






Die wichtigsten Erkenntnisse
- KI ist überall, aber mit einem hohen Risiko des Scheiterns
- Einfacher Zugang zu Daten ist der Schlüssel zum Erfolg mit KI
- Die Datenintegration muss auf die Unternehmensziele abgestimmt sein
Schaffung der Voraussetzungen
Das SnapLogic-Team war auf dem Gartner Data & Analytics Summit in London vertreten. Dies ist eine der besten Veranstaltungen des Jahres für hochwertige Gespräche, bei denen die Teilnehmer in der Regel Menschen mit spezifischen Zielen und Problemen sowie der Bereitschaft und den Ressourcen sind, diese zu lösen.
Wir sahen diesen Bedarf an konkreten Lösungen gleich in der Eröffnungsrede, als Adam Ronthal und Alys Woodward ihre Erkenntnis mitteilten, dass sich die Reife von Daten und Analysen um 30 % positiv auf die finanzielle Leistung auswirkt. Governance und Management werden jedoch im Vergleich zu eher technischen Metriken immer noch unterbewertet.
Erfolgreiche Unternehmen überarbeiten jedoch ihre Herangehensweise an das Data Storytelling und an die D&A-Metriken, um sich stärker am Geschäft zu orientieren. Dieses verstärkte Engagement für das Geschäft wird ein wiederkehrendes Thema während der drei Konferenztage sein - und ist natürlich etwas, das wir bei SnapLogic seit langem mit unserem Low-Code/No-Code-Ansatz zur Integration befürworten.
Ein weiteres Thema, das (wenig überraschend) auf der Konferenz allgegenwärtig war, war KI - und auch hier lautete die Empfehlung, Projekte sowohl auf ihre Durchführbarkeit als auch auf ihren geschäftlichen Nutzen zu prüfen. Die technische Erprobung der Machbarkeit von KI ist in unserer Branche bereits weit fortgeschritten.
Gartner berichtet, dass 75 % der CEOs laut der "2023 CEO Survey Research Collection and Midyear Update AI Findings" bereits GenAI ausprobiert haben - aber 53 % glauben, dass sie nicht in der Lage wären, mit den Risiken von AI umzugehen. Prominente Beispiele für das Scheitern waren Microsofts Tay und der Reiseberatungs-Chatbot von Air Canada.

Die Schlussfolgerung ist, dass der Mangel an KI-fähigen Daten eine der größten Herausforderungen für den Erfolg von GenAI-Implementierungen ist. Genau dieses Problem löst SnapLogic mit einer leistungsstarken und omnivoren Datenintegrationsplattform, die sicherstellt, dass die Daten verfügbar sind, und dem GenAI Builder-Toolkit, das den Endnutzern einen einfachen Zugang zu ihnen ermöglicht.
Datengewebe
Diese technologische Grundlage fällt unter den Begriff "Data Fabric", der in einem interessanten Vortrag von Michele Launi diskutiert wurde. Er machte deutlich, dass es sich bei Data Fabric nicht um ein einzelnes Tool oder Produkt handelt, das in einem Schritt beschafft und eingesetzt werden kann - aber die Datenintegration ist eine Schlüsselkomponente, und genau dabei kann SnapLogic helfen. Unser Low-Code/No-Code-Entwicklungsmodell geht auch auf eine der größten Herausforderungen bei der Einführung von Data Fabric ein, nämlich den Mangel an Fachkräften.
Die Bereitstellung von Daten als Teil eines Data-Fabric-Ansatzes bedeutet, dass die Plattform eine Vielzahl von Datenarten unterstützen muss, von traditioneller ETL über Reverse ETL und ELT bis hin zu Streaming, und zwar sowohl für strukturierte als auch für unstrukturierte Datentypen. All diese und weitere Themen kamen in Gesprächen mit den Besuchern am SnapLogic-Stand und während der Messe zur Sprache.
