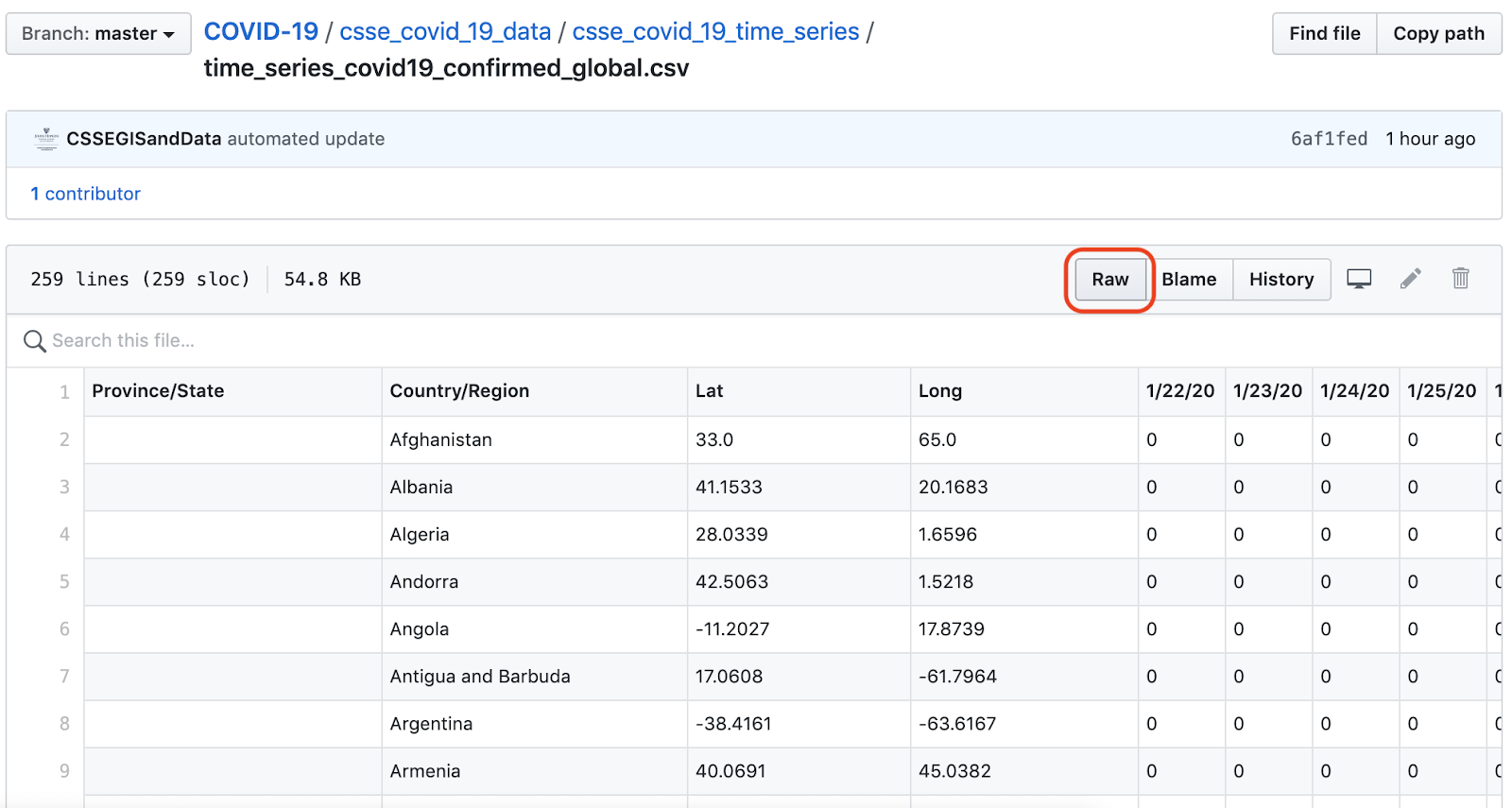
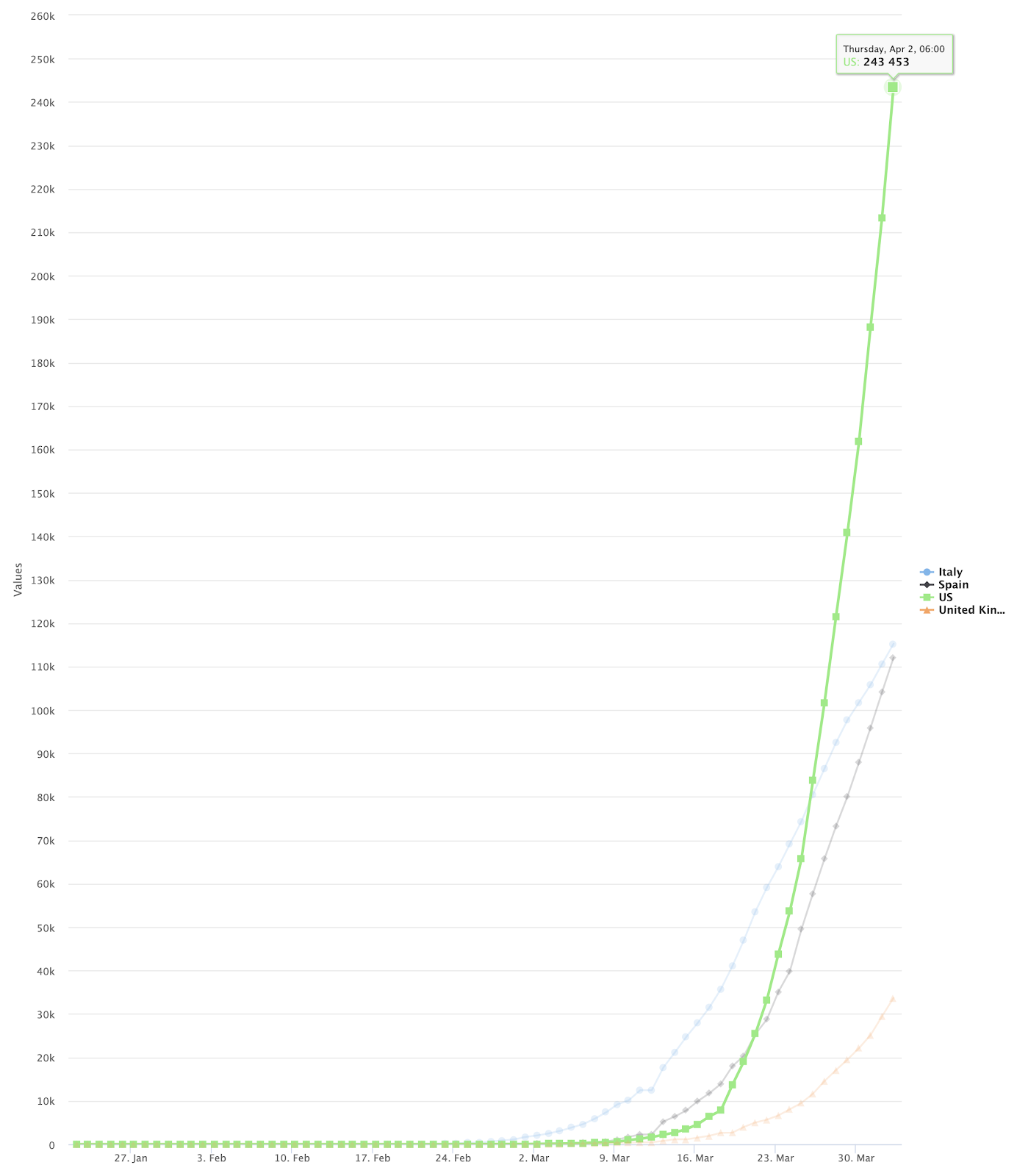
Die Gesamtzahl der bestätigten COVID-19-Fälle weltweit nähert sich jetzt der Zwei-Millionen-Grenze.
Im Internet stehen zahlreiche Ressourcen zur Verfügung, um das Wachstum dieser Pandemie zu verfolgen und zu verstehen, darunter das Dashboard, das vom Johns Hopkins University Center for Systems Science and Engineering betrieben wird. Dieses Dashboard wird von einem Datenarchiv, das auf GitHub. Die Quelldaten sind von hoher Qualität, müssen aber für eine effektive Visualisierung strukturell stark verändert werden. Die SnapLogic Intelligent Integration Platform verarbeitet die Transformationen problemlos.
In diesem Blog werde ich den Aufbau einer SnapLogic-Pipeline erläutern, die eine Teilmenge dieser Daten aus dem GitHub-Repository liest, die Daten für einige Länder filtert und die Daten so umwandelt, dass sie mit einem Liniendiagramm unter Verwendung der DataViz-Funktion von SnapLogic angezeigt werden können. Wenn Sie das Projekt verfolgen möchten, können Sie die in diesem Beitrag beschriebene Pipeline in unserer Community herunterladen. In diesem Blog finden Sie Links zu den entsprechenden Abschnitten der SnapLogic-Produktdokumentation, wo Sie weitere Informationen finden.
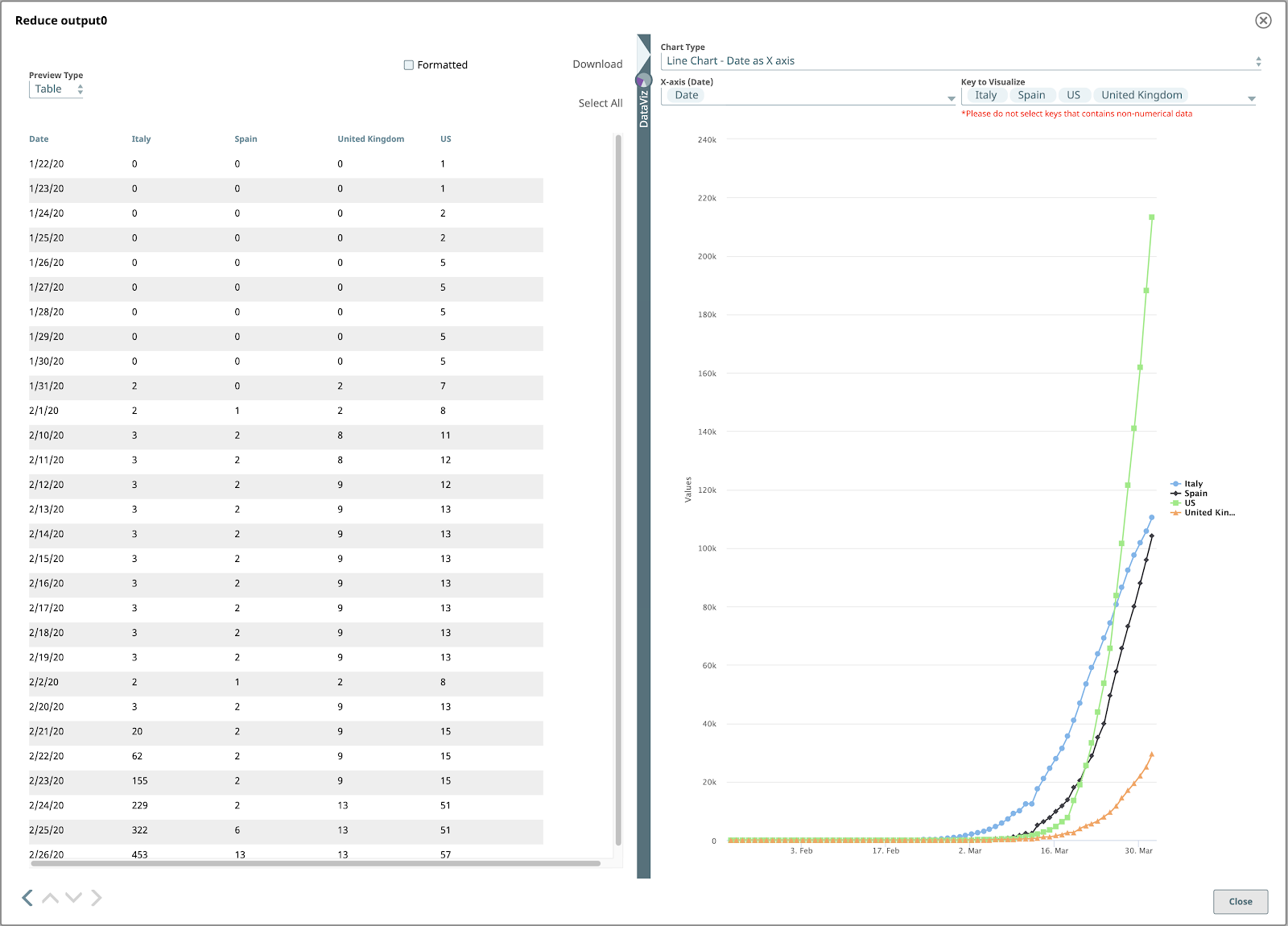
Die endgültige Ausgabe sieht wie folgt aus:
Untersuchen Sie die Quelldaten
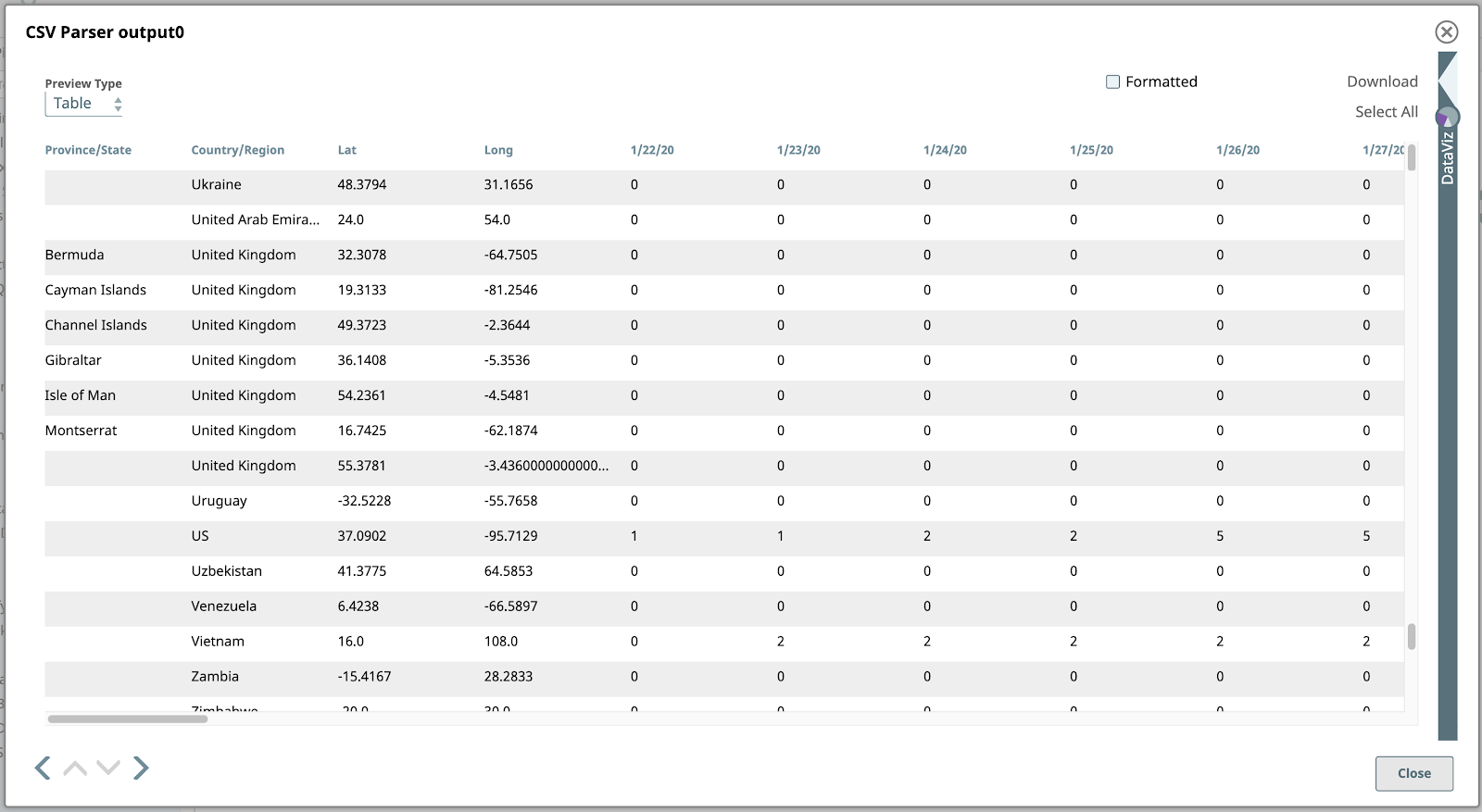
Unsere Quelldaten sind die JHU-Daten time_series_covid19_confirmed_global.csv Datei. Diese Datei enthält Zeitreihendaten für die Gesamtzahl der bestätigten COVID-19-Fälle nach Land/Region und wird jeden Tag aktualisiert.
