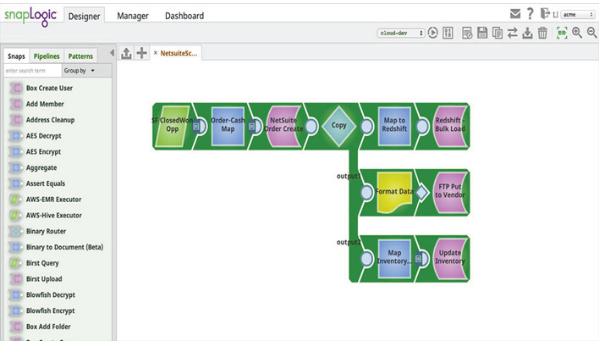
SnapLogic bietet eine Big-Data-Integrationsplattform als Service (iPaaS) für Geschäftskunden zur einfachen, intuitiven und leistungsstarken Datenverarbeitung. SnapLogic bietet eine Reihe von verschiedenen Modulen, die Snaps genannt werden. Ein einzelner Snap bietet eine bequeme Möglichkeit, Daten zu erhalten, zu manipulieren oder auszugeben, und jeder Snap entspricht einer bestimmten Datenoperation. Alles, was der Kunde tun muss, ist, die entsprechenden Snaps zusammenzuziehen und zu konfigurieren, wodurch eine Datenpipeline entsteht. Kunden führen Pipelines aus, um bestimmte Datenintegrationsflüsse zu verarbeiten.
SnapLogic Spark Snap-Skript: Einführung
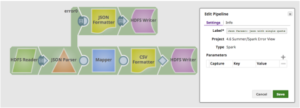
Mit dem Spark-Script-Snap können Kunden die Funktionalität der SnapLogic-Plattform für die Verarbeitung von Spark-Jobs erweitern, indem sie entweder benutzerdefinierte Skripte für ihre eigene Geschäftslogik hinzufügen, die nicht Teil der umfangreichen SnapLogic-Standardsammlung sind, oder vorhandene Skripte wiederverwenden. Das SnapLogic-System führt das Spark Script Snap als separaten Spark-Job aus. Grundsätzlich erlaubt der Spark Script Snap dem Kunden, Spark-Skripte innerhalb des SnapLogic Designers zu schreiben.
Der Spark-Skript-Snap unterstützt auch die Übergabe von Spark-Eigenschaften an das Spark-Python-Skript über Umgebungsvariablen. Dadurch können Benutzer wiederverwendbare Spark-Skripte und Konfigurationen erstellen, z. B. App-Name, Speichergröße und Spark-Master.
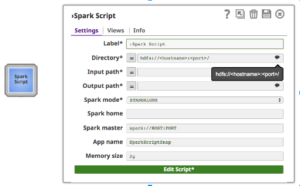
Eigenschaften:
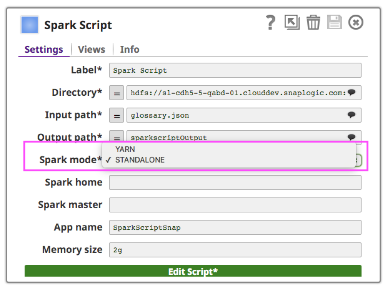
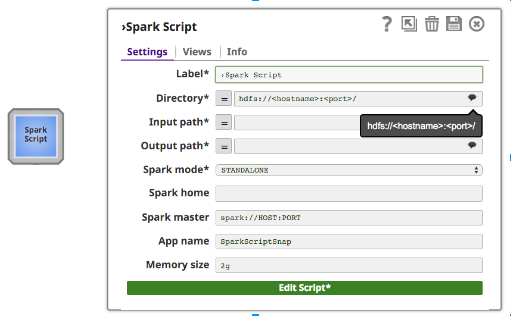
Zusätzlich zu den normalen Snap-Feldern bietet das Spark-Skript Snap Vorschläge für hdfs "Verzeichnis", "Eingabepfad" und "Ausgabepfad". Das Feld "Verzeichnis" zeigt nur das Verzeichnis an, aber "Eingabepfad" und "Ausgabepfad" können sowohl Dateien als auch Verzeichnisse anzeigen.
