






Unternehmen sind heute auf der Suche nach prädiktiven Analysen, die ihnen den Weg in die Zukunft weisen. Jedes Unternehmen benötigt maßgeschneiderte Modelle für maschinelles Lernen, die für seine spezifischen Geschäftsanforderungen entwickelt werden. Im Bereich der Finanzdienstleistungen kann ein wertvolles Modell vorhersagen, welcher Kreditnehmer mit hoher Wahrscheinlichkeit seinen Kredit nicht zurückzahlen wird, welches Gegenseitigkeitsprodukt für einen Kunden geeignet ist usw. Dateningenieure und Datenwissenschaftler sehen sich jedoch bei der Erstellung effektiver maschineller Lernmodelle mit einer Reihe von Herausforderungen konfrontiert, wie z. B. schlechte Qualität des Trainingsdatensatzes, hoher Zeitaufwand für die Vorbereitung der Daten für das Training und große Datenmengen, die für das Training der Modelle benötigt werden.
In diesem Beitrag werden wir einen Anwendungsfall für Finanzdienstleistungen untersuchen, bei dem es darum geht, Kreditinformationen auszuwerten, um vorherzusagen, ob ein Kreditnehmer mit einem Kredit in Verzug geraten wird. Der Basisdatensatz wurde aus Kreditdaten von LendingClub abgeleitet. Dieser Datensatz enthält Kreditgeberdaten über Kredite, die an Einzelpersonen vergeben wurden. Die Daten werden dann mit Arbeitslosendaten von Knoema auf dem Snowflake Data Marketplace angereichert. Wir verwenden SnapLogic, um die Daten zu transformieren und aufzubereiten, die später für die Erstellung von ML-Modellen verwendet werden können.
Voraussetzungen
In diesem Beitrag wird davon ausgegangen, dass Sie die folgenden Voraussetzungen erfüllen:
- Ein Schneeflocken-Konto
- Daten in einer Tabelle in Snowflake
- Ein Amazon Simple Storage Service (Amazon S3)-Bucket, in den SnapLogic das erstellte ML-Modell laden kann.
Einrichten der Datenquelle in SnapLogic
In diesem Abschnitt behandeln wir die Einrichtung von Snowflake als Datenquelle in SnapLogic. In diesem Beitrag wird davon ausgegangen, dass Sie Zugriff auf SnapLogic haben. Weitere Informationen zu den Voraussetzungen finden Sie unter Erste Schritte mit SnapLogic.
Erstellen Sie eine neue Pipeline
Um eine Pipeline zu erstellen, führen Sie die folgenden Schritte aus:
- Klicken Sie im Designer auf das Symbol [+] links neben den Registerkarten. Das Dialogfeld Neue Pipeline konfigurieren wird geöffnet.
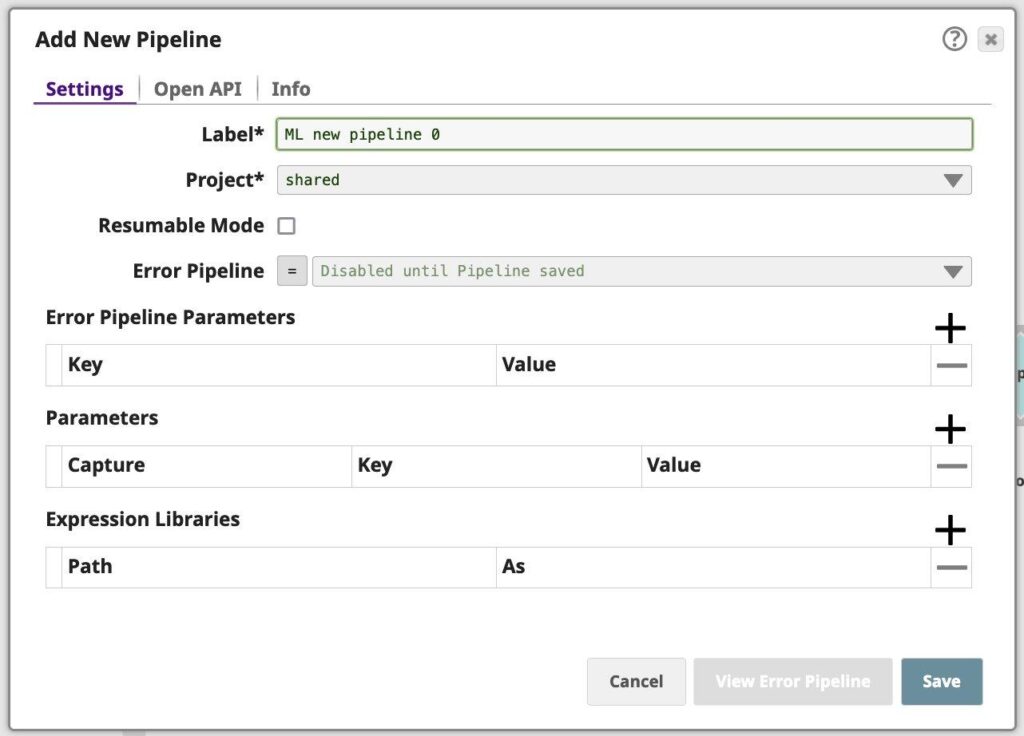
Abbildung 1: Eigenschaftsblatt der Pipeline - Modify the Label (pipeline name) and project for the pipeline if necessary. Unless otherwise noted, the names of any asset or project is limited to UTF-8 alphanumeric characters and these punctuation characters !”#$%&'()*+,-.:;<=>?@[\]^_`{|}~.