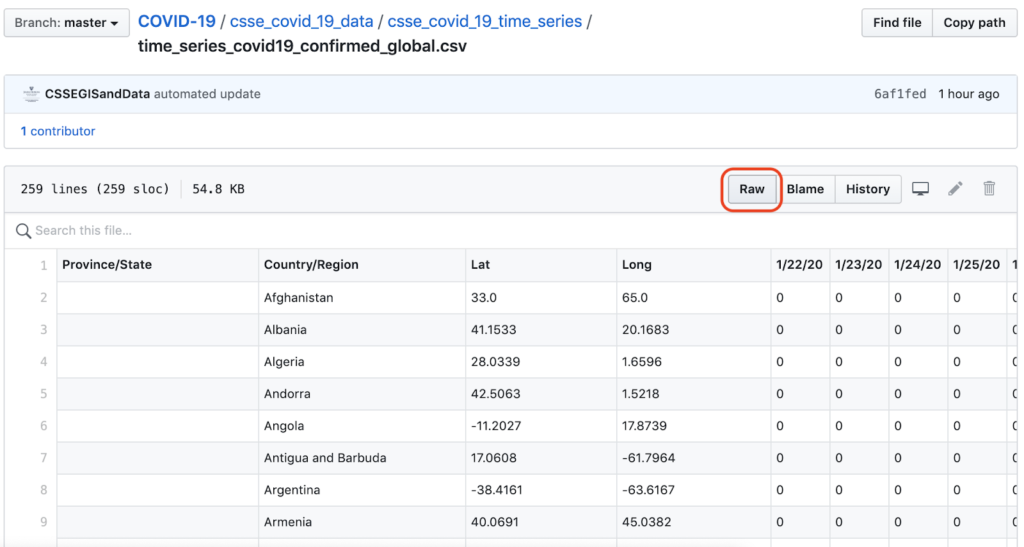
GitHub's Rohdaten Schaltfläche in dieser Ansicht ist verlinkt mit der URL für die rohe CSV-Datei.
Die Pipeline aufbauen
Im Folgenden finden Sie einen Überblick über unsere SnapLogic-Pipeline zum Lesen und Umwandeln dieser Daten:

Lassen Sie uns diese Pipeline Snap für Snap durchgehen.
1. Datei-Leser & CSV-Parser
Die ersten beiden Schnappschüsse in dieser Pipeline zeigen eine sehr häufige Paarung:
- A Datei-Lesegerät zum Lesen der Rohdaten, konfiguriert mit der Rohdatei URL.
- A Parser Snap speziell für das Datenformat der Datei, in diesem Fall CSV.
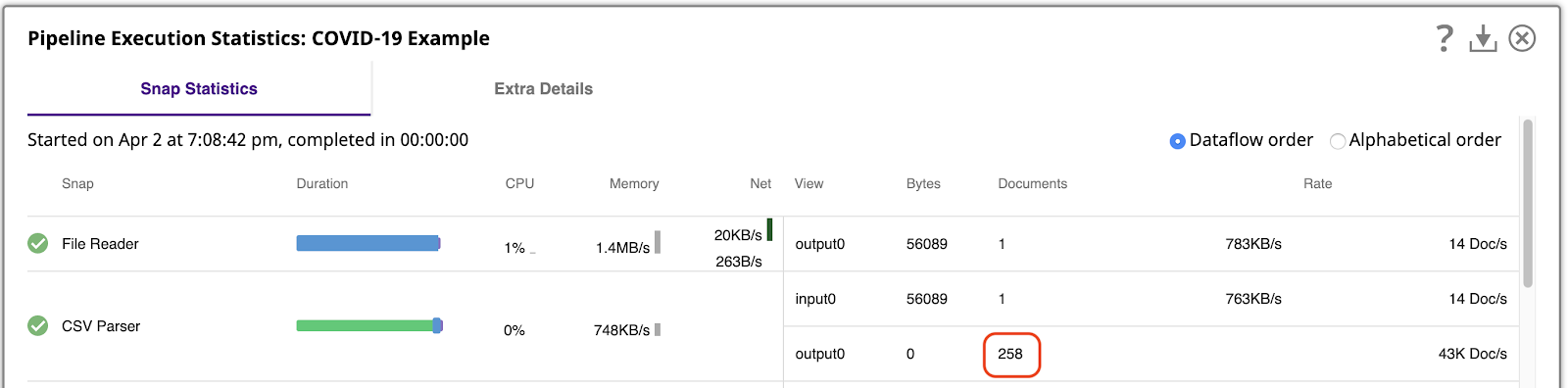
Es ist wichtig zu verstehen, mit wie vielen Daten wir arbeiten. Dies können wir erreichen, indem wir die Pipeline ausführen und dann die Pipeline-Ausführungsstatistikansehen, die zeigt, dass der CSV-Parser 258 Ausgabedokumente erzeugt hat, eines pro Zeile der CSV-Datei.
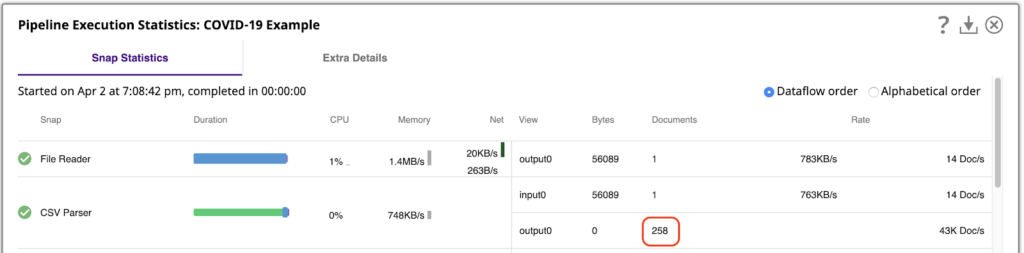
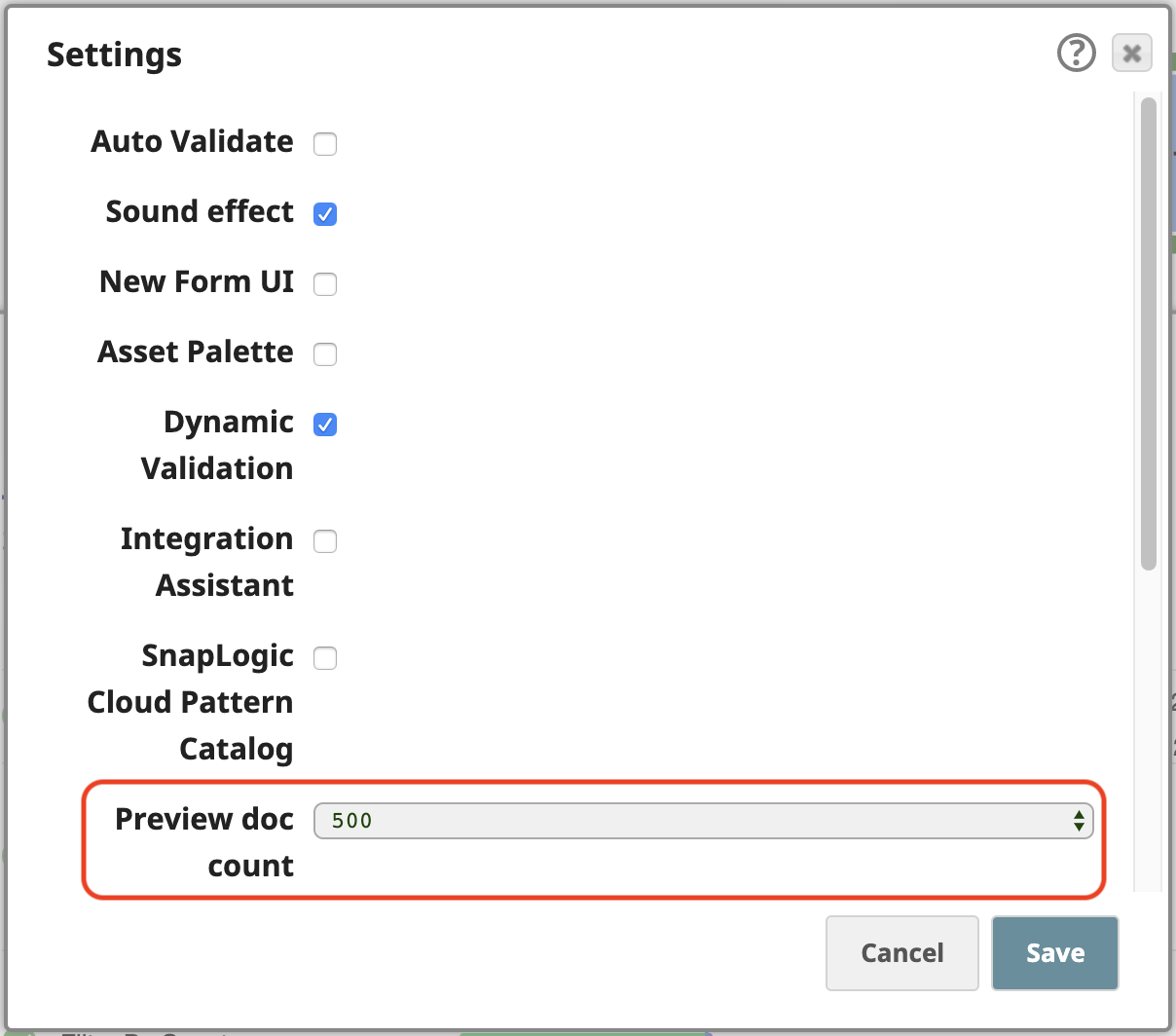
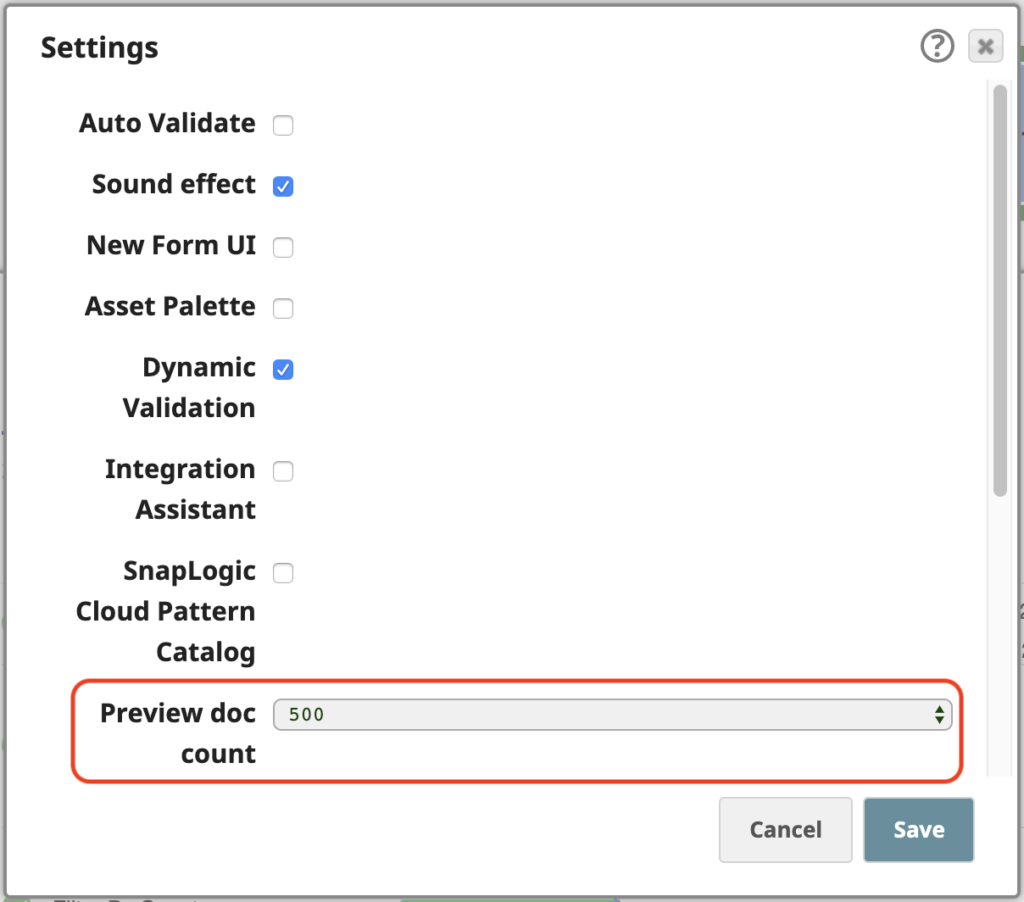
Die SnapLogic-Plattform ermöglicht es Ihnen, Daten auch im Vorschaumodus zu verarbeiten, während Sie Ihre Pipelines erstellen. Um einfach mit diesen 258 Ausgabedokumenten in der Vorschau zu arbeiten, öffnen Sie die Einstellungen des Designer und ändern Sie die Anzahl der Vorschaudokumente auf 500:
