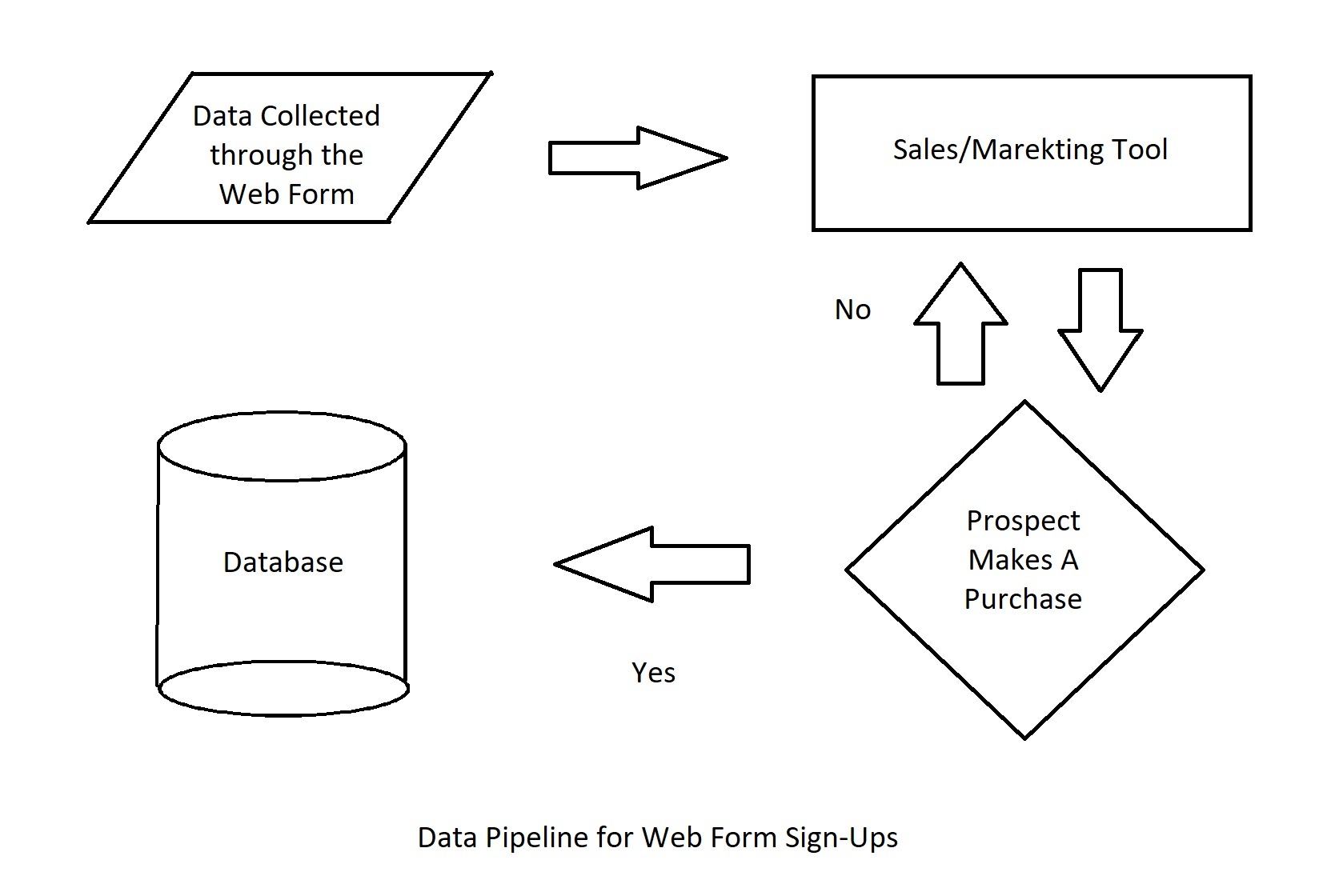
Die Automatisierung dieses Prozesses bedeutet, dass in keiner Phase ein menschliches Eingreifen erforderlich ist. Das Webformular sollte entweder durch direkte Integration oder mit Hilfe von Datenkonnektoren mit dem Vertriebs-/Marketinginstrument verbunden sein. Der Status sollte sich von selbst ändern, nachdem der Interessent das Produkt gekauft hat, und die Daten sollten an die Hauptdatenbank weitergeleitet werden, sobald sich der Status des Interessenten in den eines Kunden ändert.