- Wenn Sie wissen, welche Parameter Sie für diese Pipeline definieren müssen, können Sie dies jetzt oder später über das Dialogfeld Pipeline-Eigenschaften tun.
- Wenn Sie eine Ausdrucksbibliothek verwenden, können Sie diese jetzt oder später über das Dialogfeld Pipelineeigenschaften hinzufügen.
- Klicken Sie auf Speichern.
Hinzufügen von Snowflake als Datenquelle in SnapLogic
Als nächstes fügen wir Snowflake als Datenquelle hinzu.
- Ziehen Sie eine Schneeflocke - Wählen Sie Fang auf die Leinwand und klicken Sie auf den Fang, um seine Einstellungen zu öffnen. Klicken Sie auf die Registerkarte Konto. Sie können nun ein neues Konto erstellen.
- Klicken Sie im Dialogfeld Kontoreferenz auf Konto hinzufügen.
- Wählen Sie den Ort, an dem Sie das Konto erstellen möchten, wählen Sie Snowflake S3 Datenbank-Konto als Kontotyp und klicken Sie auf Weiter. Das Dialogfeld Konto hinzufügen für den Kontotyp wird angezeigt.
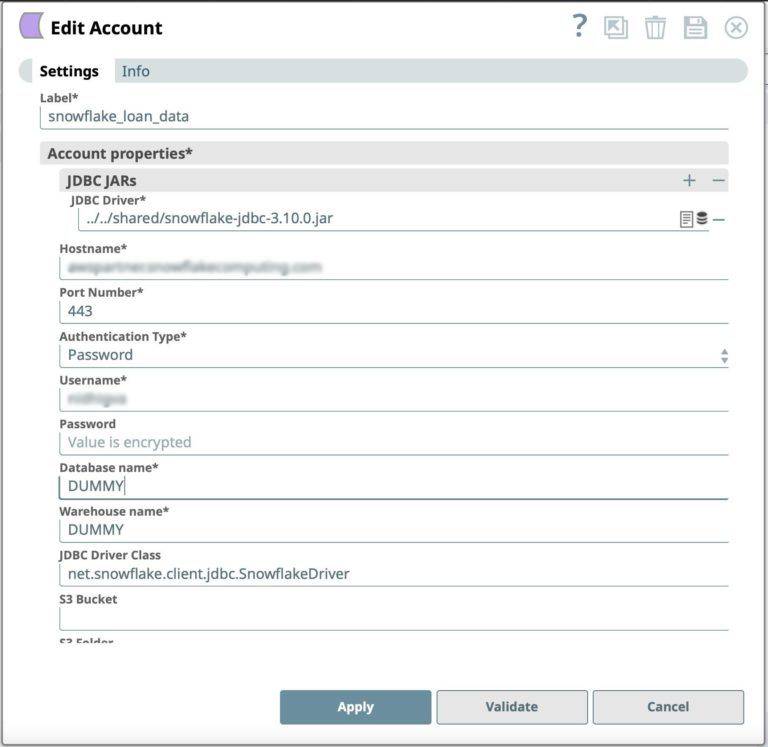
Abbildung 2: Snowflake Snap Kontodefinition - Klicken Sie auf Validieren, um das Konto zu überprüfen, wenn der Kontotyp die Validierung unterstützt.
- Klicken Sie auf Übernehmen, um die Konfiguration des Snowflake-Kontos abzuschließen.