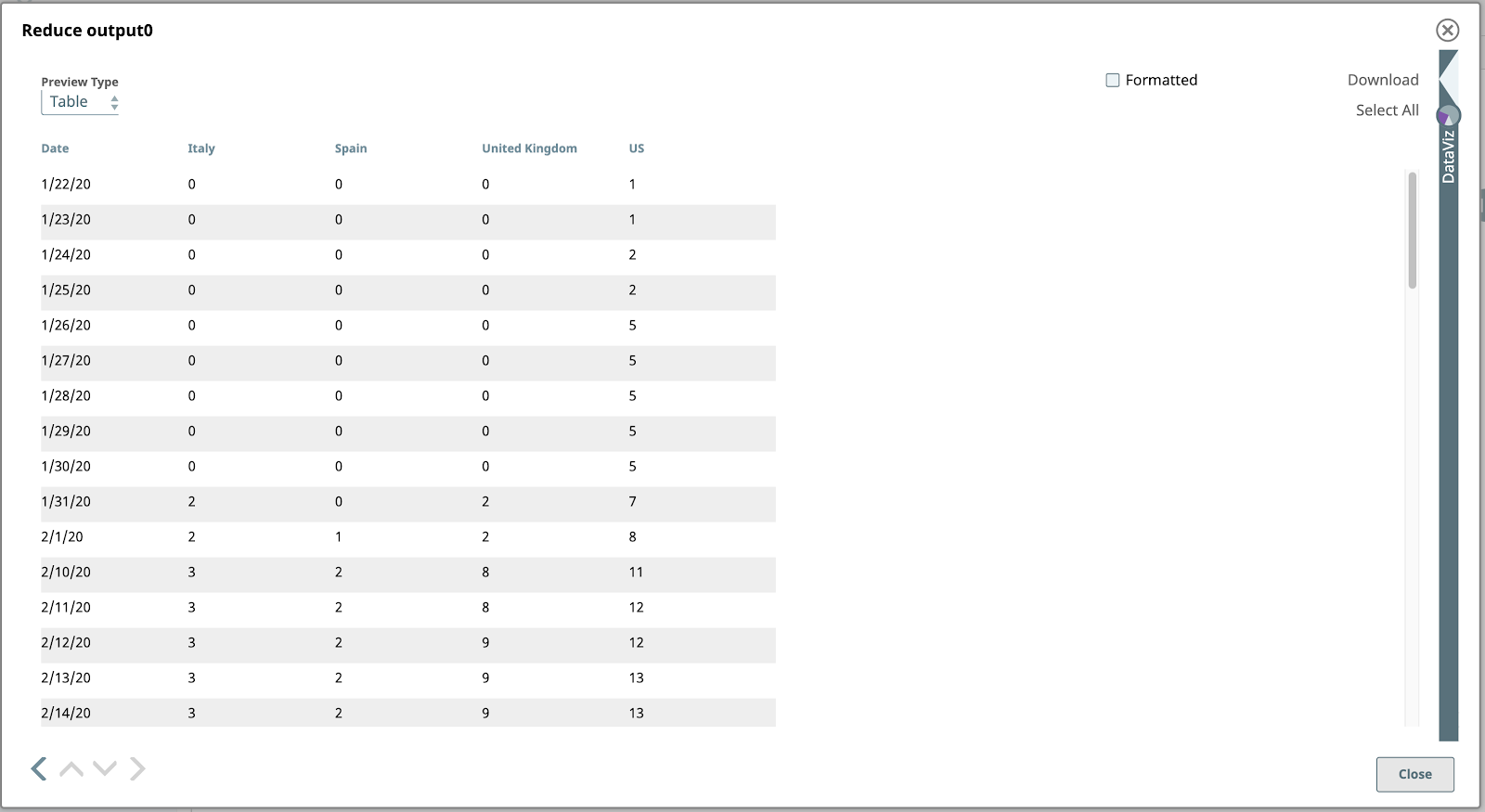
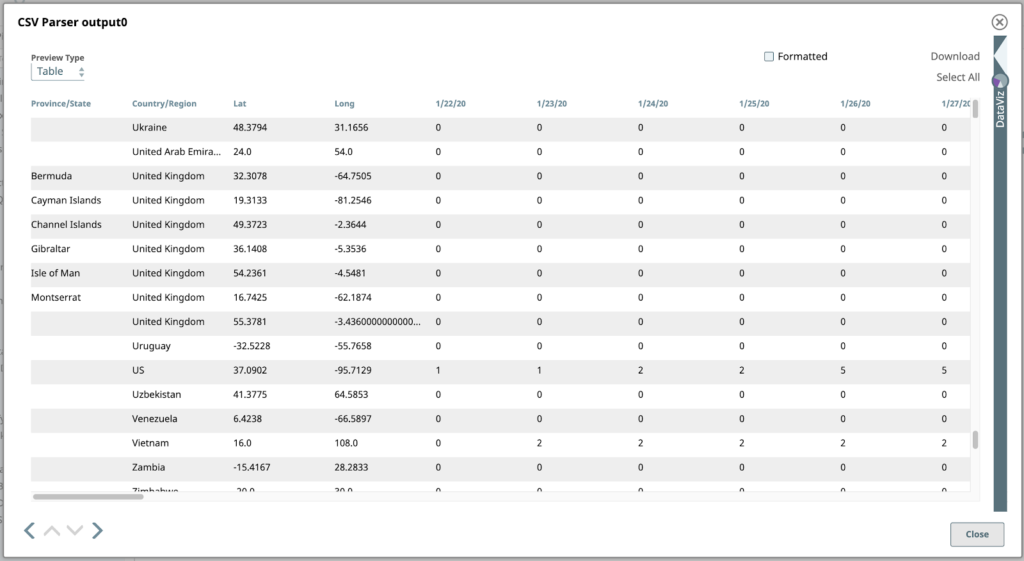
Wenn wir nun die Pipeline validieren, können wir eine Vorschau aller CSV-ParserAusgabedokumente ansehen. Die Standard Tabelle ist aufgrund der tabellarischen Struktur das beste Format zur Darstellung dieser Daten.
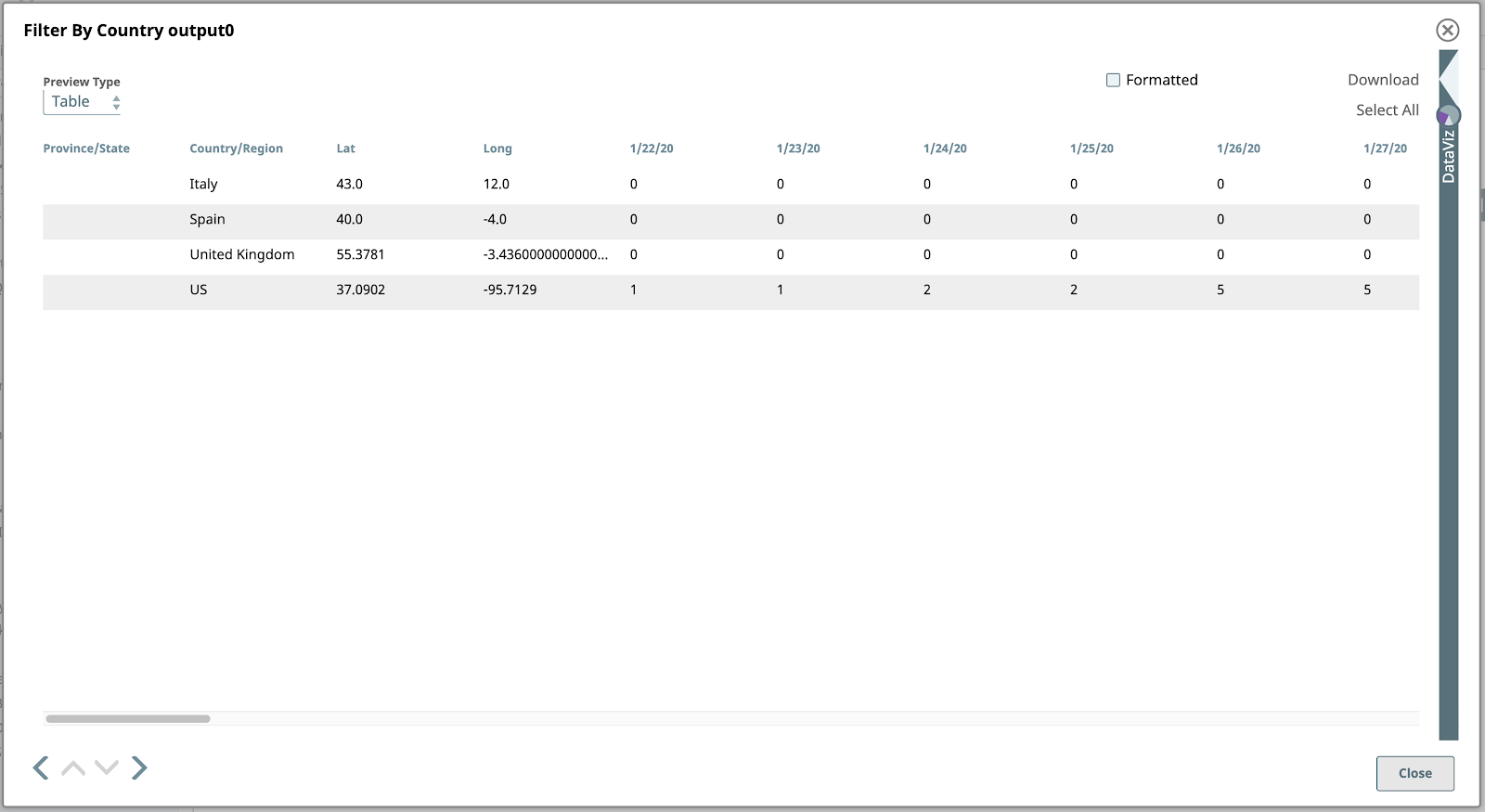
2. Nach Land filtern
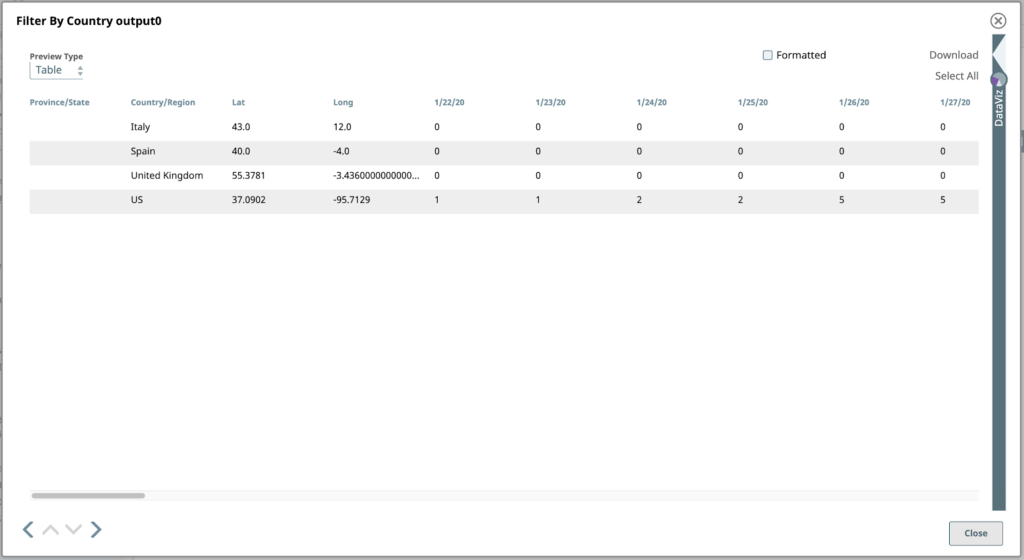
Filtern wir nun diese Daten, um die Zeilen (Dokumente) zu finden, die nur den vier Ländern entsprechen, auf die wir uns in diesem Beispiel konzentrieren. Die Länder sind die USA, Spanien, Italien und das Vereinigte Königreich.
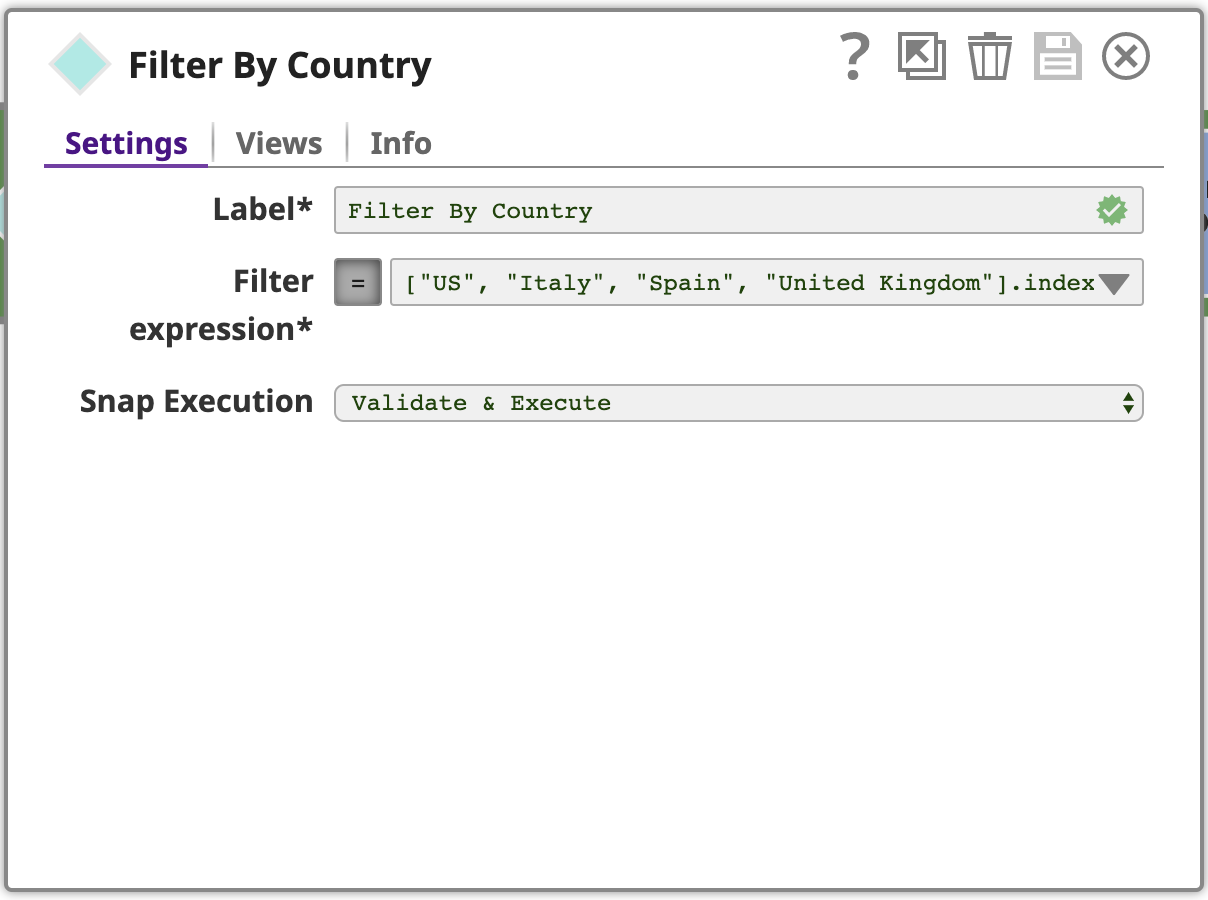
Verwenden Sie einen Filter Snap, konfiguriert mit einem Ausdruck unter Verwendung von SnapLogic's Ausdruckssprachekonfiguriert wird, die auf JavaScript basiert, aber mit zusätzlichen Funktionen für die Arbeit mit SnapLogic-Dokumenten ausgestattet ist. Dieser Ausdruck wird für jedes Eingabedokument als wahr oder falsch. Wenn der Ausdruck zu wahr für ein bestimmtes Eingabedokument ergibt, wird es als Ausgabedokument dieses Snap durchlaufen, wenn falseist, wird das Dokument übersprungen.
