





Ich bin in der glücklichen Lage, sowohl im akademischen Bereich als auch in der Industrie zu arbeiten. Zusätzlich zu meiner Arbeit bei SnapLogic bin ich Professor für Informatik an der Universität von San Francisco und habe in den letzten 20 Jahren an der Forschung in den Bereichen verteilte Systeme, parallele Programmierung, Betriebssystem-Kernel und Programmiersprachen gearbeitet. Diese beiden Rollen sind für beide Seiten von Vorteil. Ich bin in der Lage, meine Forschung auf reale Systeme anzuwenden und bringe diese Erfahrung in den Unterricht ein. Bei SnapLogic habe ich an der Weiterentwicklung unserer Produkttechnologie gearbeitet und war zuletzt Mitglied des ursprünglichen Architekturteams für unser neues Cloud-basiertes Integrationsprodukt, bei dem es sich um ein anspruchsvolles verteiltes System handelt. Jetzt, wo wir das Produkt freigegeben haben, können wir viele der technischen Aspekte und Designentscheidungen des Systems diskutieren.
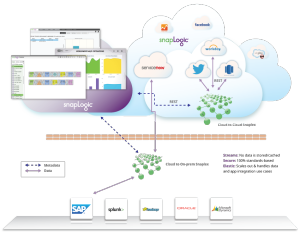
Bei der Entwicklung unserer Integration Platform as a Service (iPaaS) bei SnapLogic haben wir einige der zentralen Designprinzipien traditioneller Integrationsprodukte, die aus den frühen ETL-Tagen übernommen wurden, neu bewertet. Eine unserer tiefgreifendsten Architekturinnovationen ist die Verwendung von JSON-ähnlichen Dokumenten als primäres Mittel für den Transport von Daten von Snap zu Snap in einer Pipeline. Ältere Integrationstechnologien waren datensatzorientiert und passten gut in die damalige Welt der relationalen Datenbanken. Heute jedoch werden hierarchische Formate wie JSON und XML sowohl auf der Ebene der Dienstschnittstelle (z. B. REST und SOAP) als auch auf der Ebene des Datenspeichers (z. B. MongoDB) verwendet.
Die Verwendung von Dokumenten als nativer Datentyp bringt sowohl für die Datenverarbeitung als auch für die Endbenutzer mehrere Vorteile mit sich:
-
Dokumente sind besser geeignet für moderne Webdienste.
-
Dokumente führen zu prägnanteren Pipelines.
-
Ein Dokumentenmodell ermöglicht eine lose Kopplung von Pipelines.
-
Ein Dokumentenmodell ermöglicht eine bessere Wiederverwendung von Pipelines.
- Dokumente sind eine Obermenge von Datensätzen.
Moderne Webdienste
Während einige Webdienste immer noch SOAP verwenden, nutzen immer mehr RESTful-Schnittstellen JSON als Datenformat für Anfragen und Antworten. In beiden Fällen sind die Daten hierarchisch. Unsere Unterstützung für Dokumente ermöglicht es unseren Snap-Endpunkten, hierarchische Daten direkt im nativen Format zu verarbeiten und sie an nachgelagerte Snaps in einer Pipeline weiterzuleiten. Das bedeutet, dass es nicht erforderlich ist, Daten in Datensätze zu flatten oder ein JSON-Dokument in einen String oder BLOB-Typ umzuwandeln. Dank dieser nativen Unterstützung können alle Snaps, wie z. B. Filter, Join, Sort usw., Entscheidungen auf der Grundlage beliebiger, möglicherweise verschachtelter Felder innerhalb eines Dokuments treffen. Die resultierenden Dokumentdaten können dann direkt an einen Output-Snap gesendet werden, der möglicherweise eine Verbindung zu einem anderen Webdienst herstellt, der JSON verbraucht. Unser natives Dokumentenmodell macht es einfach, moderne Webdaten in ihrem nativen Format zu verarbeiten.
Obwohl sowohl XML als auch JSON hierarchisch sind, stellen wir fest, dass immer mehr Webdienste und APIs Daten in JSON-Formaten bereitstellen, da diese leichter und kompakter sind. XML neigt dazu, die Daten durch seine Meta-Tag-Kapselungen erheblich aufzublähen.
