







Es gibt keine KI ohne Daten. Und das Mai-Release der SnapLogic-Plattform beschleunigt Ihre Fähigkeit, Daten zu nutzen, um Ihr Unternehmen mit GenAI-Anwendungen zu transformieren. Mit dieser Version können Sie:
- Verbindung zu Fundamentmodellen von Anthropic Claude und zu einer weiteren Vektordatenbank: MongoDB Atlas Vektorsuche
- Verwalten Sie alle Integrationen und Metadaten von einem Ort aus mit dem neuen Integrationskatalog
- Einfaches Laden und Umwandeln von Daten mit neuen AutoSync-Funktionen und Endpunktunterstützung, Parquet-Datei-Flattening usw.
- Nutzung unterschiedlicher Daten an mehr Stellen, z. B. Unterstützung für GeoSpatial-Daten in SQL Server
- Automatisierung der Lebenszyklen von API- und Plattforminfrastrukturen mit mehr öffentlichen APIs
Und so viel mehr. Lassen Sie uns in diese Updates eintauchen!
Mehr unterstützte LLMs und VectorDB-Unterstützung im GenAI Builder
Die neueste Version des GenAI Builders fügt Unterstützung für Foundation-Modelle von Anthropic Claude als Teil des Amazon Bedrock LLM Snap Packs hinzu. Sie können jedes Modell von Anthropic Claude nutzen und daraus Nachrichtenantworten generieren. Mit dieser Fähigkeit können Sie GenAI-Anwendungen erstellen, die die Mitarbeiterproduktivität verbessern, Kunden mit einem besseren Serviceerlebnis unterstützen, das Partnererlebnis verbessern und vieles mehr.
Schauen Sie sich dieses Video an, in dem gezeigt wird, wie Sie mit Anthropic Claude Workflows für Ihre GenAI-Anwendungen erstellen können.
Wir fügen auch Unterstützung für eine neue Vektordatenbank, MongoDB Atlas Vector Search, hinzu, um Sie bei der Erstellung von GenAI-Anwendungen zu unterstützen. Wenn Sie die MongoDB Atlas Vector Search-Datenbank verwenden, können Sie sie mit Ihren GenAI-Apps verbinden. Mit dem MongoDB Atlas Vector Search Snap können