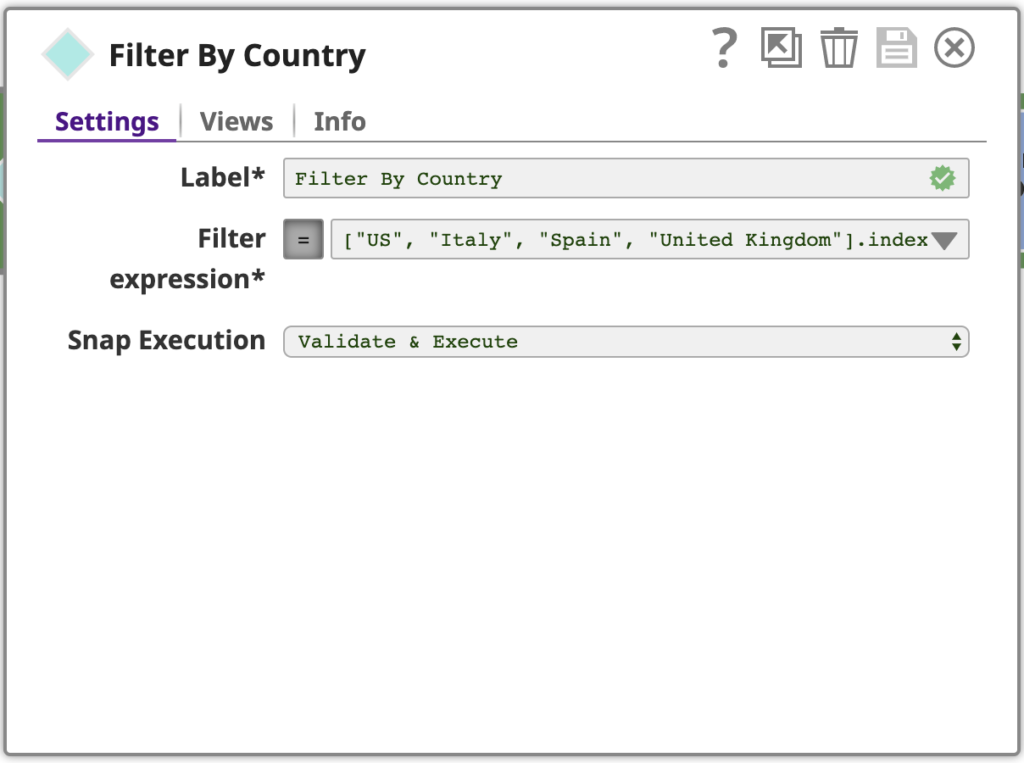
Um den vollständigen Ausdruck zu filternzu sehen, klicken Sie auf den Abwärtspfeil und dann auf den Editor erweitern Symbol, um den Ausdrucks-Editor:
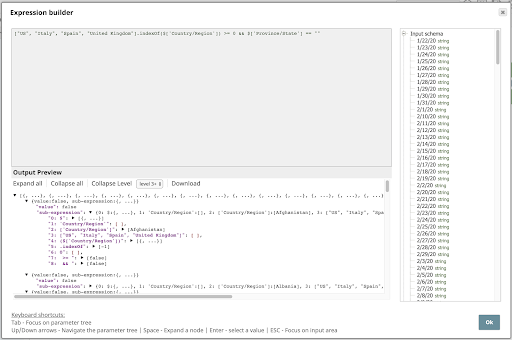
Schauen wir uns diesen Ausdruck genauer an:
["US", "Italien", "Spanien", "Vereinigtes Königreich"] .indexOf($['Land/Region']) >= 0 && $['Bundesland/State'] == ""
Dieser Ausdruck verwendet ein Array zur Angabe der interessierenden Länder und die indexOf Operator, um zu testen, ob das Land/Region Wert ein Element dieses Arrays ist. Er prüft auch, ob der Wert Provinz/Staat Wert leer ist, denn wir sind nicht nicht an Zeilen mit einem Wert für diese Spalte interessiert sind.
Wenn wir uns die Ausgabe dieses Snap ansehen, sehen wir die vier Zeilen (Dokumente!) von Interesse:
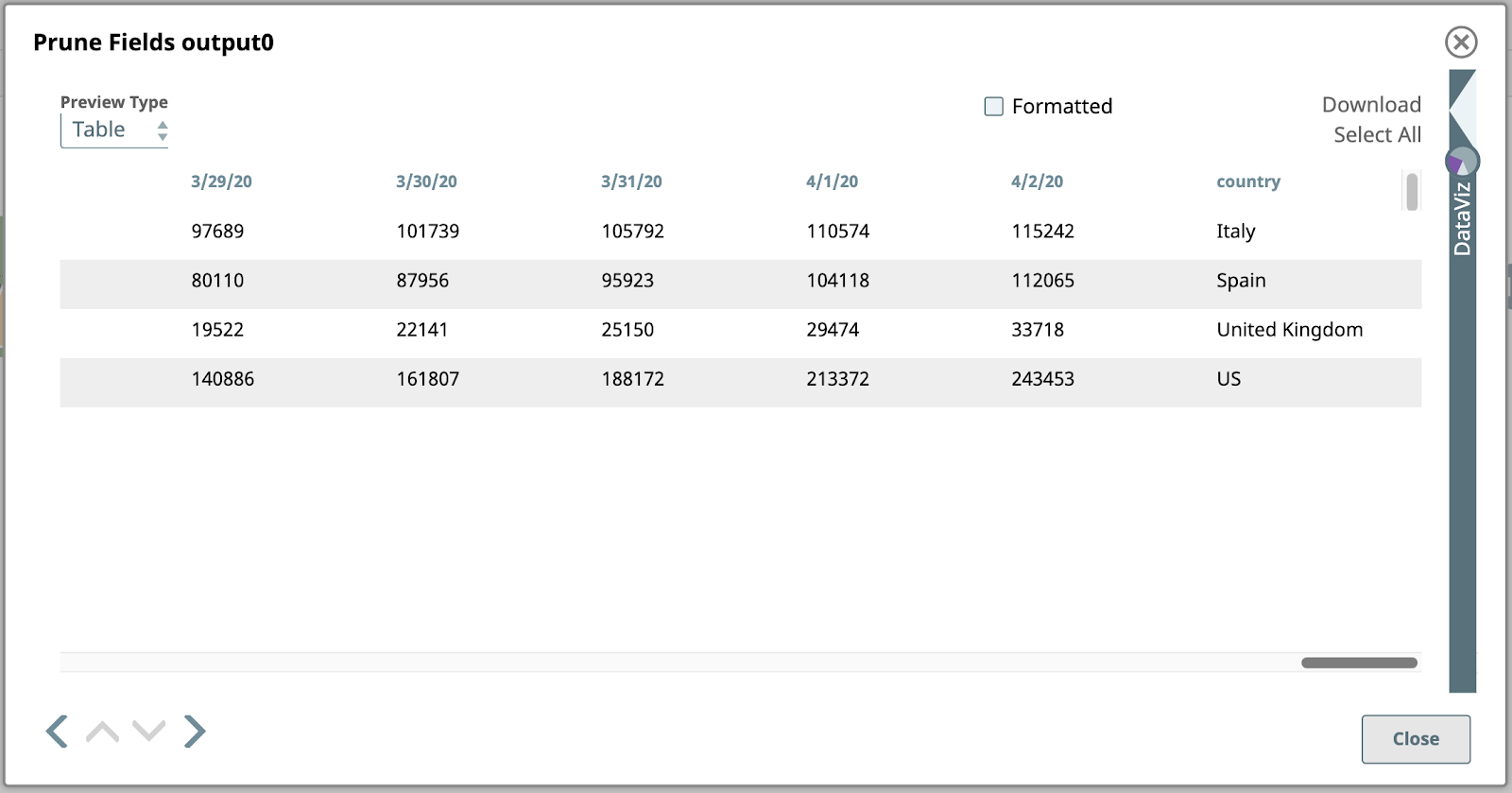
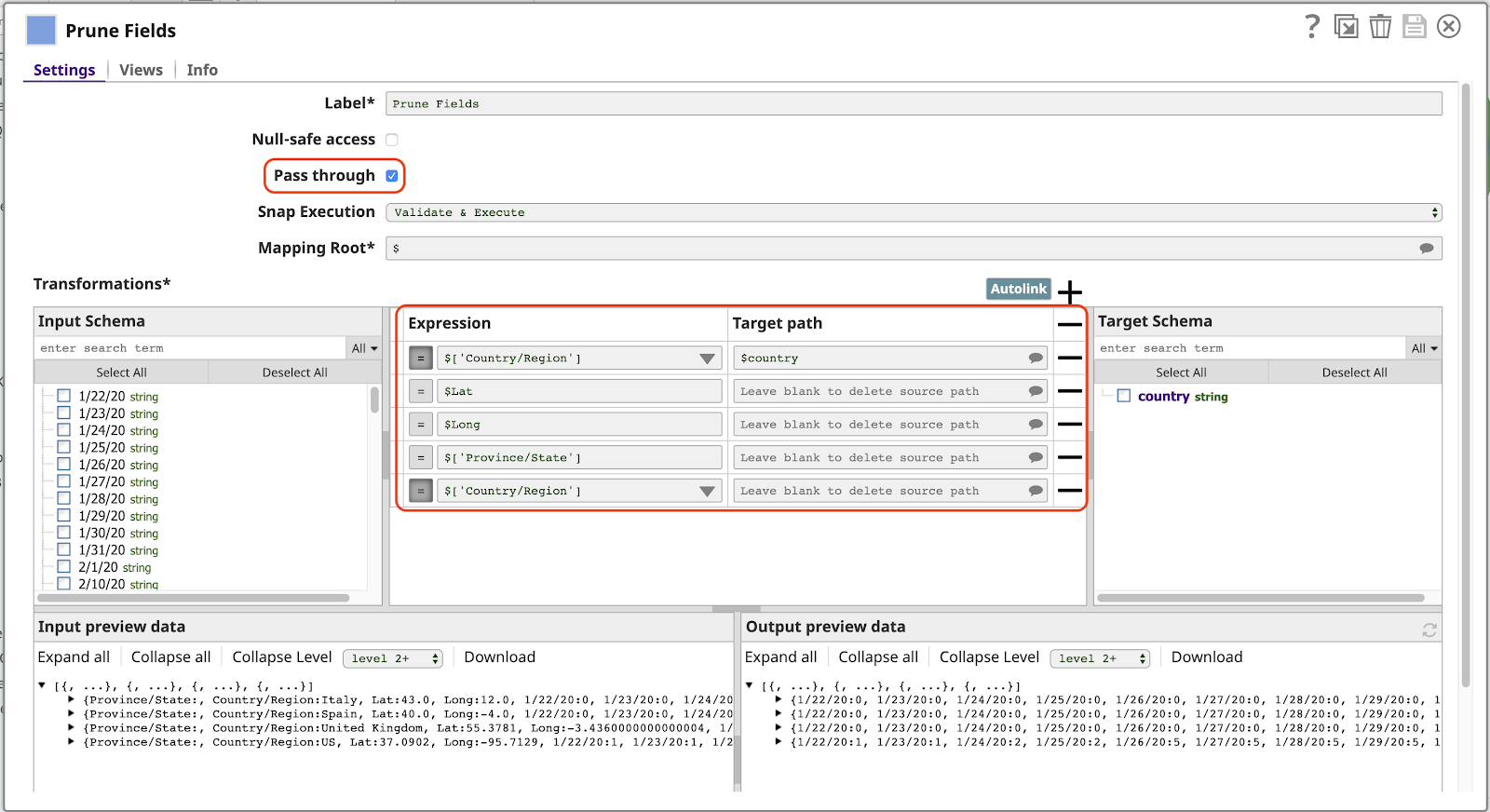
3. Felder beschneiden
Als nächstes ist ein Mapper Snap, der bei weitem leistungsfähigste und am häufigsten verwendete Snap in SnapLogic. Hier verwenden wir den Mapper um ein weiteres typisches Muster zu implementieren, das in einer Pipeline dieser Art verwendet wird: das Filtern der Spalten der Daten, die wir als Felder oder Schlüssel nennen, da jedes Dokument als JSON-Objekt dargestellt wird. Schauen wir uns den MapperKonfiguration an:
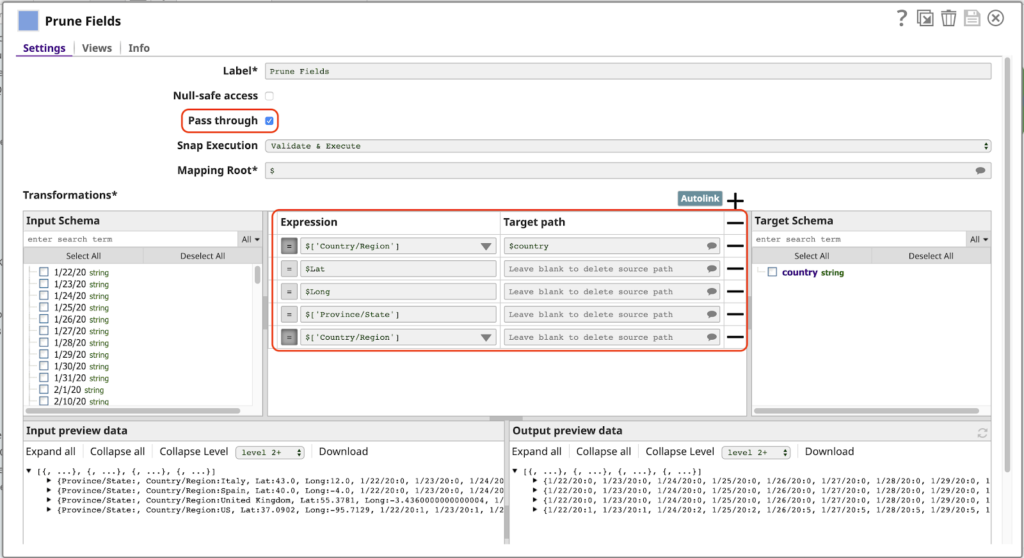
Beachten Sie bei dieser Konfiguration Folgendes:
- Die Durchgang Einstellung ist aktiviert. Dadurch werden alle Felder standardmäßig durchgelassen, ohne dass sie explizit zugeordnet werden, einschließlich der Felder, die Datumsangaben entsprechen (1/22/20 usw.). Das bedeutet, dass die Ausgabe bei der nächsten Ausführung dieser Pipeline automatisch neue Daten für zusätzliche Daten enthält.
- Die erste Zeile der Tabelle Transformationen Tabelle ordnet den Wert des Parameters Land/Region Feldes auf den Namen Land in der Ausgabe. Das Vorhandensein des Feldes / Zeichens im ursprünglichen Namen ist es ungültig, den Ausdruck $Land/Region. Wir müssten die längere alternative Syntax verwenden $['Land/Region']verwenden, was nicht wünschenswert ist. Mit dieser Zuordnung können wir uns auf diesen Wert einfach als $Land.
- Jede Zeile, die einen Ausdruck aber keinen Wert für Zielpfad enthält, wird aus der Ausgabe gelöscht. Dies ist nur erforderlich, wenn Durchgang aktiviert ist. Beachten Sie, dass wir eine Zeile für das Land/Region haben müssen, da sonst der Wert für dieses Feld zweimal im Ausgabedokument erscheint, nämlich als Land/Region (weil Durchreichen aktiviert ist) und als Landwie in der ersten Zuordnung angegeben.
