Kürzlich habe ich mit einem Kunden zusammengearbeitet, um ein Pig-Skript, das einen MapReduce-Job in Hadoop ausführt, zurückzuentwickeln und es dann als SnapReduce-Pipeline mit der Elastic Integration Platform von SnapLogic zu orchestrieren. Die cloudbasierte HTML5-Designer-Benutzeroberfläche von SnapLogic und die Sammlung vorgefertigter Komponenten, Snaps genannt, ermöglichten es, eine visuelle und funktionale Darstellung des Datenanalyse-Workflows zu erstellen, ohne die Feinheiten von Pig und MapReduce zu kennen. Hier ist eine kurze Zusammenfassung:
Was ist die Pig Scripting Language?
Pig-Skript ist eine High-Level-Skriptsprache, die mit Apache Hadoop verwendet wird, um komplexe Anwendungen zur Lösung von Geschäftsproblemen zu erstellen. Pig wird für interaktive und Batch-Aufträge mit MapReduce als Standardausführungsmodus verwendet.
Über SnapReduce und den Hadooplex
SnapReduce und unser Hadooplex ermöglichen es dem iPaaS von SnapLogic, nativ auf Hadoop als YARN-Anwendung zu laufen, die elastisch skaliert, um Big-Data-Analysen durchzuführen. Mit SnapLogic können Hadoop-Benutzer die Vorteile einer HTML5-basierten Drag-and-Drop-Benutzeroberfläche, einer breiten Palette an Konnektivität (Snaps genannt) und einer modernen Architektur nutzen. Erfahren Sie hier mehr.
Allgemeiner Anwendungsfall (Produktnutzungsanalyse)
Rohdaten zur Produktnutzung aus Verbraucheranwendungen werden in Hadoop HCatalog-Tabellen geladen und im RCFile-Format gespeichert. Das Programm liest Datenfelder: Produktname, Benutzer und Nutzungshistorie mit Datum und Uhrzeit, bereinigt die Daten und eliminiert doppelte Datensätze, die nach Zeitstempel gruppiert werden. Es findet eindeutige Datensätze für jeden Benutzer und schreibt die Ergebnisse auf der Grundlage von Datum/Uhrzeit in HDFS-Partitionen. Produktanalysten erstellen dann eine externe Tabelle in Hive auf den bereits partitionierten Daten, um Produktnutzungs- und Trendberichte abzufragen und zu erstellen. Diese Berichte werden in eine Datei geschrieben oder in ein visuelles Analysetool wie Tableau exportiert.
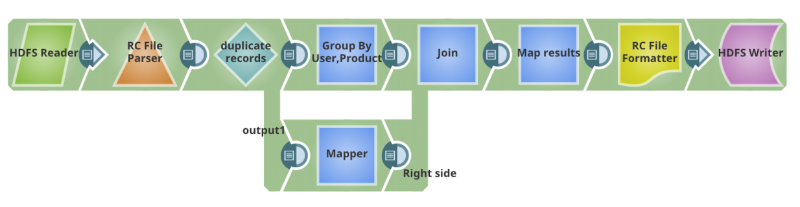
Hier ist der Pig-Script-Teil für den obigen Anwendungsfall (Bereinigung von Daten):
REGISTER / apps / cloudera / parcels / CDH / lib / hive / lib / hive - exec.jar SET default_parallel 24; DEFINE HCatLoader org.apache.hcatalog.pig.HCatLoader(); raw = load
'sourcedata.sc_survey_results_history' USING HCatLoader(); in = foreach raw generate user_guid, survey_results, date_time, product as product; grp_in = GROUP in BY(user_guid, product); grp_data = foreach grp_in { order_date_time = ORDER in BY date_time DESC; max_grp_data = LIMIT order_date_time 1; GENERATE FLATTEN(max_grp_data); }; grp_out_data = foreach grp_data generate max_grp_data::user_guid as user_guid, max_grp_data::product as product, '$create_date' as create_date, CONCAT('-"product"="', CONCAT(max_grp_data::product, CONCAT('",', max_grp_data::survey_results))) as survey_results; results = STORE grp_out_data INTO 'hdfs://nameservice1/warehouse/marketing/sc_surSnapReduce Pipeline-Äquivalent für das Pig-Skript
Diese SnapReduce-Pipeline wird so übersetzt, dass sie als MapReduce-Auftrag in Hadoop läuft. Sie kann geplant oder ausgelöst werden, um die Integration zu automatisieren. Sie kann sogar in ein wiederverwendbares Integrationsmuster umgewandelt werden. Wie Sie sehen werden, ist es ziemlich einfach und intuitiv, eine Pipeline mit SnapLogic HTML5 GUI und den Snaps zu erstellen, um ein Pig-Skript zu ersetzen.
Der obige Anwendungsfall für die Datenanalyse wurde vollständig in SnapLogic erstellt. Ich habe hier nur den Pig-Skript-Teil behandelt und plane, zu einem späteren Zeitpunkt über den Rest des Anwendungsfalls zu schreiben. Ich hoffe, dies hilft Ihnen! Hier sehen Sie eine Demonstration unserer Big Data-Integrationslösung in Aktion. Kontaktieren Sie uns, um mehr zu erfahren.