Sie fortgeschrittene vektorbasierte Abfragen durchführen, wie z.B. Ähnlichkeitssuchen, Approximate Nearest Neighbor (ANN) Abfragen, Bereichsabfragen, etc. Sie können jetzt Retrieval Augmented Generation KI-Assistenten mit Ihren Unternehmensdaten erstellen, die in MongoDB Atlas Vector Search gespeichert sind.
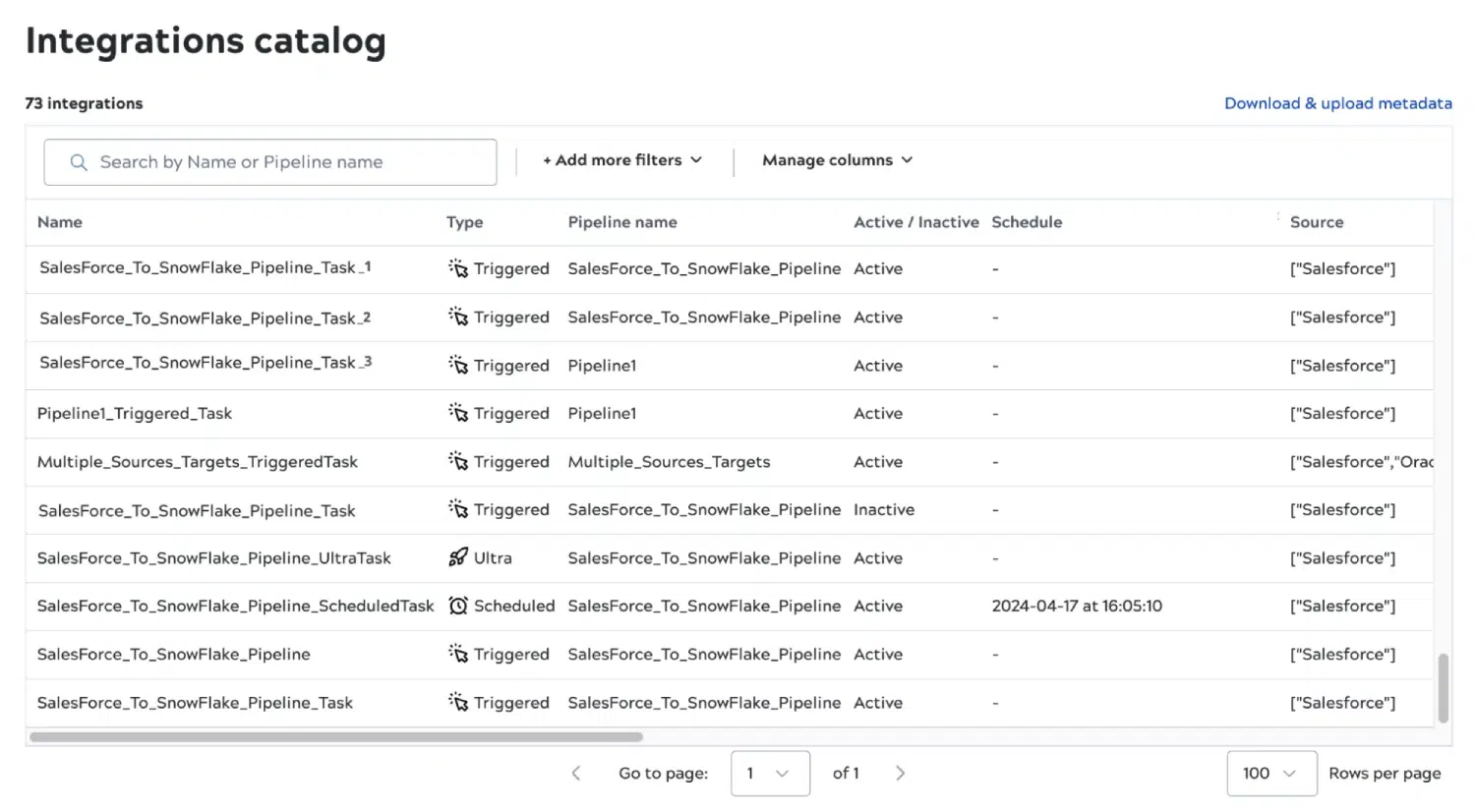
Alle neuen Integrationskataloge
Wir freuen uns sehr, mit dieser Version einen brandneuen Integrationskatalog einführen zu können, der Ihnen eine einheitliche Übersicht über alle Ihre Integrationen und die zugehörigen Metadaten bietet. Der Katalog bietet Ihnen ein Verzeichnis aller Integrationen und ermöglicht es Teams, Integrationen einfach zu finden, zu verstehen und zu verwalten. Mithilfe des Katalogs können Sie Ihre Integrationslandschaft nach Geschäftsbereichen und Anwendungen aufschlüsseln, Pipelines anhand der Endpunkte identifizieren, mit denen sie verbunden sind, und die Kosten für Integrationen für neue und bestehende Workflows reduzieren. Sie können auch leicht nachverfolgen, was die einzelnen Pipelines tun, so dass Sie bestehende Integrationen für neue Workflows nutzen und so die Integrationszeit reduzieren können.
Der Integrationskatalog stellt Metadaten zur Verfügung, die sonst nirgendwo auf der Plattform zu finden sind, z. B. Eigentümer, Zeitplan und Snap Count. Eine weitere wichtige Funktion ist die Möglichkeit, benutzerdefinierte Metadaten hinzuzufügen. Mit benutzerdefinierten Metadaten können zentrale IT-Teams Integrationen auf Geschäftsprozesse abbilden, um die Betriebskosten zu senken oder die mittlere Wiederherstellungszeit (MTTR) zu verbessern. Darüber hinaus können sie die benutzerdefinierten Metadaten nutzen, um Berichte über verbundene Anwendungen und Datenendpunkte zu erstellen und potenzielle Systemrisiken zu verstehen.