Hier ist eine Vorschau auf diesen Snap, nur mit den Datumsfeldern und dem Land Feld ganz rechts:
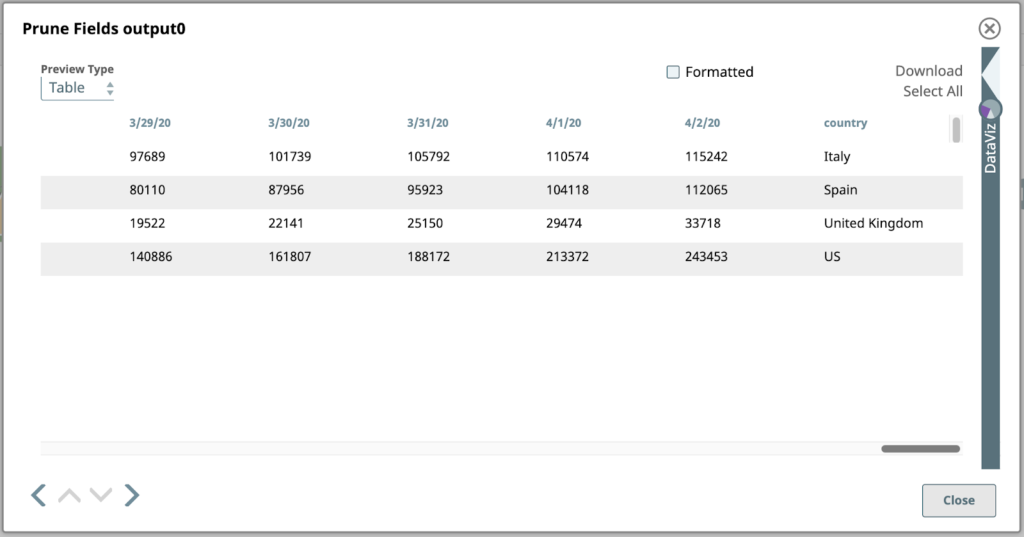
Schauen wir uns diese Ausgabe genauer an. Jeder Wert unter einer Datumsspalte in dieser Tabelle ist die Gesamtzahl der bestätigten Fälle an diesem Datum in dem entsprechenden Land in der Spalte ganz rechts. Dies sind die Daten, die wir grafisch darstellen wollen. Dazu müssen wir jedoch zunächst die Struktur umdrehen, damit aus den Spalten Zeilen werden. Dazu sind erweiterte Zuordnungen und Ausdrücke erforderlich.
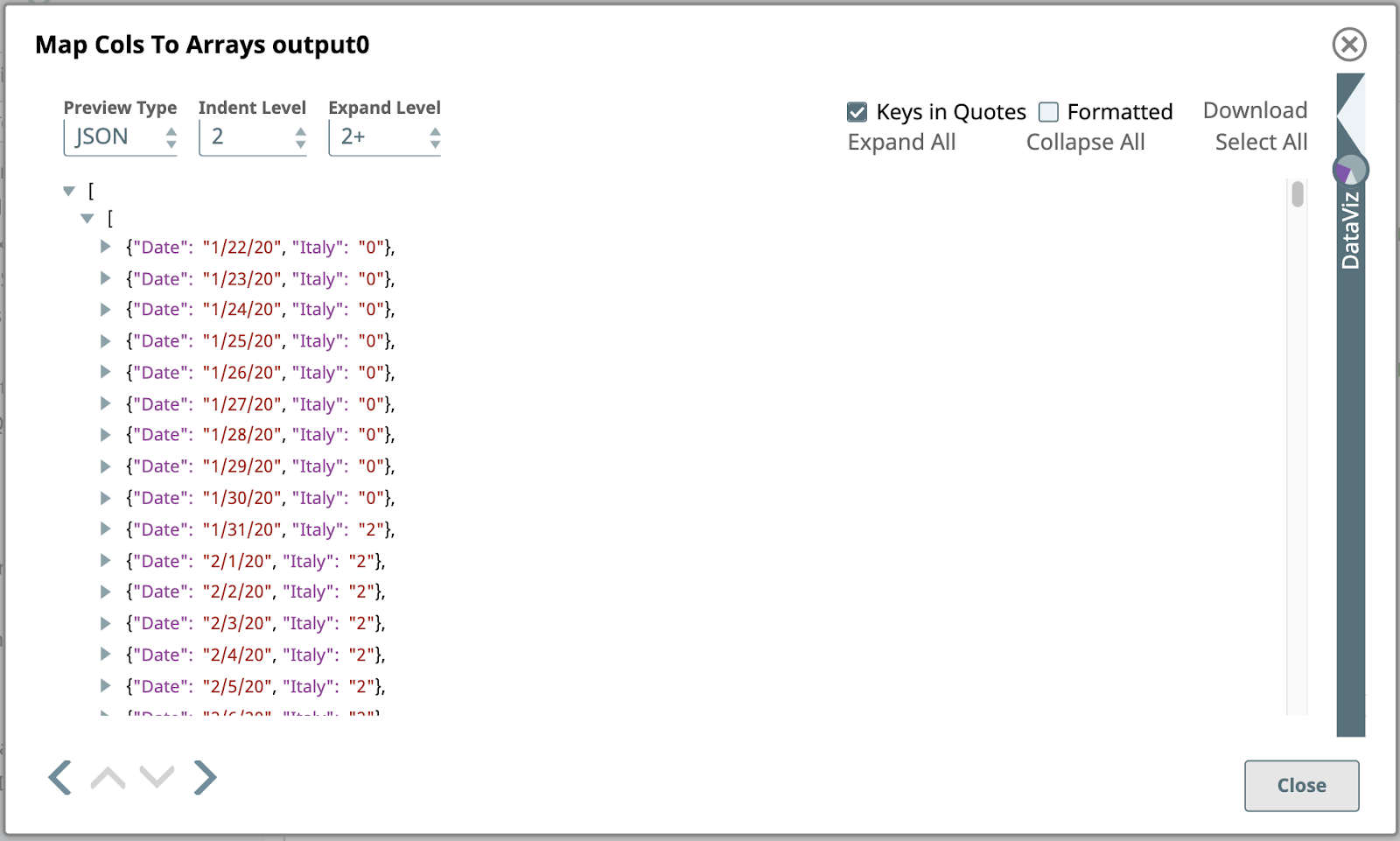
4. Spalten auf Arrays abbilden
Als Nächstes planen wir einen weiteren Mapper:
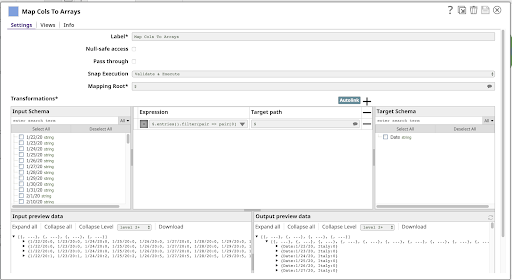
Dieser hat einen einzigen Ausdruck:
$.entries().filter(pair => pair[0] != ‘country’) .map(pair => { Date: pair[0], [$country]: pair[1] })
Schauen wir uns das mal genauer an.
$.Einträge()
Dieser Unterausdruck erzeugt ein Array mit den Schlüssel/Wert-Paaren des Objekts, wobei jedes Paar ein Unterarray mit zwei Elementen ist: dem Schlüssel und dem Wert. Sie können dieses Ergebnis sehen, indem Sie den Unterausdruck Funktion des Ausdrucks-Erstellung:

.Filter(Paar => Paar[0] != 'Land')
Dieser Unterausdruck filtert das Array von Schlüssel/Wert-Paaren, die von Einträgeerzeugte Array von Schlüssel/Wert-Paaren, was zu einem neuen Array der Paare führt, die mit der als Argument angegebenen Callback-Funktion übereinstimmen. Im obigen Screenshot sehen wir die ersten Paare des Dokuments, das die US-Daten enthält: ["1/22/20", "1"], ["1/23/20", "1"], ["1/24/20", "2"], usw. Wenn Sie sich die Ausgabe von Prune Fields noch einmal ansehen, können Sie die letzten Paare in dieser Zeile sehen: ["4/2/20", "243453"], ["Land", "US"]. Unsere Filterfunktion passt auf alle bis auf das letzte Paar, bei dem Paar[0] == "Land" ist.
.map(pair => { Date: pair[0], [$country]: pair[1] })
Die Eingabe für diese map Unterausdruck ist ein Array der Schlüssel/Wertpaare, die jedes Datum und die Fallzahl für dieses Datum darstellen: ["1/22/20", "1"], ..., ["4/2/20", "243453"] für die US-Zeile.
Die Karte Funktion gibt ein neues Array zurück, in dem jedes Paar durch den Ausdruck rechts vom =>steht, der ein Objekt-Literal ist, was zu einem Objekt mit zwei Eigenschaften führt:
- Date: pair[0] ergibt eine Eigenschaft namens Datum die die erste Hälfte jedes Paares (den Datumswert) enthält.
- [$Land]: Paar[1] ergibt eine Eigenschaft, deren Name der Wert des Ausdrucks $Landist und deren Wert die zweite Hälfte jedes Paares ist (die Anzahl der Fälle).
Für das letzte Paar der Zeile mit den US-Daten wird die abbilden Funktion ein Objekt wie dieses erzeugen:
{“Date”: “4/2/20”, “US”: “243453”}
Dies kommt der Form, die wir benötigen, um Punkte in ein Diagramm einzutragen, sehr viel näher.
Wenn Sie den Vorschau Typ auf JSON ändern, sehen Sie hier die Ausgabevorschau des Befehls Spalten auf Arrays abbilden Einrasten:
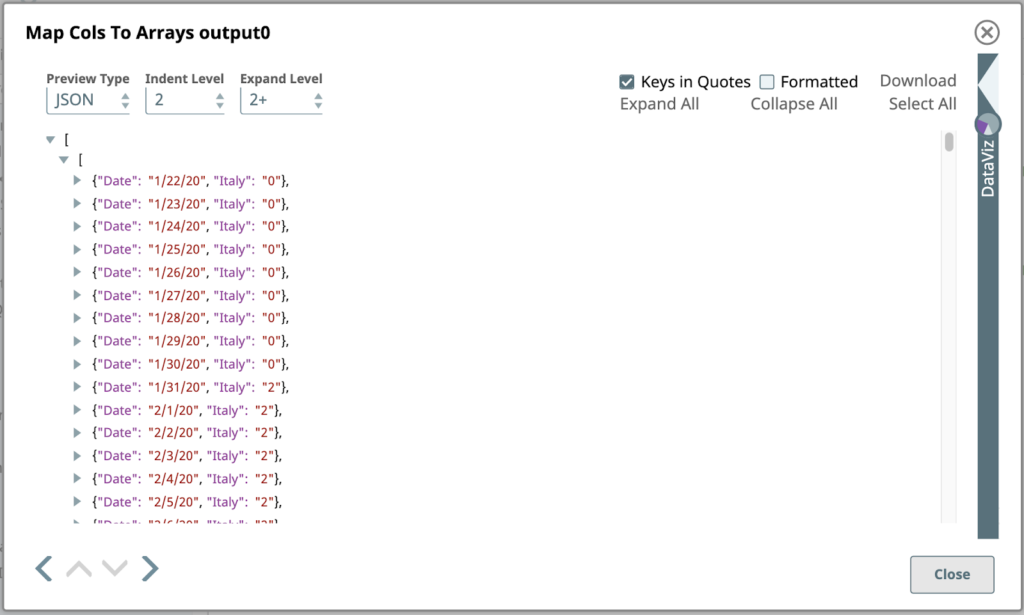
Dies ist eine Teilansicht des ersten Ausgabedokuments dieses Snap, das durch Umwandlung des ersten Eingabedokuments mit den Daten für Italien erstellt wurde. Im Gegensatz zum Eingabedokument, das ein einfaches JSON-Objekt war, das aus Name/Wert-Paaren bestand, ist das Ausgabeobjekt ein JSON-Array von JSON-Objekten.
Wenn Sie den Vorschautyp wieder auf Tabelle umstellen und auf einige Zellen in der letzten Zeile klicken, die dieselben Daten repräsentieren, können Sie einen Blick in diese verschachtelte Array-Struktur werfen.
