






![]()
In der heutigen Geschäftswelt ist Big Data in aller Munde. Neben dem Durchsuchen, Speichern und Skalieren von Daten sticht vor allem eines hervor: die Stream-Verarbeitung. Und genau hier kommt Apache Kafka ins Spiel.
Kafka kann auf einer hohen Ebene als ein Publish-and-Subscribe-Messaging-System beschrieben werden. Wie jedes andere Nachrichtensystem verwaltet Kafka Nachrichtenfeeds in Topics. Erzeuger schreiben Daten in Topics und Verbraucher lesen Daten aus diesen Topics. Der Einfachheit halber habe ich hier auf die Kafka-Dokumentation verlinkt.
In diesem Blog-Beitrag werde ich einen einfachen Anwendungsfall demonstrieren, bei dem Twitter-Feeds an ein Kafka-Thema gesendet und die Daten in Hadoop geschrieben werden. Im Folgenden finden Sie eine detaillierte Anleitung, wie Benutzer Pipelines mit der SnapLogic Elastic Integration Platform erstellen können.
In der Frühjahrsversion 2016 führte SnapLogic Kafka-Snaps sowohl für Produzenten als auch für Konsumenten ein. Kafka-Reader ist der Kafka-Consumer-Snap und Kafka-Writer ist der Kafka-Producer-Snap.
SnapLogic-Pipeline: Veröffentlichung eines Twitter-Feeds in einem Kafka-Thema
Um diese Pipeline zu erstellen, benötige ich einen Twitter-Snap, um Twitter-Feeds abzurufen und diese Daten in einem Thema in der Datenbank zu veröffentlichen. Kafka Writer Snap (Kafka-Produzent). Wählen wir ein Thema, z. B. "Regionen", und konfigurieren wir den Kafka Writer Snap so, dass er in dieses Thema schreibt.