Benutzer können benutzerdefinierte Metadaten für Integrationspipelines hochladen und auch Metadaten exportieren, um diese in einen Datenkatalog eines Drittanbieters zu integrieren.
Erfahren Sie mehr über den Integrationskatalog in diesem Demo-Video.
Verbesserte Operationen und Datenumwandlungen in AutoSync
SnapLogic AutoSync hat in den letzten Monaten einen großen Zuwachs an Fähigkeiten erhalten. Neben dem HTTPClient Source Connector, mit dem Sie Daten von praktisch jedem Endpunkt mit einer RESTFul-API beziehen können, bietet diese Version neue Zielendpunkte wie Databricks, Amazon S3, Azure Data Lake Storage (ADLS) Gen2.
AutoSync bietet jetzt neue Funktionen, mit denen Sie eine Pipeline mitten in der Ausführung anhalten können. Da das Anhalten einer Pipeline jedoch die Datenintegrität beeinträchtigen kann, empfehlen wir, dies nur als letzten Ausweg zu nutzen und eine vollständige Ladung durchzuführen, wenn Sie dazu bereit sind.
Die Plattform ermöglicht es Ihnen jetzt auch, die Endpunkte einer AutoSync-Pipeline nahtlos zu aktualisieren. Dies spart Ihnen über die gesamte Lebensdauer einer AutoSync-Pipeline hinweg Tage an Arbeit, da Sie dieselbe Pipeline nicht mehr von Grund auf neu aufbauen müssen.
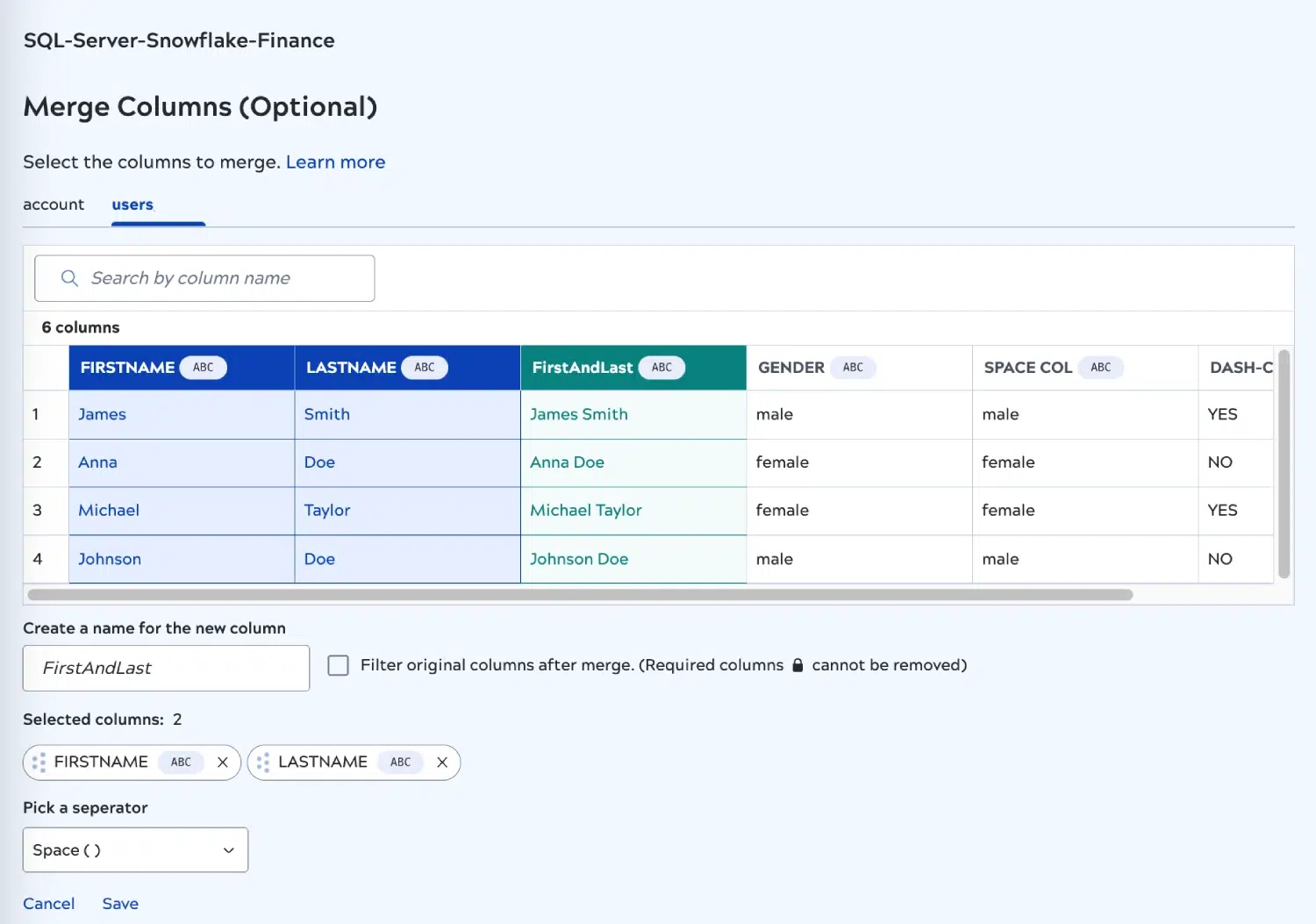
Mit der Mai-Version werden auch neue Transformationsfunktionen eingeführt. Mit der neuen Funktion "Merge Column" können Sie nun mehrere Spalten vom Typ "String" miteinander verknüpfen. Dies wird Ihnen helfen, die Datenstrukturen im Ziel zu vereinfachen, was zu einer effizienten Speicherung und schnelleren Abfrageantwort führt.