Eine vollständige Automatisierung der Data Governance kann erreicht werden, wenn Workflows zur Sicherstellung der Datenqualität eingerichtet wurden und alle Prozesse (wie das obige Beispiel) wenig bis keine manuellen Eingriffe erfordern.
ML-Pipeline-Automatisierung
Automatisierung ermöglicht die Skalierung des maschinellen Lernens. Die Automatisierung der Pipeline für maschinelles Lernen führt zu einem schnelleren Iterationszyklus und einer besseren Leistungsüberwachung und -prüfung.
In einer automatisierten Pipeline für maschinelles Lernen werden die Datenextraktion, die Validierung, die Aufbereitung/Beschriftung, das Training des ML-Modells sowie die Bewertung und Validierung des Modells automatisiert. Die Automatisierung der ML-Pipeline ist heute ein Standardbestandteil des Trainings eines maschinellen Lernalgorithmus, da die manuelle Alternative weder skalierbar noch praktikabel ist.
Im Allgemeinen sind allein für den Prozess der Datenbeschriftung mehrere Personen erforderlich, die wochenlang (oder sogar monatelang, je nach Umfang des Projekts) Daten für maschinelle Lernalgorithmen beschriften. In einer automatisierten Pipeline für maschinelles Lernen ist jede Komponente der Pipeline kodifiziert.
- Datenextraktion - automatisiert durch intelligente Dokumentenverarbeitung, bei der intelligente Werkzeuge die Dokumente durchsuchen und die für das Projekt relevanten Daten extrahieren.
- Datenvalidierung - automatisiert durch in Programmiersprachen geschriebene Skripte oder spezielle Tools für die Datenvalidierung.
- Datenaufbereitung/Beschriftung - teilweise automatisiert durch aktives Lernen oder vollständig automatisiert durch programmatische Beschriftung.
- Training des ML-Modells - automatisiert mit Hilfe von SnapLogic's AutoML Snap.
- Bewertung und Validierung des ML-Modells - automatisiert mit Hilfe eines benutzerdefinierten Codes, der Testdaten an mehrere ML-Modelle weiterleitet.
Wenn jeder einzelne Schritt der Pipeline automatisiert ist, brauchen Sie nur noch Datenkonnektoren, um den Datenfluss von einem Prozess zum anderen zu ermöglichen, und die vollständige Automatisierung ist erreicht.
Erreichen Sie IT-Automatisierung mit SnapLogic
Wir leben im Zeitalter der Hyper-Automatisierung. Eine der größten Anforderungen für die Automatisierung von Data Governance, des ETL-Prozesses oder jeder Art von Datenmigrationsprozess ist die Möglichkeit, Workflows zu erstellen, die die Daten zwischen verschiedenen Anwendungen bewegen. Die Erstellung benutzerdefinierter Anwendungen zur Automatisierung erfordert einen hohen Programmier- und Entwicklungsaufwand. SnapLogic bietet eine Low-Code-Option, mit der Ihre Anwendungen miteinander kommunizieren können. Informieren Sie sich über die Datenintegrationsplattform von SnapLogic und erfahren Sie, wie sie Ihnen bei der IT-Automatisierung in Ihrem Unternehmen helfen kann.
Suchen Sie nach weiteren Informationen über Datenintegration und Automatisierung? SnapLogic hat den ultimativen Leitfaden zur Datenintegration für Sie erstellt.






