Mittlerweile kennen wir alle den Anstieg der generierten und für ein Unternehmen verfügbaren Datenmenge und die Probleme, die dadurch entstehen können. Es ist abzusehen, dass ein Ende des Daten-Tsunamis nicht in Sicht ist, was zum großen Teil auf die zunehmende Vielfalt von Daten aus mobilen, sozialen Medien und IoT-Quellen zurückzuführen ist.
Es ist also keine Überraschung, dass Unternehmen in Daten ertrinken. In einer kürzlich durchgeführten Umfrage des unabhängigen Marktforschungsunternehmens Vanson Bourne wurde festgestellt, dass bis zu 80 Prozent der Befragten der Meinung sind, dass ältere Technologien ihr Unternehmen daran hindern, die Vorteile datengesteuerter Möglichkeiten zu nutzen. In der gleichen Umfrage wurde auch festgestellt, dass nur 50 Prozent der gesammelten Daten für geschäftliche Erkenntnisse analysiert werden. In Verbindung mit der Tatsache, dass Unternehmen immer schneller Erkenntnisse aus den Daten gewinnen müssen, ist dies ein Rezept für eine Katastrophe oder bestenfalls für potenzielle Umsatzeinbußen.
Um die Daten zu sammeln und zu analysieren, um verborgene Geschäftseinblicke zu erhalten und eine datengesteuerte Kultur zu schaffen, benötigen Unternehmen Tools, die es Dateningenieuren und Geschäftsanwendern mit Fachwissen ermöglichen, in dieser Umgebung effizienter zu arbeiten, ohne dass sie über tiefgreifende technische Kenntnisse verfügen müssen.
Der Aufstieg der Big-Data-Technologien
Um alle Arten von Daten zu sammeln und zu analysieren, setzen Unternehmen weiterhin auf Big-Data-Technologien und bauen zunehmend Cloud-basierte Data Lakes auf. Dadurch können sie die Vorteile der Cloud nutzen, wie z. B. deutlich geringere Investitionskosten.
Der Betrieb der Big-Data-Umgebung ist jedoch oft eine Herausforderung, da spezielle Fähigkeiten für die Installation, Konfiguration und Wartung der Umgebung erforderlich sind. Sobald die Umgebung einsatzbereit ist und die Mitarbeiter bereit sind, ihr Projekt in Angriff zu nehmen, benötigen sie Spark-Entwickler, die den Code für die Durchführung der Data-Engineering-Aufgaben schreiben. Als Nächstes müssen sie einen Mechanismus für die Übermittlung von Spark-Pipeline-Jobs an den Verarbeitungscluster entwickeln. Sobald dies erledigt ist und die Mitarbeiter die Vorteile der vorübergehenden Fähigkeit nutzen möchten, die Big Data as a Service (BDaaS)-Cluster bieten, müssen sie ihr Lebenszyklusmanagement entwickeln.
All dies erfordert viele Hunderte, wenn nicht Tausende von Codezeilen, die komplex und fehleranfällig sind und deren Erstellung normalerweise Monate dauert. Gleichzeitig besteht eine hohe Nachfrage nach Spark-Entwicklern, und es gibt insgesamt einen enormen Mangel an diesen Talenten.