Bessere Behandlung von Parkettdaten in ELT
Kunden, die Parquet-Dateien über ELT-Workloads in ein Cloud-Data-Warehouse wie Snowflake laden möchten, können jetzt verschachtelte Datensätze einfach verwalten. Die ELT-Ladefunktion ermöglicht es jetzt, die eingehenden Daten zu reduzieren. Diese Funktion ermöglicht eine effizientere Vorverarbeitung, was die Verarbeitungszeit und die Kosten innerhalb des Cloud Data Warehouse reduziert.
Snap-Updates
Die Mai-Version bringt viele Verbesserungen für unsere Snap Packs. Hier ist eine Zusammenfassung der wichtigsten Updates:
Snowflake Snap Pack: Die Mai-Version fügt den Bulk Load und Insert Snaps des Snowflake Snap Packs Unterstützung für die beliebten Apache Iceberg Tables hinzu. Iceberg-Tabellen partitionieren die Daten über mehrere Knoten, um die Datenverarbeitung zu beschleunigen, und sind daher bei der Benutzergemeinschaft sehr beliebt. Die Funktion befindet sich in Snowflake in der Vorschau, aber wir wissen, dass viele von Ihnen sie bereits übernommen haben. Mit dieser Erweiterung können Sie nun SnapLogic-Pipelines nutzen, um Iceberg-Tabellen zu erstellen und zu manipulieren.
SQL Server Snap Pack: GeoSpatial Data ist für den Einzelhandel, Supply Chain und die Versicherungsbranche von entscheidender Bedeutung. Aufgrund der Kundennachfrage haben wir Microsoft SQL Server Snap Pack um Unterstützung für GeoSpatial Data (sowohl Geographie als auch Geometrie) erweitert. Mit dieser Unterstützung können Sie GeoSpatial-Daten in Microsoft SQL Server einfügen, lesen und auswählen.