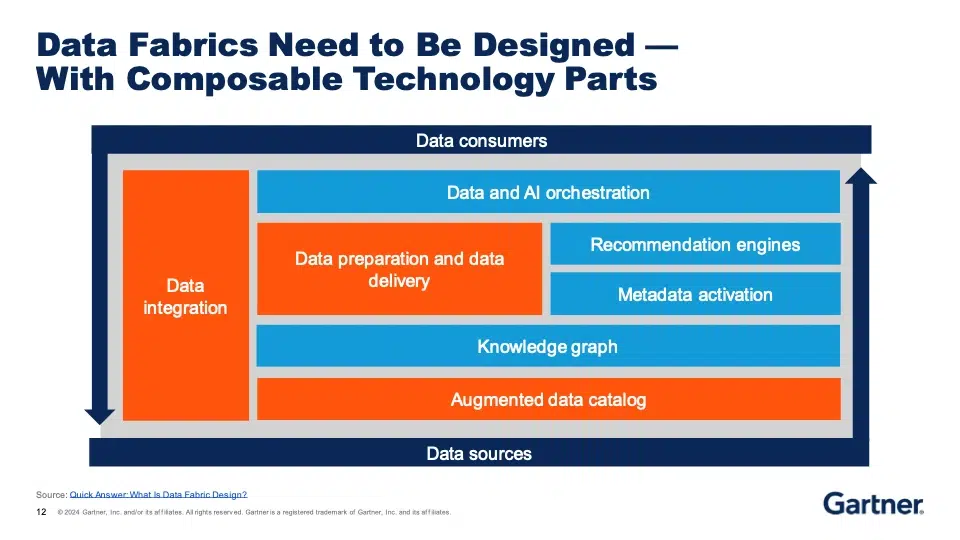
Michele erwähnte auch, dass viele IT-Führungskräfte insbesondere erwarten, dass die Automatisierung den Aufwand für die gemeinsame Nutzung von Daten verringert. Die Einsparungen in diesem Bereich sind real und werden durch die Erfahrungen von SnapLogic-Kunden auf der ganzen Welt bestätigt. Wir stimmen aber auch mit Michele überein, dass ein echter Wert entsteht, wenn diese Daten in einen Kontext gestellt werden - und zwar in den Kontext des Unternehmens.
Dieser Self-Service-Ansatz erfordert ein gewisses Maß an Aufmerksamkeit für die Operationalisierung und Governance - etwas, das mein Enterprise Architect-Team bei SnapLogic darauf konzentriert, unseren Kunden durch unser Sigma Framework for Operational Excellence bei der Implementierung zu helfen.
Das Thema der organisatorischen Reife kam später in der Sendung in einem Gespräch zwischen Mark Beyer und Robert Thanaraj über die manchmal verwirrenden Überschneidungen zwischen den verwandten Konzepten der "Datenstruktur" und des "Datengeflechts" wieder auf. Insbesondere teilten sie ihre Erkenntnis mit, dass Unternehmen bis zu 94 % ihrer Zeit mit der Aufbereitung von Daten verbringen und daher nur zwischen 6 % und 17 % ihrer Zeit damit verbringen, die mühsam gesammelten Daten tatsächlich für ihre Geschäftszwecke zu nutzen.
Um diese Reibung zu minimieren, empfehlen sie einen iterativen Planungsansatz, der angesichts der unvermeidlichen Veränderungen mehr Flexibilität ermöglicht. Diese Flexibilität bedeutet, dass die Verantwortung und Steuerung beim Unternehmen liegen muss, da die IT zu weit nachgelagert ist; technische Spezialisten liefern die Plattform, aber die Unternehmen sind für das tatsächliche Ergebnis verantwortlich.
Gartner schätzt, dass nur wenige Unternehmen den Reifegrad haben, um diesen Kulturwandel zu vollziehen. Das Modell von SnapLogic ermöglicht jedoch die schnelle Iteration, die der Schlüssel zum Erfolg ist, und legt sie direkt in die Hände von Fachexperten, wodurch der Bedarf an IT-Spezialisten reduziert wird und die Vorteile dieses Ansatzes auch Unternehmen zugute kommen, die auf der Reifekurve von Gartner weiter unten stehen.
KI - aber wie? Und warum?