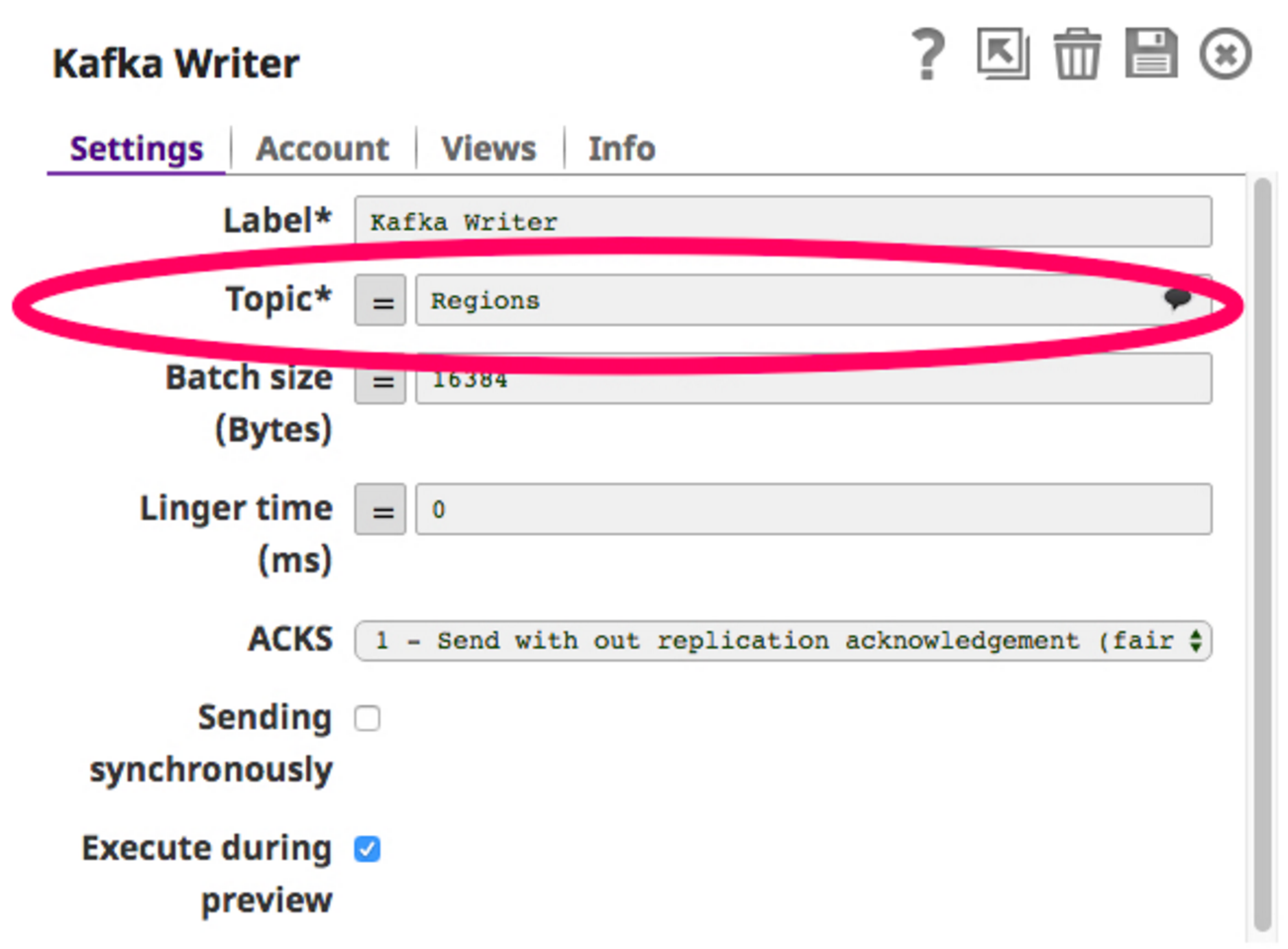 Jetzt, da der Writer Snap konfiguriert ist, können wir die Pipeline erstellen und sie ausführen. Hier sehen Sie, wie die Pipeline aussieht:
Jetzt, da der Writer Snap konfiguriert ist, können wir die Pipeline erstellen und sie ausführen. Hier sehen Sie, wie die Pipeline aussieht:
 Speichern und starten wir ihn. Bei der Ausführung veröffentlicht der Twitter-Feed Daten im Thema "Regionen", das im Kafka-Writer-Snap ausgewählt wurde, und so sieht die Ausgabe aus:
Speichern und starten wir ihn. Bei der Ausführung veröffentlicht der Twitter-Feed Daten im Thema "Regionen", das im Kafka-Writer-Snap ausgewählt wurde, und so sieht die Ausgabe aus:
 Das Kafka-Topic "Regions" enthält nun alle regionsbezogenen Twitter-Feeds, wie oben dargestellt. Unser nächster Schritt ist das Lesen aus demselben Topic mit dem Kafka-Reader (Kafka-Konsument) Snap und schließlich das Schreiben in HDFS.
Das Kafka-Topic "Regions" enthält nun alle regionsbezogenen Twitter-Feeds, wie oben dargestellt. Unser nächster Schritt ist das Lesen aus demselben Topic mit dem Kafka-Reader (Kafka-Konsument) Snap und schließlich das Schreiben in HDFS.
Dazu ziehe ich einen Kafka-Reader-Snap auf die Leinwand und lasse ihn dort fallen. Der Kafka Reader Snap fungiert als Verbraucher, indem er ständig das ausgewählte Thema abfragt. Unten sehen Sie einen Screenshot für Kafka Reader Snap:
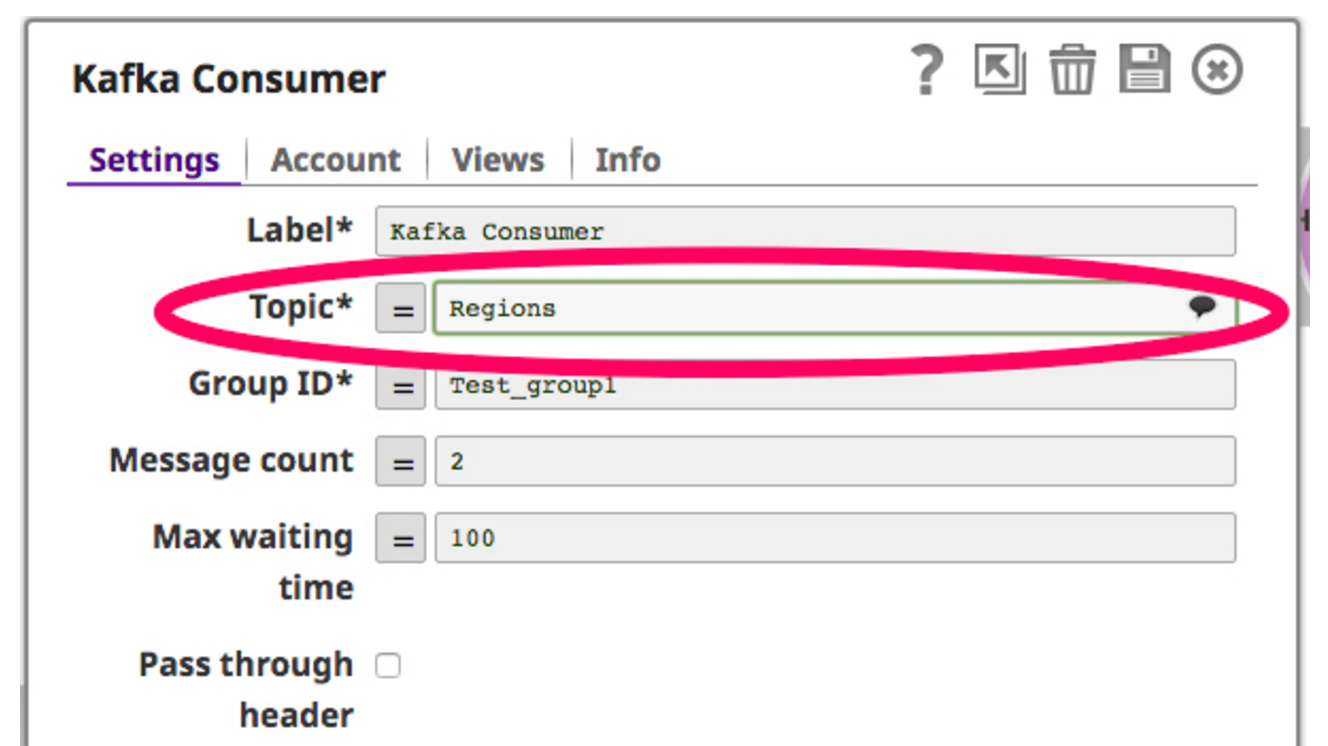 Nun, da der Verbraucher so eingestellt ist, dass er das Thema liest, filtere ich die vom Kafka-Verbraucher abgerufenen Daten und schreibe sie über den HDFS Writer Snap in das HDFS. Nachfolgend sehen Sie einen Screenshot dieser Pipeline:
Nun, da der Verbraucher so eingestellt ist, dass er das Thema liest, filtere ich die vom Kafka-Verbraucher abgerufenen Daten und schreibe sie über den HDFS Writer Snap in das HDFS. Nachfolgend sehen Sie einen Screenshot dieser Pipeline:
 Wenn ich diese Pipeline ausführe, liest der Kafka-Consumer-Snap Daten aus dem Topic "Regions", filtert die Daten auf eine bestimmte Region "China" und schreibt sie schließlich mit dem HDFS-Writer-Snap in das HDFS.
Wenn ich diese Pipeline ausführe, liest der Kafka-Consumer-Snap Daten aus dem Topic "Regions", filtert die Daten auf eine bestimmte Region "China" und schreibt sie schließlich mit dem HDFS-Writer-Snap in das HDFS.
Kafka kann auch mit Ultra kombiniert werden, indem die Twitter-Producer-Pipeline als Ultra-Pipeline ausgeführt wird, so dass sie ständig läuft und den Twitter-Stream in Kafka überträgt. Die Consumer-Pipeline wiederum kann als geplante Pipeline ausgeführt werden, die regelmäßig Datenpakete vom Kafka-Broker abruft.
Der Kafka Writer Snap kann in mehrere solcher Topics schreiben, und die Daten aus diesen Topics können in mehrere Services für verschiedene Anwendungsfälle eingespeist werden. Die SnapLogic Elastic Integration Platform as a Service(iPaaS) ermöglicht all diese Anwendungsfälle auf eine viel einfachere und schnellere Weise.
Nächste Schritte:
- Erfahren Sie mehr über unsere Frühjahrsausgabe 2016
- Sehen Sie sich eine Demonstration an oder kontaktieren Sie uns
- Lassen Sie uns in den Kommentaren wissen, über welche Themen wir als nächstes schreiben sollen