MongoDB Snap Pack: Wir fügen dem MongoDB Snap Pack MongoDB Execute Snap hinzu, damit Sie beliebige Data Definition Language (DDL)- und Data Manipulation Language (DML)-Befehle auf der MongoDB-Datenbank ausführen können.
NetSuite Snap Pack: Mai-Updates für das NetSuite Snap Pack fügen jetzt neue Snaps hinzu, um Datensätze in Massen zu verschieben. Add List Snap ermöglicht es Ihnen, neue Datensätze in NetSuite in Massen hinzuzufügen. Ein ähnlicher Async Add List fügt diese Datensätze asynchron hinzu, d.h. er gibt eine Job-ID an den Benutzer zurück. Der Prozess wird im Hintergrund abgeschlossen, und Sie können den Auftragsstatus überprüfen, um zu sehen, ob die Datensätze hinzugefügt wurden.
Automatisieren Sie Ihren API-Lebenszyklus und Ihre SnapLogic-Infrastruktur
Mit der Mai-Version fügen wir mehrere öffentliche APIs hinzu, damit Sie den Lebenszyklus von APIs mit CI/CD-Tools genau so automatisieren können, wie Sie den Lebenszyklus Ihres Codes oder Ihrer Pipelines verwalten. Mit den neuen öffentlichen APIs können Sie einen Zweig erstellen, eine API-Version erstellen, einen Zweig auschecken, die letzten Änderungen ziehen, ein Git-Tag setzen, den Repo-Status prüfen, Änderungen verwerfen und einen Zweig zurückziehen. Wenn Sie APIs für Ihre internen oder externen Kunden entwickeln, können Sie davon ausgehen, dass Sie mit diesen öffentlichen APIs jede Woche Stunden an mühsamer Handarbeit einsparen.
Die neuen öffentlichen APIs ermöglichen auch das sanfte Löschen von APIs und API-Versionen. Die APIs landen dann in einem Papierkorb, anstatt für immer gelöscht zu werden. Dies spart API-Managern Zeit durch Skalierung und schafft eine bessere Nutzererfahrung mit der Möglichkeit, Löschungen bei Bedarf rückgängig zu machen.
Neue öffentliche APIs ermöglichen es, einen Groundplex zu erstellen, zu aktualisieren und zu löschen, um eine Infrastruktur für vorübergehende Tests oder Staging-Initiativen zu erstellen, bevor Änderungen in die Produktion übernommen werden. Eine weitere öffentliche API ermöglicht es Ihnen, lokale Änderungen zu verwerfen, damit sie nicht vom GIT-Repository verfolgt werden.
Verbesserte Sicherheit für Proxy-Endpunkte
Sie können jetzt eine JWT-Richtlinie zu ihren Proxy-Endpunkten hinzufügen, die im API-Manager verwaltet werden. Der Benutzer kann eine ausgehende JWT-Richtlinie (JSON Web Token) konfigurieren, um eine zusätzliche Authentifizierungs- und Sicherheitsebene zu seinen APIs hinzuzufügen.
Eine weitere Verbesserung ermöglicht es Ihnen, einem Proxy-Endpunkt mehrere Richtlinien zur Kontoverknüpfung hinzuzufügen, z. B. Outbound Basic Auth und Outbound OAuth, wobei beide Richtlinien in der richtigen Reihenfolge angewendet werden. Zuvor wurde die erste Richtlinie ignoriert. Diese Änderung ermöglicht es dem Benutzer, mehrere Kontoverbindungsrichtlinien in einem Proxy/Proxy-Endpunkt zu haben. Diese Änderung gilt für alle ausgehenden Authentifizierungsrichtlinien.
Wenn Sie mehr über die Mai-Version erfahren möchten, lesen Sie bitte die Versionshinweise oder kontaktieren Sie das Customer Success Team.