Prägnante Pipelines
Unser Dokumentenmodell führt letztendlich zu prägnanteren Pipelines, da es nicht notwendig ist, JSON oder XML in flache Datensätze zu übersetzen, dann die Verarbeitung vorzunehmen und schließlich die Datensätze wieder in JSON oder XML zu konvertieren. Dadurch können sich die Benutzer auf die Verarbeitung der Daten und nicht auf die Übersetzung der Datenformate konzentrieren, was die Arbeit in SnapLogic produktiver und weniger fehleranfällig macht. Weniger Datenübersetzungsschritte verbessern auch die Leistung der Pipeline in Bezug auf Durchsatz und Latenzzeit.
Lose Kopplung
Die vorherige Generation von Integrationsprodukten verband Datenflusskomponenten über typisierte Verknüpfungen. Das bedeutet, dass zur Verbindung einer Komponente mit einer anderen alle Ausgabefelder und -typen korrekt mit den Eingabefeldern und -typen der Zielkomponente verknüpft werden mussten. Diese Zuordnung ist zwischen jeder Komponente in einem Datenflussgraphen erforderlich. Diese Kopplung führt zwar zu einem gewissen Maß an Typsicherheit, ist aber auch sehr umständlich, wenn es darum geht, auf diese Weise verbundene Pipelines zu manipulieren. SnapLogic hat ein Patent für Predictive Field Linking angemeldet, um die Konstruktion von Pipelines zu vereinfachen, die auf strikter Feldverknüpfung basieren.
Da unser primärer Datentyp ein Dokument ist, verbrauchen oder erzeugen fast alle Snaps Dokumente. Das Verbinden von Snaps erfordert keine Feldverknüpfung mehr. Dadurch können Benutzer Pipelines schneller einrichten und in Betrieb nehmen, da Sie Snaps einfach verbinden, ausprobieren und neu anordnen können. Explizite Feldzuordnungen sind nach wie vor möglich; so kann beispielsweise das Feld first_name auf FirstName abgebildet werden, aber dies geschieht nun in einem separaten Mapping-Snap. Dies hat den zusätzlichen Vorteil, dass Feldzuordnungen gekapselt werden können, so dass sie in derselben Pipeline oder in verschiedenen Pipelines problemlos wiederverwendet werden können.
Wiederverwendung von Rohrleitungen
Im Zusammenhang mit der losen Kopplung unterstützt das Dokumentenmodell die Wiederverwendung von Pipelines besser. Ohne strikte Feldverknüpfung lassen sich verschachtelte Pipelines durch die Wiederverwendung anderer Pipelines viel einfacher zusammenstellen. In gewisser Weise sind wir von einem statisch typisierten Ansatz, wie er in Programmiersprachen üblich ist, zu einem dynamisch typisierten Ansatz übergegangen. Der dynamische Ansatz führt zu kompakteren Pipelines, die leichter miteinander verbunden werden können. Diese einfache Verbindung fördert auch das Unit-Testing von Teilpipelines, so dass eine korrekte Ausführung schneller erreicht werden kann.
Dokumente als Aufzeichnungen
Wir bei SnapLogic haben erkannt, dass moderne Webservices und Datenspeicher zwar auf JSON ausgerichtet sind, Unternehmen aber immer noch relationale Datenbanken für normalisierte Transaktionsdaten verwenden. Das Tolle an Dokumenten ist, dass sie eine Obermenge von relationalen Datensätzen sind. Bei der Konvertierung eines Datensatzes in ein Dokument kombinieren wir die Spaltennamen aus dem Schema mit den Felddaten, um ein Schlüssel/Wert-Dokument zu erstellen. Auf diese Weise können wir je nach Bedarf Datensätze konsumieren und ausgeben, aber dennoch alle Vorteile des Dokumentenmodells nutzen. Darüber hinaus unterstützen wir traditionelle ETL-Operationen wie JOIN, AGGREGATE und SORT auf Dokumenten. Dadurch können primär relationale Daten nahtlos verarbeitet werden, aber auch diese ETL-Operationen werden so erweitert, dass hierarchische Dokumente unterstützt werden.
Schlussfolgerung
Als Reaktion auf die sich ändernden Integrationsendpunkte und Datenformate haben wir viele Aspekte der Integration in unserer neuen Integration Platform as a Service neu gestaltet. Unser JSON-zentrierter Ansatz umfasst moderne Webschnittstellen und unterstützt nahtlos relationale Daten. Diese native Unterstützung für Dokumente ist eine der vielen architektonischen Innovationen, die wir entwickelt haben, um Unternehmen dabei zu helfen, sowohl Webdienste als auch traditionelle Datenspeicher zu verbinden.