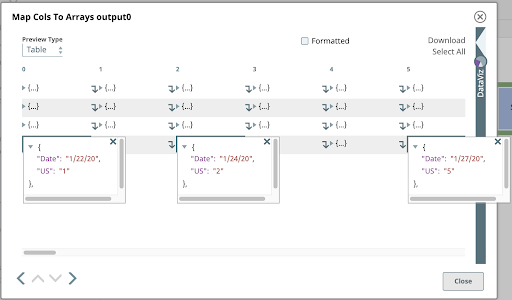
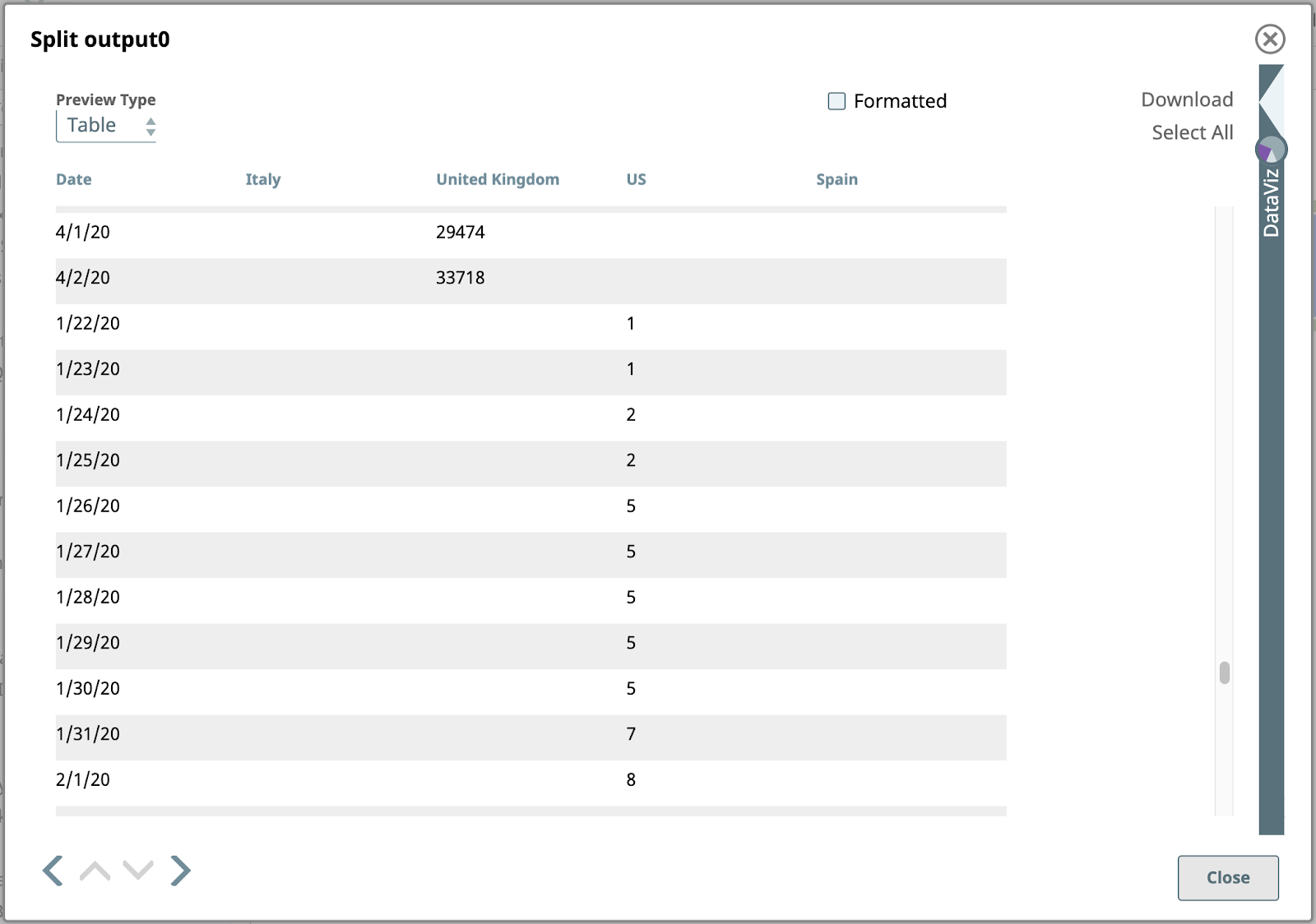
5. Teilen
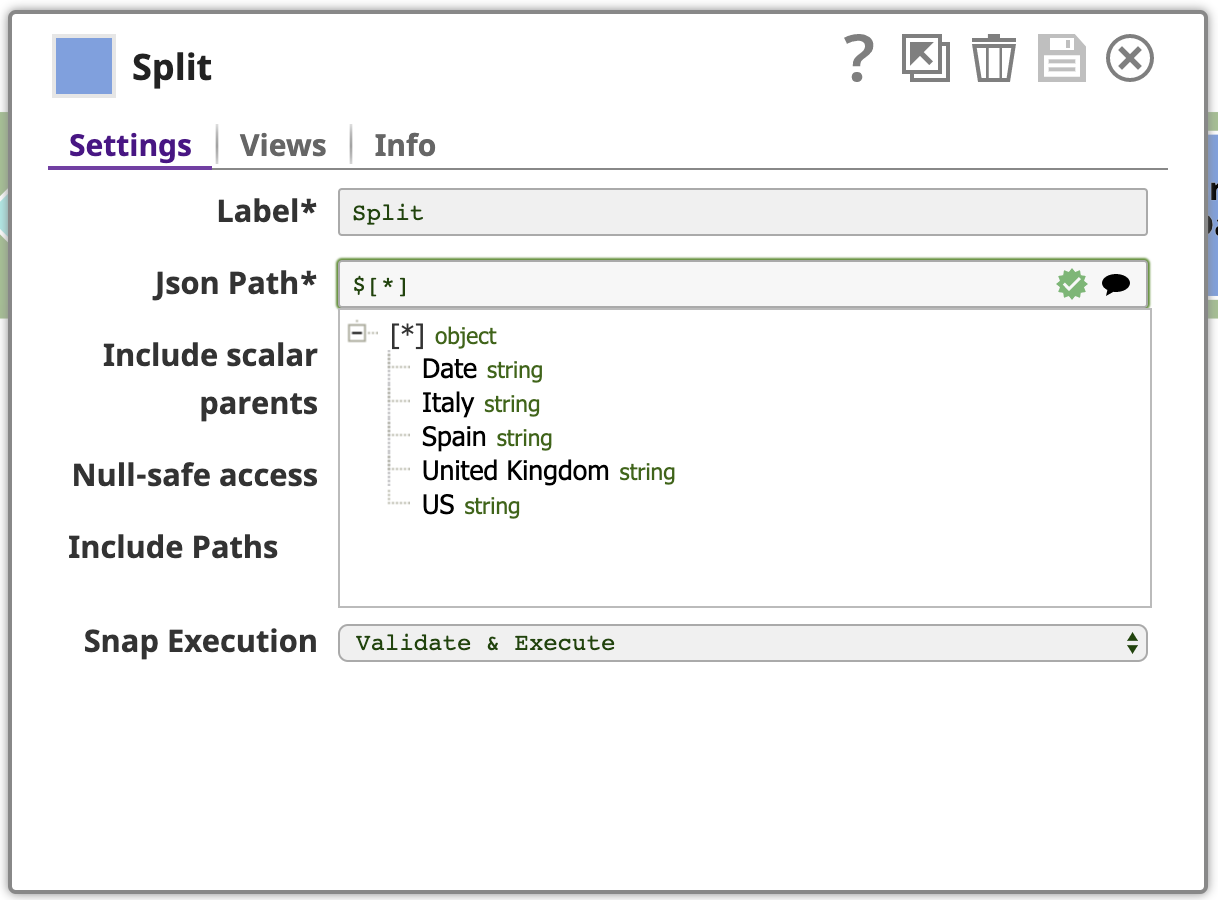
Wie oben gezeigt, ist jedes Eingabedokument für den nächsten Snap in unserer Pipeline ein Array von Objekten. Wir wollen diese Arrays in ihre Komponentenobjekte aufteilen. Verwenden Sie den JSON-Splitter Snap mit dem Json-Pfad Einstellung mit dem Pfad, der auf die Array-Elemente verweist, die als Ausgabedokumente abgebildet werden sollen. Klicken Sie auf das Vorschlags-Icon am rechten Ende des Json-Pfad Feldes hilft uns dabei. Ein Klick auf den obersten Knoten in diesem Baum setzt den Pfad auf $[*].
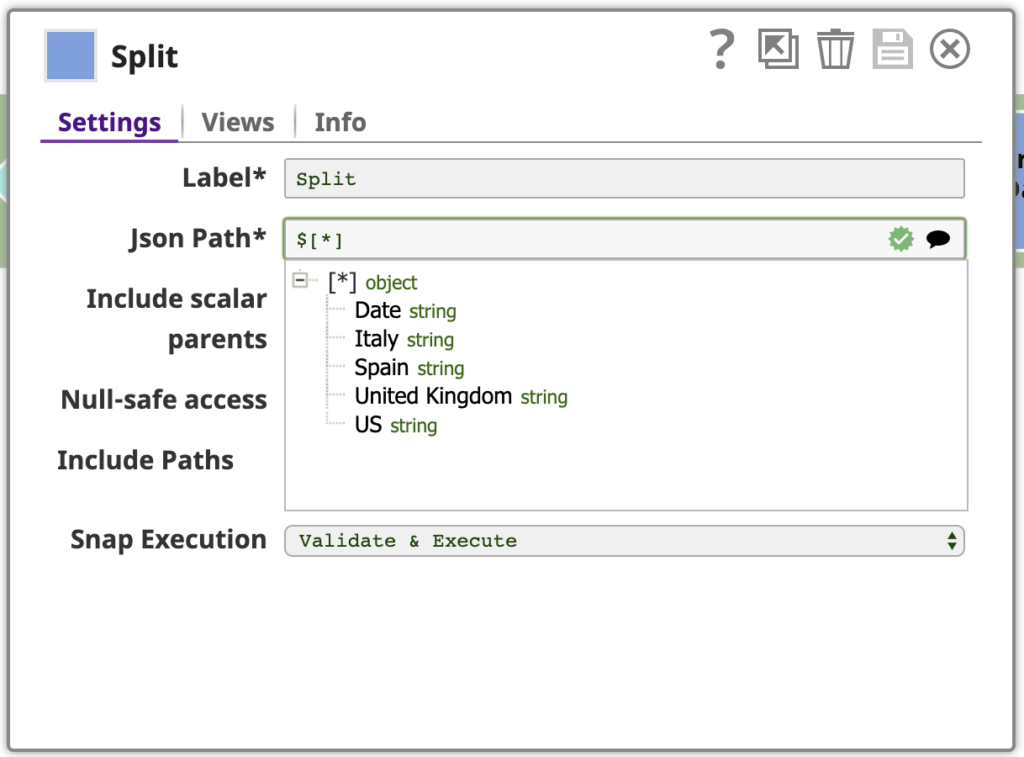
Hier ist die Ausgabe des JSON-Splitters für die Zeilen mit US-Werten:
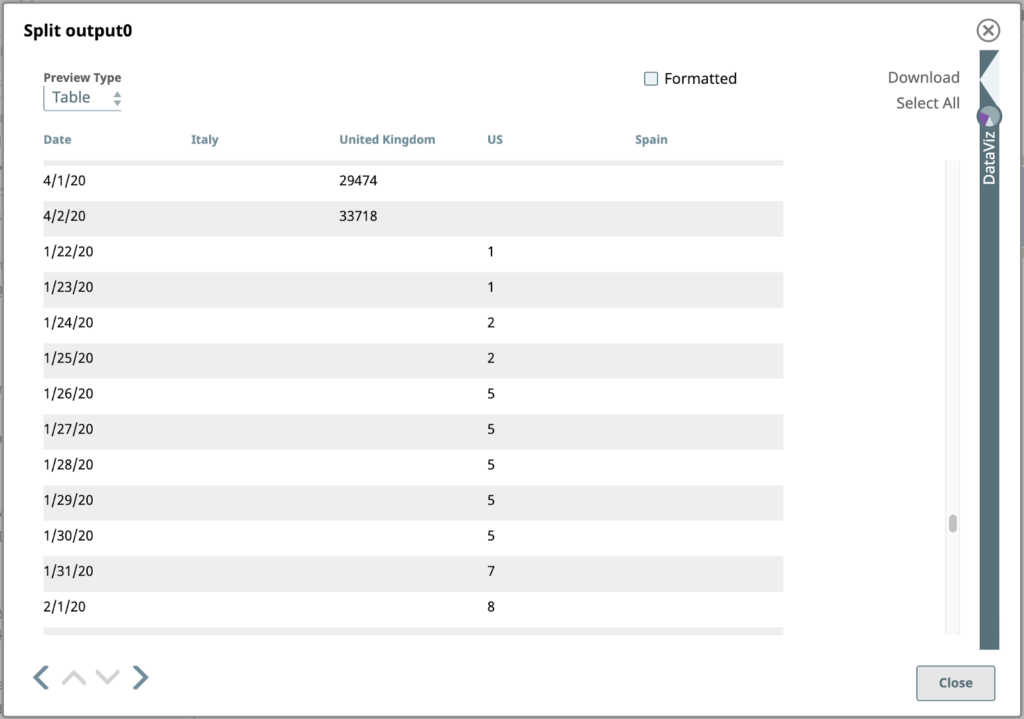
6. Nach Datum sortieren
Als nächstes sortieren Sie die Daten nach Datum. Dies ist einfach mit der Sortieren Snap, der wie gezeigt konfiguriert ist:
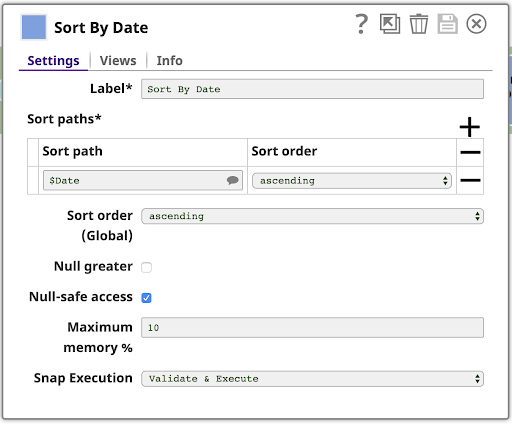
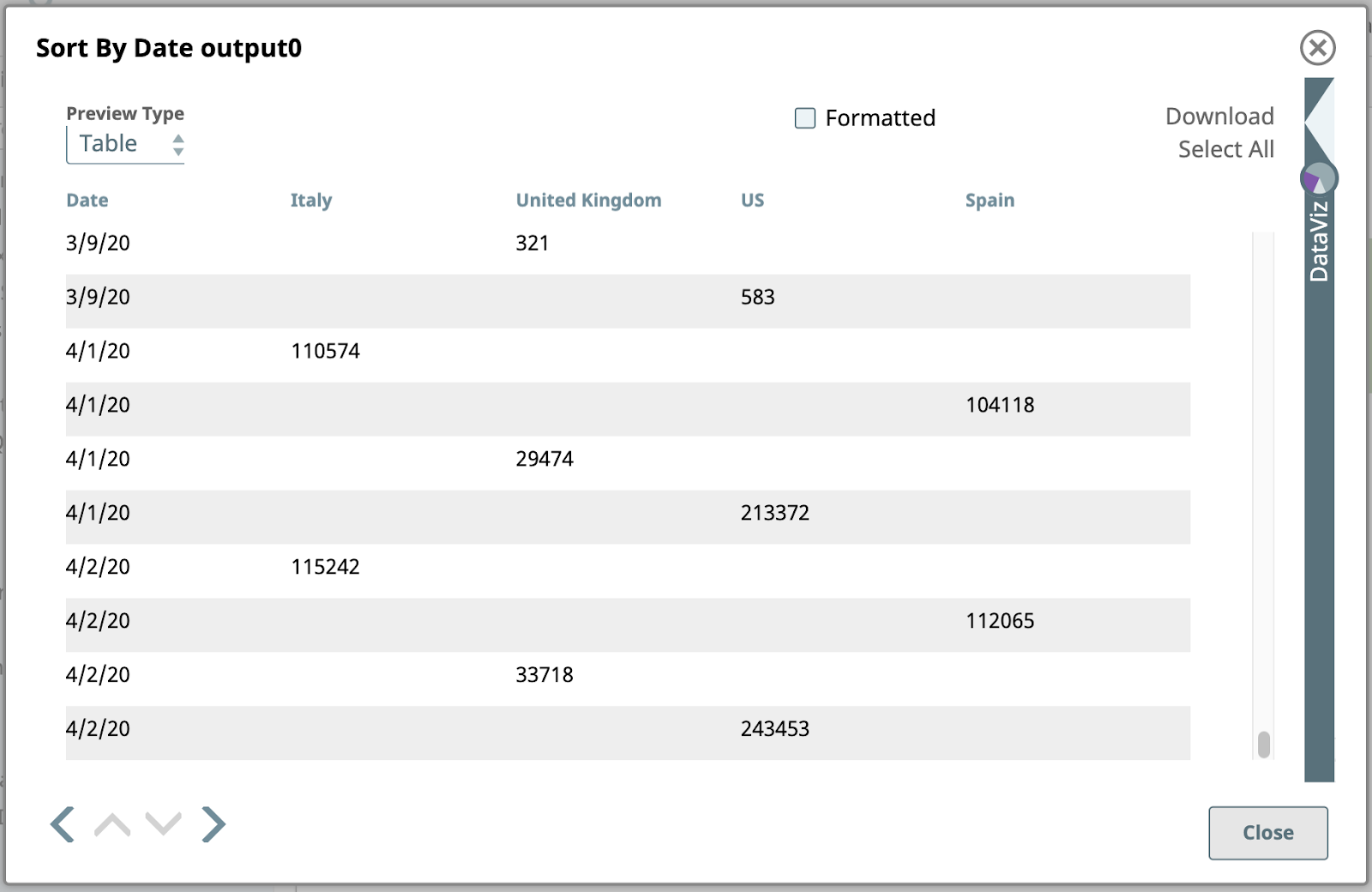
Dies ist die sortierte Ausgabe:
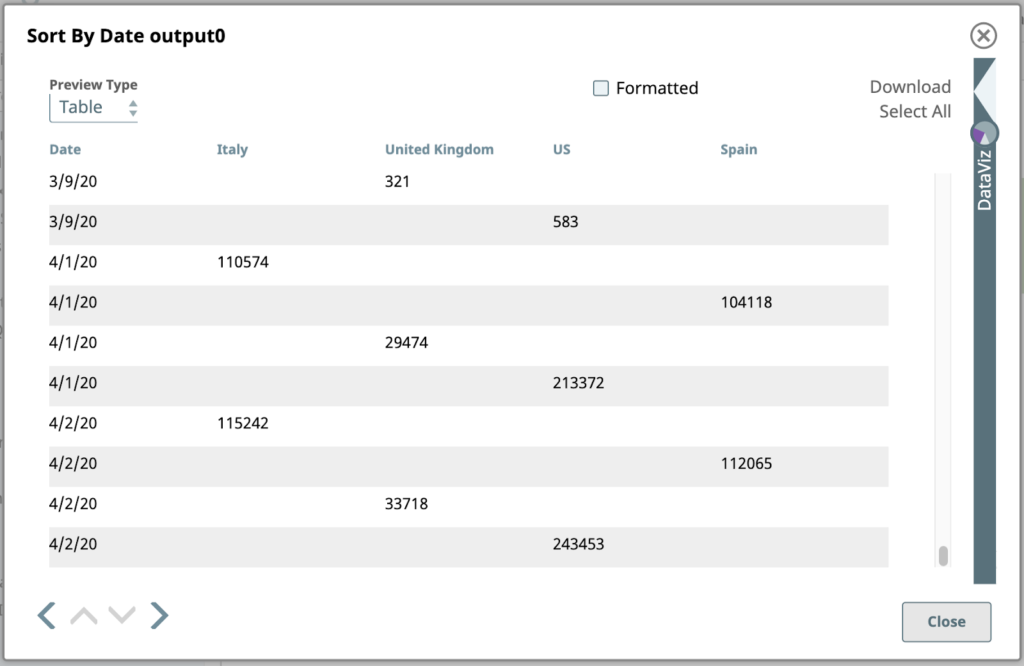
Beachten Sie, dass die Datumswerte hier vom Typ String sind, also alphanumerisch sortiert werden, ohne dass sie als Datum interpretiert werden. Das bedeutet, dass "3/9/20" am Ende der Daten für März steht. Wir könnten damit umgehen, wenn wir das müssten, aber wir tun es nicht. Diese Ausgabe ist für unsere weiteren Schritte vollkommen ausreichend.