Ich habe es geschafft, noch nicht zu viel über KI zu sprechen, aber wie bereits erwähnt, war das Thema während der Konferenz allgegenwärtig und wurde ausdrücklich als Ziel für einen Großteil der Datenerfassungs- und Integrationsaktivitäten beschrieben. Das große Problem ist jedoch, dass weniger als die Hälfte der KI-Projekte jemals in die Produktion gehen - und dieses Verhältnis ist bei der generativen KI sogar noch schlimmer, denn laut Gartner schaffen es weniger als 10 % bis zum Ende.
Aus diesem Grund hat Sumit Agarwal unverblümt festgestellt, dass die generative KI vom derzeitigen Gipfel der überhöhten Erwartungen in den Tiefpunkt der Desillusionierung fallen wird.
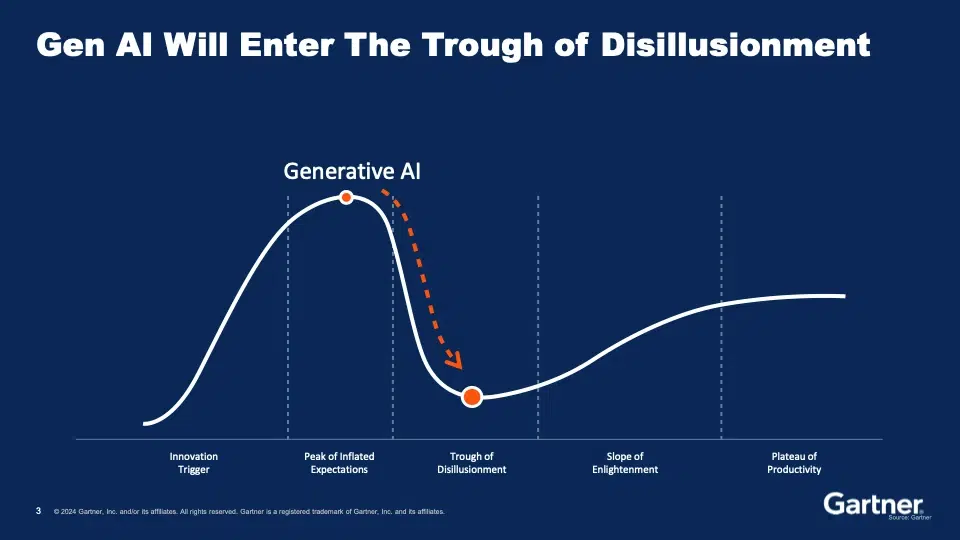
Ich stimme Sumit zu, dass der einzige Weg aus der Talsohle darin besteht, den Wert von KI-Projekten nachzuweisen, und zwar in großem Maßstab. Aus diesem Grund bietet SnapLogic das GenAI Builder Toolkit an. Durch die Minimierung des Abstands zwischen den Daten und den Geschäftsanforderungen ermöglicht der GenAI Builder von SnapLogic den Anwendern eine schnelle Prototypisierung und Bereitstellung von Diensten, die die Leistungsfähigkeit von GenAI unter Verwendung der wertvollen Daten des Unternehmens nutzen, und zwar sicher und in großem Umfang.