Wenn Big Data auf eXtreme trifft
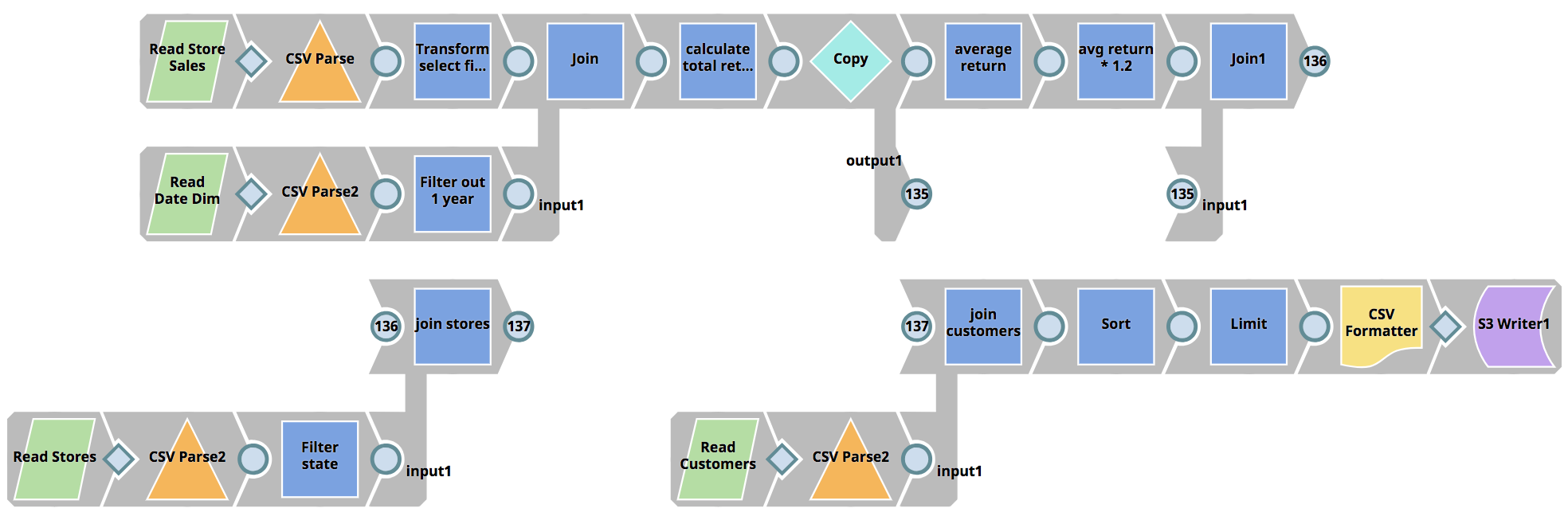
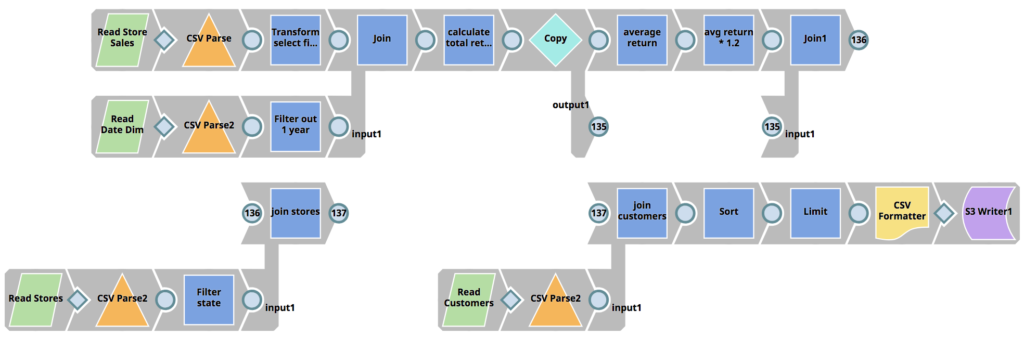
SnapLogic eXtreme adressiert den Fachkräftemangel im Bereich der Datentechnik, indem es die Enterprise Integration Cloud und ihr visuelles Design-Paradigma verbessert, das es Unternehmen ermöglicht, Spark-Pipelines zu erstellen, ohne dass Spark-Jobs in Scala, Python oder Java geschrieben werden müssen, wodurch die erforderlichen Fähigkeiten drastisch reduziert werden. Ein Projekt, das normalerweise mehrere Entwickler und mehrere Monate in Anspruch nehmen würde, kann auf nur wenige Stunden reduziert werden.