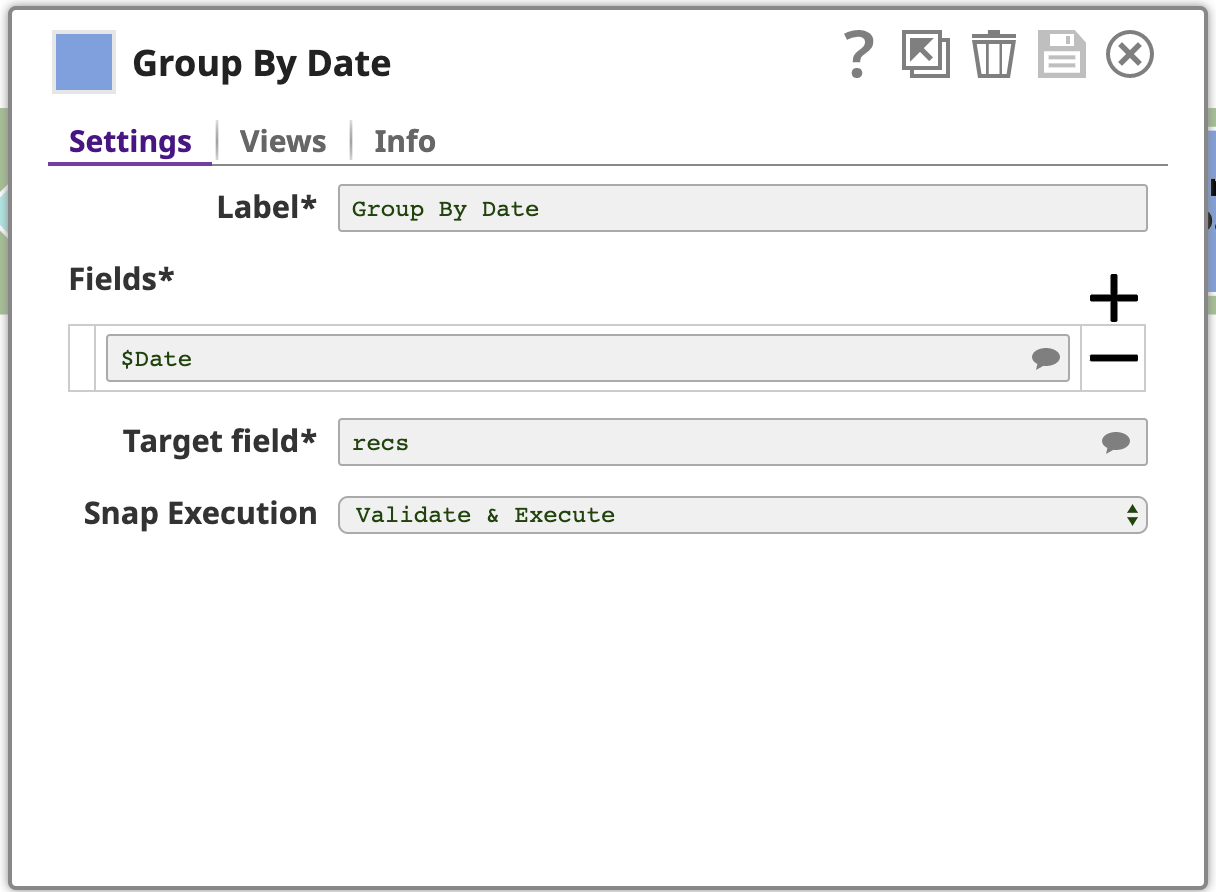
7. Gruppieren nach Datum
Da die Dokumente nun nach Datum sortiert sind, können wir die Funktion Gruppieren nach Feldern Snap verwenden, um Dokumente nach einer Feldklassifikation zu gruppieren. Beachten Sie, dass dies nur dann korrekt funktioniert, wenn die Daten auch tatsächlich sortiert sind.
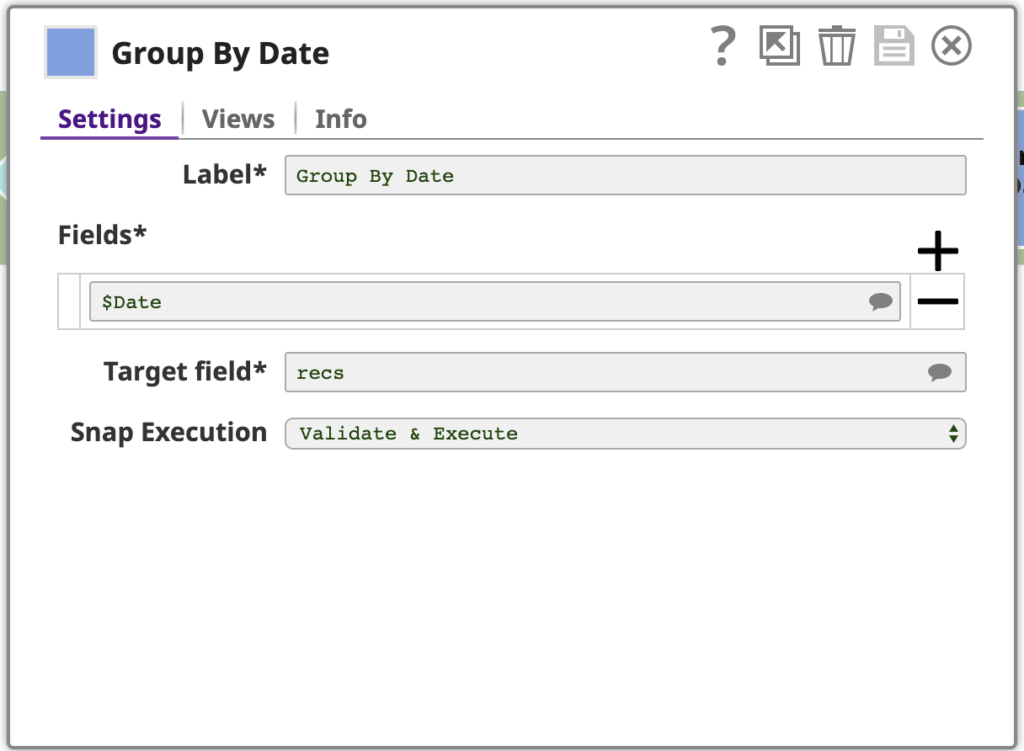
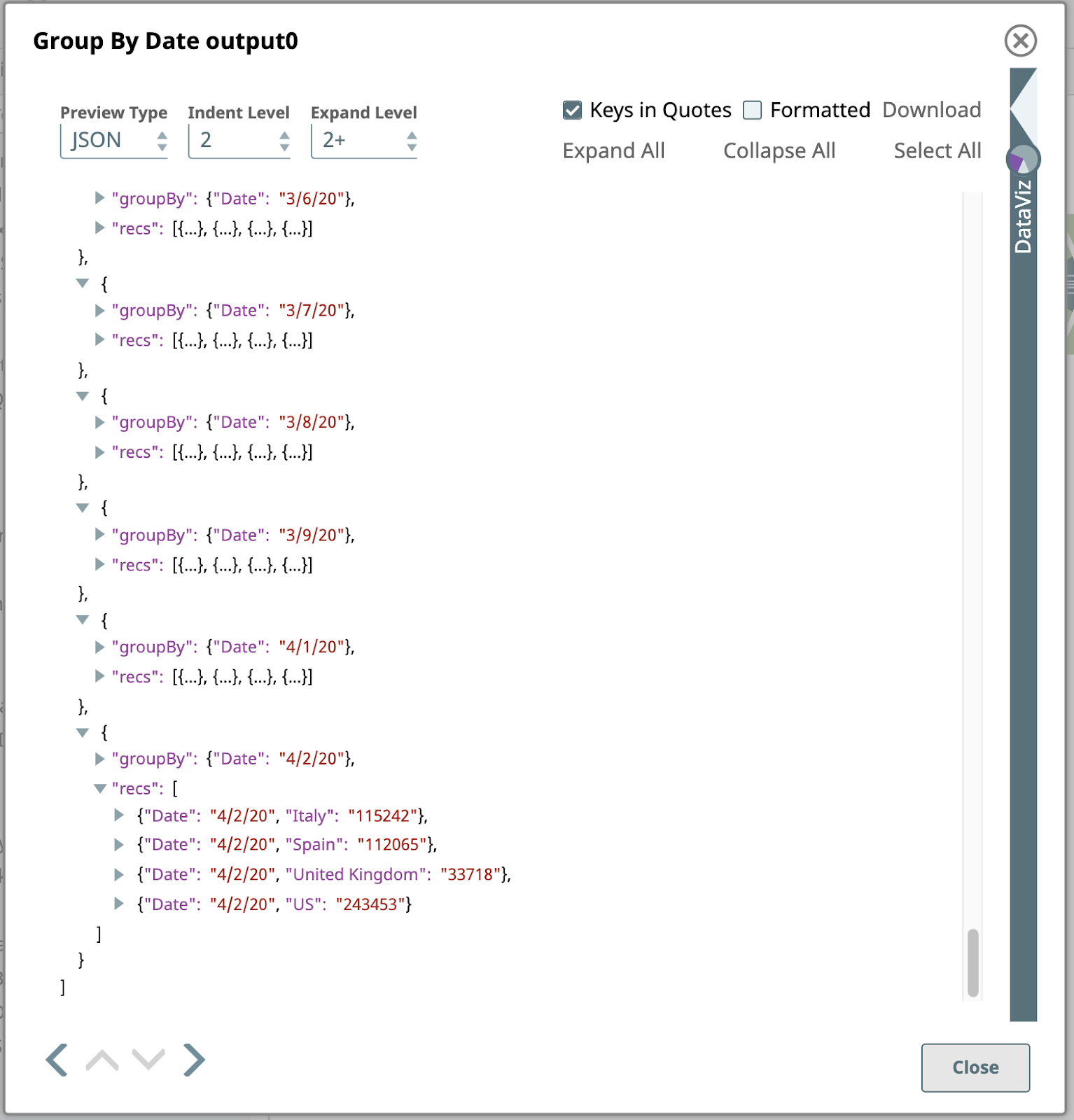
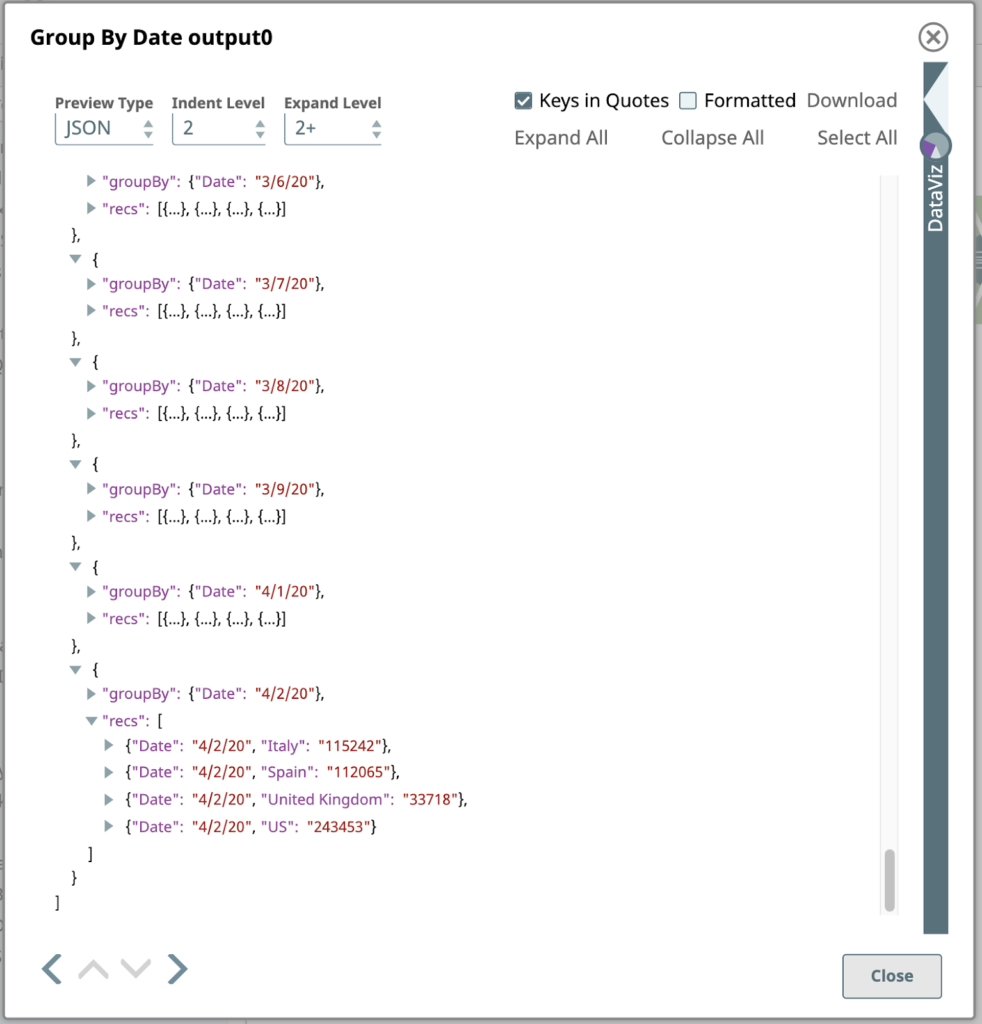
Dieser Snap ist mit einem oder mehreren Felder zu gruppieren, in diesem Fall nur das Datum. Der Snap sammelt jede Gruppe von Eingabedokumenten mit demselben Datum Feldwert und gibt ein einzelnes Dokument aus, das die Daten aus diesen Eingabedokumenten enthält. Die Daten werden in einem Array im Ausgabedokument verschachtelt, wobei das Array unter einem Feld gespeichert wird, das durch das Zielfeld Einstellung: recs. Um dies zu verdeutlichen, sehen wir uns die Ausgabe als JSON an, hier die letzte Seite:
Der letzte Schritt in dieser Pipeline ist ein weiterer Mapper.