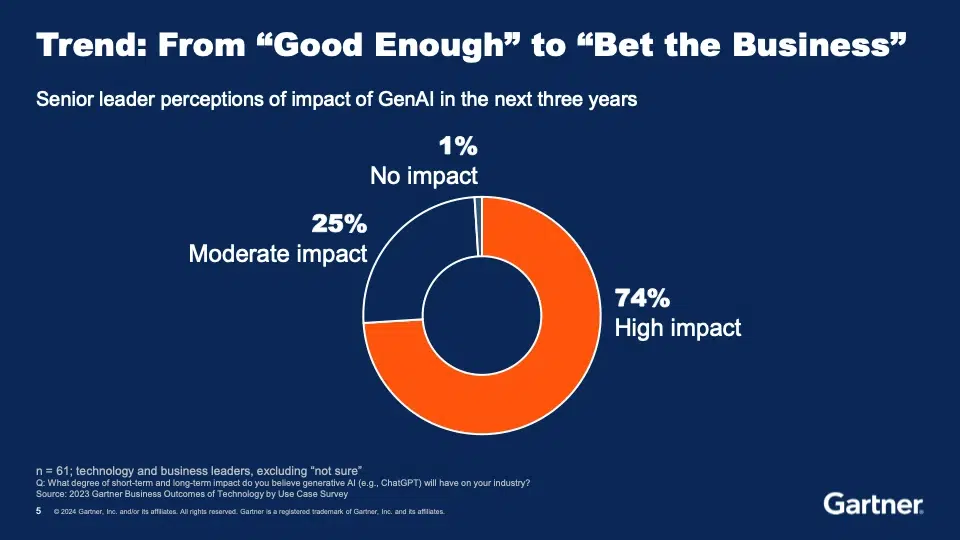
Der Wert dieses Ansatzes wurde von Gareth Herschel in der abschließenden Keynote des zweiten Tages unterstrichen: "KI baut auf dem Fundament der bereits vorhandenen Datenarchitektur auf." Die Solidität des Fundaments ist besonders wichtig, denn KI ist ein "Bet the Business"-Moment, bei dem Erfolg oder Misserfolg enorme Auswirkungen auf die Zukunft haben werden.
SnapLogic und Syngenta
Soviel zu den allgemeinen Themen - aber Analystenprognosen und Quadranten haben nur ein begrenztes Gewicht. Der wahre Beweis liegt in den echten, praktischen Kundengeschichten. Deshalb war ich sehr froh, dass ich die Gelegenheit hatte, Maks Shah, Head of R&D Data Platforms bei Syngenta, auf der Bühne in einem Auditorium mit tausend Zuhörern zu interviewen.
Die Unternehmensziele von Syngenta sind so konkret wie kaum ein anderes Unternehmen: Es geht um nichts Geringeres als die sichere Ernährung der Welt und den Schutz unseres Planeten. Die digitale Wissenschaft stellte sie jedoch vor eine Herausforderung: lange Zeiten bis zur Erkenntnis, ein nicht nachhaltiges Betriebsmodell und Probleme mit der Datenqualität. Die externen Zwänge, denen die Forschung und Entwicklung von Syngenta ausgesetzt ist, sind erheblich. Wenn bei einem Feldversuch etwas schief geht oder die Ergebnisse nicht schlüssig sind, muss man ein Jahr warten, bis die nächste Anbausaison beginnt und die Schädlinge für die betreffende Kulturpflanze wieder auftreten, damit man das Experiment wiederholen kann.
Dank SnapLogic haben die Datenwissenschaftler von Syngenta nun einen schnelleren Zugriff auf über 300 interne und über 100 externe Datenquellen. Sie nehmen sowohl strukturierte als auch halbstrukturierte Daten im Batch- und Streaming-Modus auf, je nach den genauen Anforderungen der jeweiligen Quelle. Diese nahtlose Integration trägt bereits Früchte, unter anderem bei folgenden Projekten:
- Integration von Altanwendungen in moderne Anwendungen zur Vereinfachung der Datenintegrationslandschaft
- Entkopplung der bestehenden ereignisgesteuerten Architektur und Übergang zu einer flexibleren und zukunftssicheren Microservices-Architektur
- API-Verwaltung zur Ermöglichung von Self-Service-Integration
Wir freuen uns auf die weitere Zusammenarbeit mit Syngenta, mit unseren anderen Kunden in den Biowissenschaften und vielen anderen Branchen sowie mit all den neuen Freunden, die wir bei Gartner D&A gewonnen haben. Wenn Sie unseren Stand auf der Messe besucht haben, bedanken wir uns und werden uns bald wieder melden. Und wenn Sie es verpasst haben, aber mehr über das, was Sie gerade gelesen haben, erfahren möchten, würden wir uns gerne mit Ihnen darüber unterhalten, wie SnapLogic Ihnen helfen kann, Datensilos aufzulösen und Konnektivität in Ihr Unternehmen zu bringen.