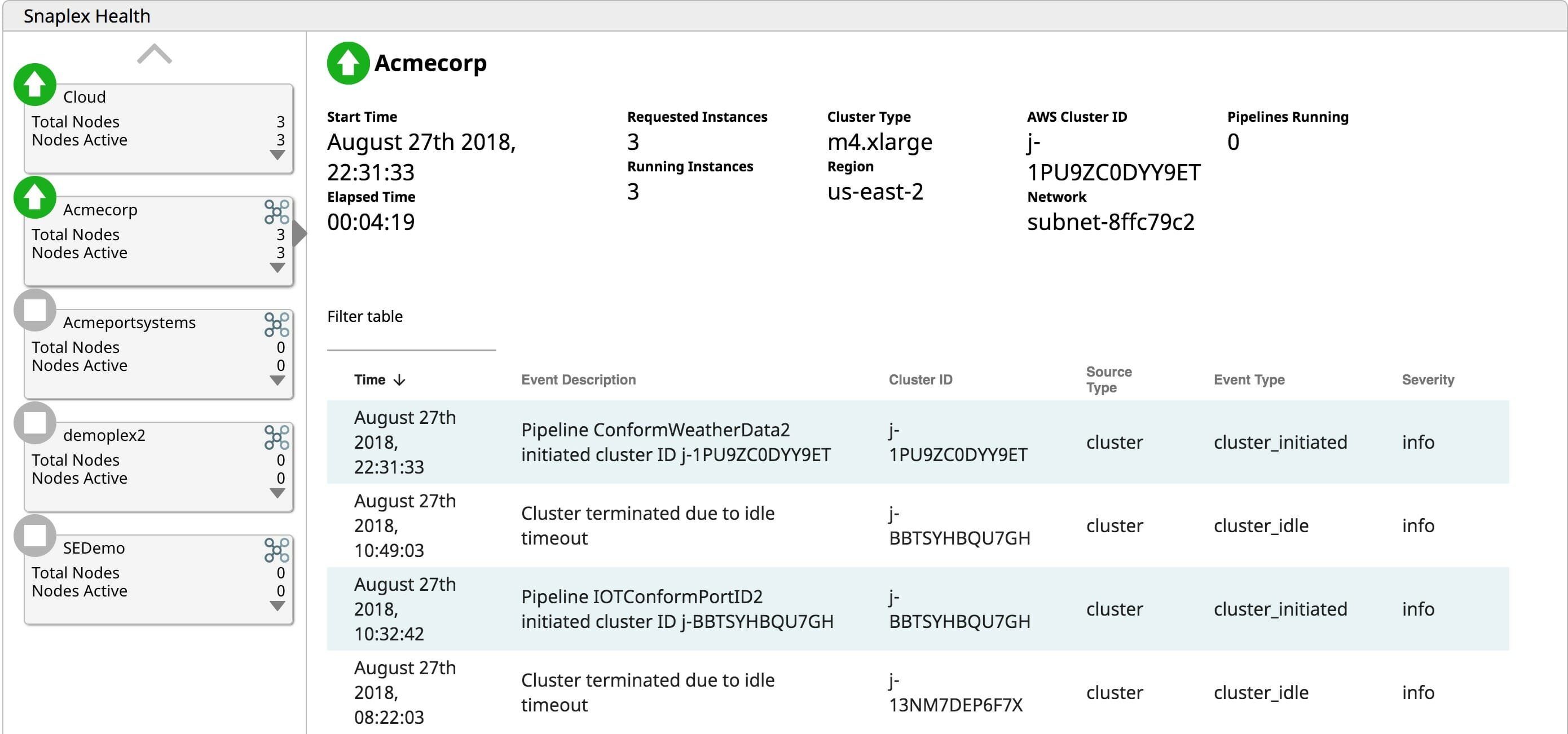
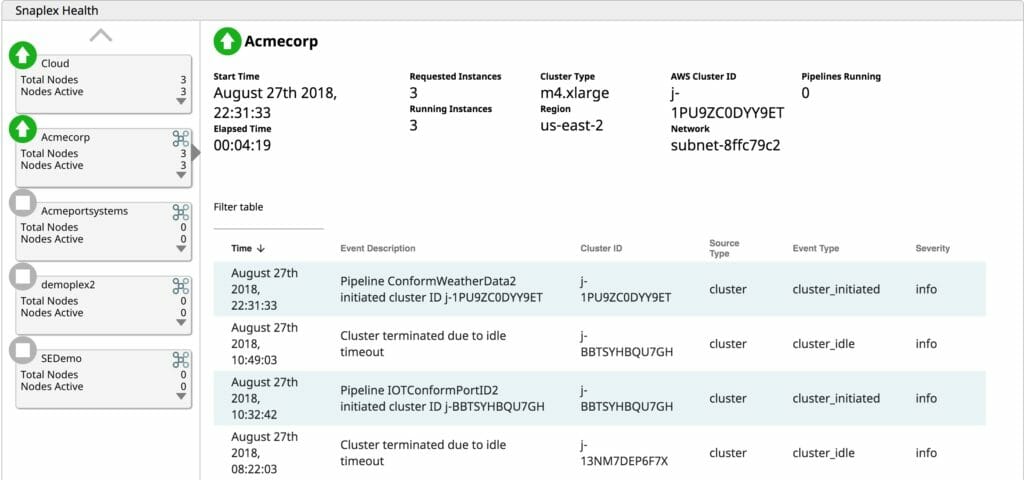
Durch die Lebenszyklusmanagementfunktion von SnapLogic eXtreme können Benutzer Cluster bei Bedarf in Betrieb nehmen, wenn die Verarbeitung erforderlich ist. Wenn keine Aufträge ausgeführt werden müssen, sind die Kosten für einen ungenutzten Cluster nur verschwendete Betriebskosten. SnapLogic eXtreme skaliert Cluster bei Bedarf elastisch, wenn die Verarbeitung ansteigt. Dank der elastischen Skalierungsfunktion müssen Cluster nicht mehr für Spitzenlasten dimensioniert werden. Durch die bedarfsgerechte Erhöhung der Verarbeitungskapazität zahlen Unternehmen nur für das, was sie tatsächlich nutzen, und vermeiden so die Verschwendung von Betriebskosten für ungenutzte Server. Und schließlich beendet eXtreme laufende Cluster, wenn keine Aufträge mehr anstehen, die verarbeitet werden müssen. Warum für den Betrieb von Servern zahlen, wenn sie keinen Mehrwert für das Unternehmen bringen? Die Bereitstellung einer vollständig verwalteten, automatisierten Cloud-basierten Big Data-Laufzeitumgebung spart Unternehmen wertvolle Betriebskosten.
Big Data-Initiativen erhalten Hilfe