8. Reduzieren Sie
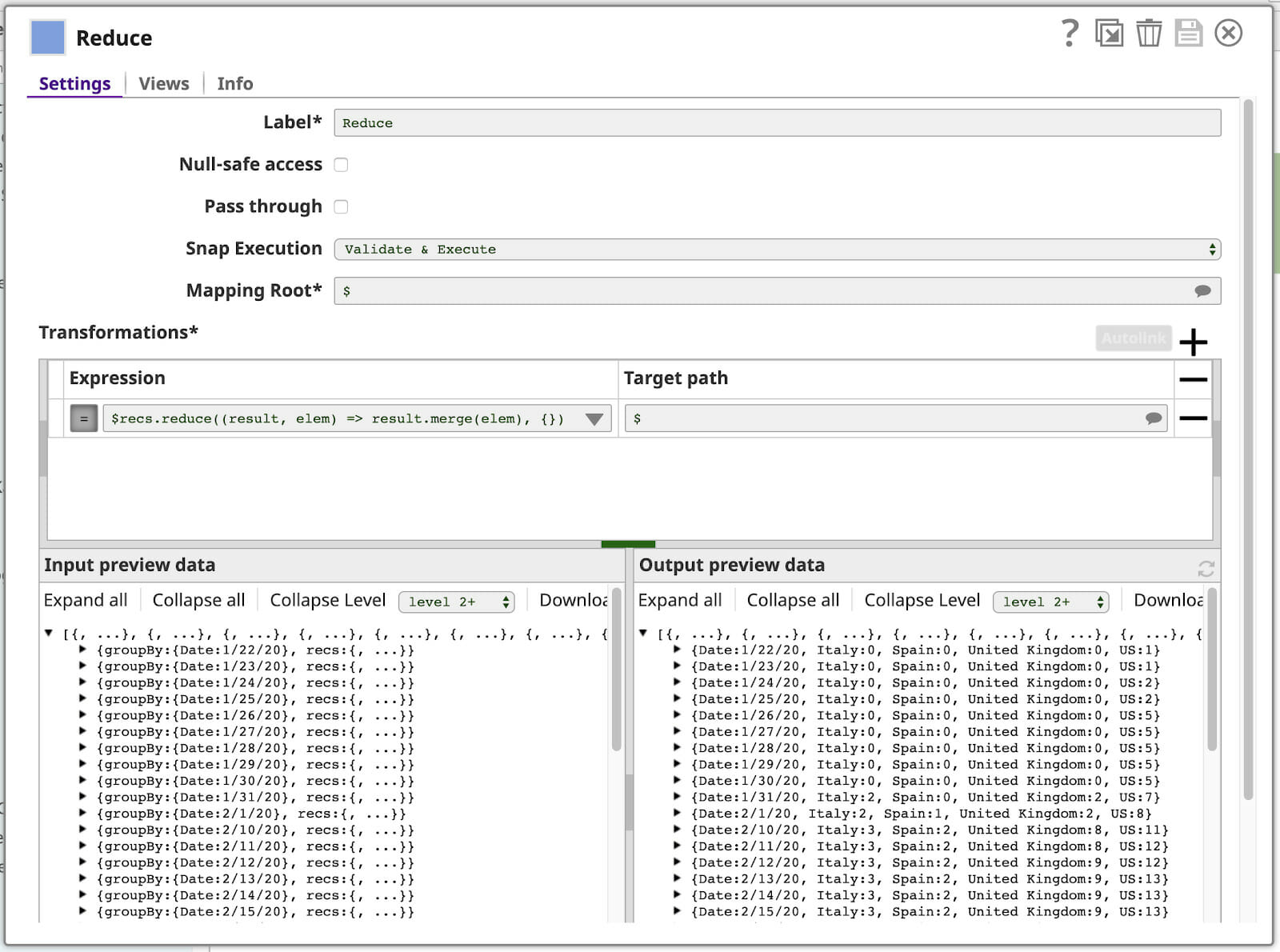
Sie haben bereits die Karte Funktion der Ausdruckssprache gesehen, die in unserem letzten Mapper. Vielleicht klingelt es bei Ihnen, wenn Sie mit dem MapReduce-Programmiermodell vertraut sind, das den Kern der "Big Data"-Verarbeitung bildet. Nun, wissen Sie was? Die SnapLogic-Ausdruckssprache hat auch eine reduzieren Funktion, die wir in unserem letzten Mapper. Hier ist unsere Konfiguration (mit einigen eingeklappten Seitenflächen):
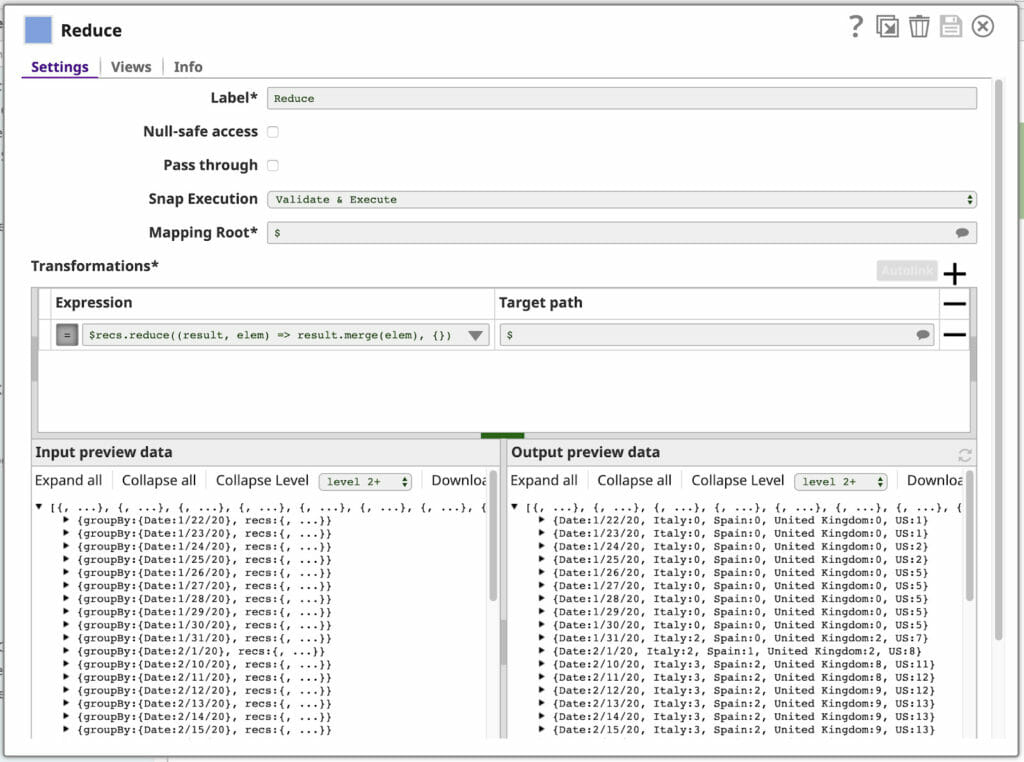
Lassen Sie uns den Ausdruck aufschlüsseln:
$recs.reduce((result, elem) => result.merge(elem), {})
$recs ist das Array in jedem Eingabedokument, das wie folgt aussieht:

Dieses enthält alles, was wir für das Ausgabedokument benötigen.
.reduzieren.(Funktion, AnfangsWert) reduziert dieses Array mit Hilfe der angegebenen Funktion auf einen einzigen Wert, wobei die Iteration mit dem angegebenen Anfangswert beginnt. Hier wird diese Funktion als JavaScript-Lambda-Ausdruck ausgedrückt:
(Ergebnis, Elem) => Ergebnis.zusammenführen(Elem)
Die Parameter der Funktion werden auf der linken Seite der Anweisung => Ergebnis und elem. Der Ausdruck auf der rechten Seite wird verwendet, um das Ergebnis der Funktion zu berechnen. Die Seite reduzieren Funktion ruft diese Funktion einmal für jedes Element im Array auf, wobei die Ausgabe jedes Aufrufs als Eingabe für den nachfolgenden Aufruf über die Funktion Ergebnis Parameter und den Wert des nächsten Array-Elements über den elem Parameter. Der initialValue der an reduzieren übergebene Wert ist der Wert des Ergebnis Parameters, der für die erste Iteration verwendet wird. In diesem Fall verwenden wir die zusammenführen Funktion, um dieses Array zu einem einzigen Objekt zusammenzuführen.
Dies wird leichter zu verstehen sein, wenn wir jede Iteration zeigen:
| Iteration | Eingabe: Ergebnis | Eingabe: Elem | Ausgabe: result.merge(elem) |
| 1 | {} (der initialValue) | {“Date”, “4/20/20”, “Italy”: “115242”} | {“Date”, “4/20/20”, “Italy”: “115242”} |
|
2 |
{“Date”, “4/20/20”, “Italy”: “115242”} | {“Date”, “4/20/20”, “Spain”: “112065”} | {“Date”, “4/20/20”, “Italy”: “115242”, “Spain”: “112065”} |
|
3 |
{“Date”, “4/20/20”, “Italy”: “115242”, “Spain”: “112065”} | {“Date”, “4/20/20”, “United Kingdom”: “33718”} | {“Date”, “4/20/20”, “Italy”: “115242”, “Spain”: “112065”, “United Kingdom”: “33718”} |
|
4 |
{“Date”, “4/20/20”, “Italy”: “115242”, “Spain”: “112065”, “United Kingdom”: “33718”} | {“Date”, “4/20/20”, “US”: “243453”} | {“Date”, “4/20/20”, “Italy”: “115242”, “Spain”: “112065”, “United Kingdom”: “33718”, “US”: “243453”} |
Bei jeder Iteration von reduzierenwird ein weiteres Element des Arrays in das Ausgabeobjekt eingefügt. Jedes Element hat denselben Datumswert, so dass dieser nach jeder Iteration gleich bleibt, aber wir erhalten ein einziges Objekt, das alle Länderfallzahlen für dieses Datum enthält.
Sie können die resultierenden Ausgabedokumente in der Ausgabevorschau-Daten in der unteren rechten Ecke des Fensters Reduzieren Mappers (siehe oben).
Visualisierung der Daten
Sehen wir uns die Ausgabe der Reduzieren Mappers aus dem vorherigen Schritt.
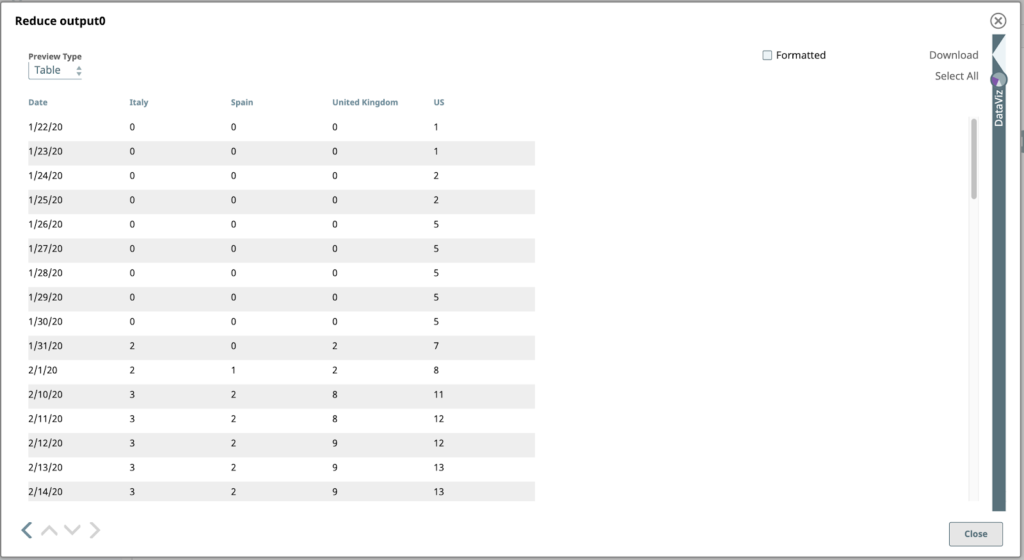
Bingo! Unsere Daten sehen endlich charttauglich aus. Öffnen wir die DataViz Panel, indem wir auf den nach links zeigenden Pfeil direkt über dem DataViz-Label auf der rechten Seite des Fensters klicken. Das Panel erweitert sich und nimmt die rechte Hälfte ein.
Um das endgültige Liniendiagramm zu sehen, setzen Sie den Diagrammtyp auf "Liniendiagramm - Datum als X-Achse", X-Achse auf "Datum" und Zu visualisierender Schlüssel auf die Ländernamen, die Sie visualisieren möchten.
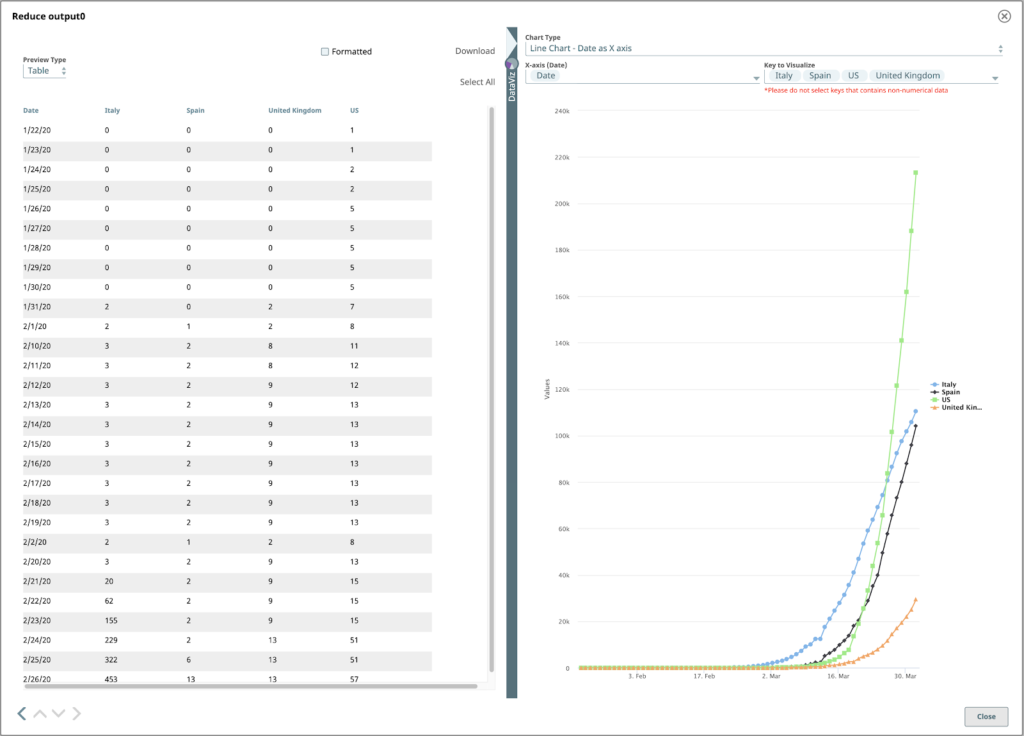
Ich hoffe, dieser Blog hat Ihnen geholfen, die leistungsstarken Funktionen der SnapLogic-Plattform besser zu verstehen, mit denen Sie COVID-19-Daten lesen und visualisieren können.
Ich wünsche Ihnen und den Ihren viel Glück in dieser schwierigen Zeit.
Bleiben Sie gesund, bleiben Sie sicher!