Um Spark Script Snap auf einem Cluster auszuführen, können Kunden zwischen zwei Arten von Clustermanagern wählen (entweder der eigenständige Clustermanager von Spark oder YARN), der die Ressourcen auf die Anwendungen verteilt.
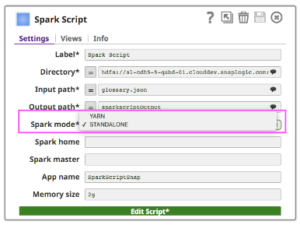
- Standalone - ein einfaches Clustermanagement, das mit dem Spark-Ökosystem verbunden ist
- Hadooop YARN - der Ressourcenmanager im Hadoop-Ökosystem
Wenn Sie den Standalone-Modus verwenden, geben Sie die Master-URL in das Master-Feld ein und setzen Sie Master in Ihrem Spark-Skript oder lassen Sie es leer. Wenn Sie den YARN-Modus verwenden, ist es nicht erforderlich, Master festzulegen.
Das Feld "Spark home" ist optional. Wenn es leer ist, verwendet Spark Script Snap den Standardwert "Spark home", d. h. den Pfad, in dem Kunden Spark in ihrem Cluster installiert haben. Andernfalls können Benutzer ihr Cluster-Spark-Stammverzeichnis angeben.
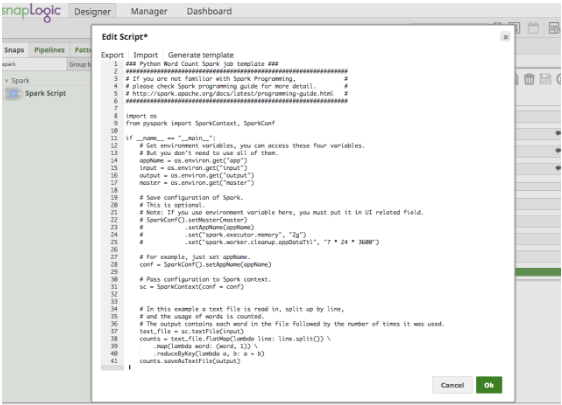
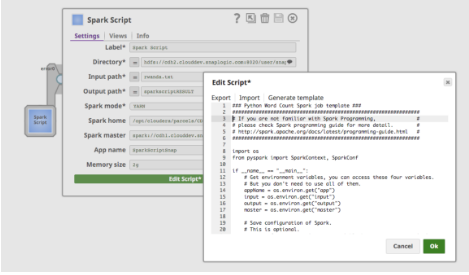
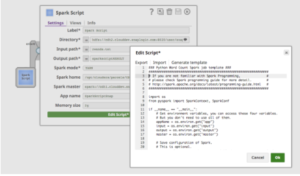
Wenn Sie auf "Skript bearbeiten" klicken, stellt der Spark-Skript-Snap eine Vorlage für die Ausführung des Wordcount-Beispiels bereit. Es enthält auch Hinweise zur Verwendung von Umgebungsvariablen, wie Abbildung 4 zeigt. Ein Benutzer kann das Skript direkt im Feld bearbeiten oder ein Skript einfügen, das von einem Data Scientist-Kollegen bereitgestellt wurde.
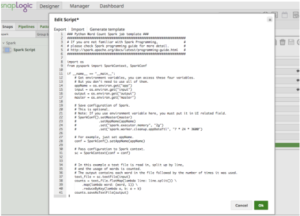
Links
Ein Schritt-für-Schritt-Demonstrationsvideo zum Spark Script Snap finden Sie hier.
Es gibt viele Informationen über SnapLogic Big Data-Integration und integrierte Cloud-Services finden Sie auf unserer Website, ebenso wie Big-Data-Integration-Blogbeiträge, iPaaS-Informationen, und Whitepapers.