Die Funktionen von eXtreme sorgen für Schnelligkeit und Agilität in einem Unternehmen. SnapLogic eXtreme ermöglicht es Unternehmen, mit weniger Ressourcen mehr zu erreichen, da es eine visuelle Designoberfläche bietet. Dank der Self-Service-Funktionen können technische Geschäftsanwender Initiativen schneller auf den Markt bringen und schnell aussagekräftige Erkenntnisse gewinnen, was in der heutigen schnelllebigen Umgebung von entscheidender Bedeutung ist. Schließlich prognostiziert Forrester, dass "bis zum Jahr 2021 erkenntnisgesteuerte Unternehmen ihren Konkurrenten, die nicht erkenntnisgesteuert sind, jährlich 1,8 Billionen US-Dollar an Umsatz entziehen werden."
Der kontinuierliche Anstieg des Datenvolumens und der Datenvielfalt sowie die Analyse dieser Daten, um verborgene Geschäftserkenntnisse zu gewinnen, lassen keine Anzeichen einer Abschwächung erkennen. Big-Data-Technologien bieten zwar die richtigen Werkzeuge für diese Aufgabe, stellen jedoch eine anspruchsvolle Betriebsumgebung dar, die spezielle, schwer zu findende Fähigkeiten erfordert, um erfolgreich zu sein. SnapLogic eXtreme bietet die Möglichkeit, die Zeit, die Ressourcen und das Fachwissen zu reduzieren, die für den Aufbau und den Betrieb von Big Data-Architekturen in der Cloud erforderlich sind. Wenn Ihr Unternehmen mit seiner Big-Data-Initiative zu kämpfen hat, sollten Sie sich SnapLogic eXtreme ansehen.