- Gehen Sie zur Registerkarte Einstellungen
- Wir wählen die Tabelle aus, in die wir bereits Kreditdaten von Lending Club geladen haben.
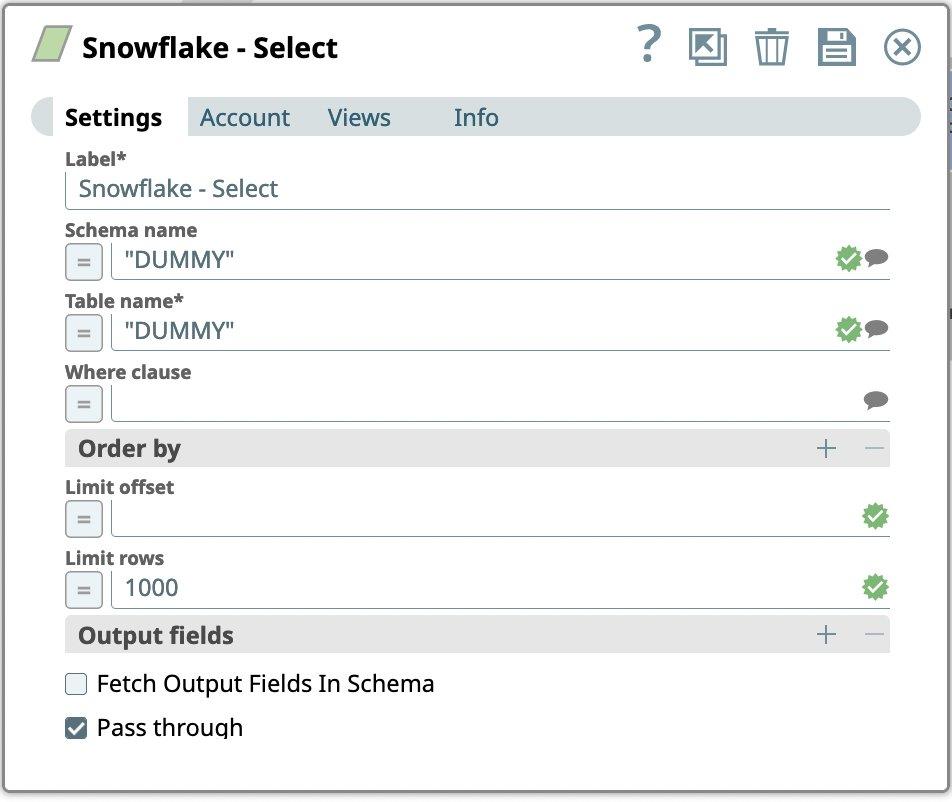
- Geben Sie für das Snowflake-Konto ein:
- Name des Schemas
- Name der Tabelle
- Limit rows auf 1000 setzen
- Drücken Sie das Symbol Speichern
Hinzufügen von ML-Snaps zur Pipeline für maschinelles Lernen mit SnapLogic
SnapLogic Data Science enthält die folgenden ML Snap Packs, um ML-Projekte zu beschleunigen.
- ML Data Preparation Snap Pack - Das ML Data Preparation Snap Pack automatisiert verschiedene Datenvorbereitungsaufgaben für ein maschinelles Lernmodell. SnapLogic Data Science vereinfacht den Prozess der Datenvorbereitung und des Feature-Engineerings mithilfe einer visuellen Schnittstelle.
- ML Core Snap Pack - Das ML Core Snap Pack beschleunigt die Erstellung, das Training und das Testen Ihres Modells für maschinelles Lernen. Nutzen Sie das ML Core Snap Pack, um die Modellschulungs- und Evaluierungsphase des Lebenszyklus des maschinellen Lernens zu optimieren.
- ML Analytics Snap Pack - Mit dem ML Analytics Snap Pack erstellen Sie schneller bessere Trainingsdatensätze für Ihre Machine-Learning-Modelle. Gewinnen Sie mit dem ML Analytics Snap Pack schnell Erkenntnisse aus Ihren Daten.
- Natural Language Processing Snap Pack - Das Natural Language Processing Snap Pack führt Operationen zur Verarbeitung natürlicher Sprache durch.
Zeilen mit fehlenden Werten verwerfen
Der erste Schritt, den wir durchführen wollen, ist die Verarbeitung fehlender Werte in einem Datensatz durch Weglassen oder Imputieren (Ersetzen) von Werten.
- Ziehen Sie den Fang "Fehlende Werte bereinigen" auf den Canvas und klicken Sie auf den Fang, um seine Einstellungen zu öffnen.
- Spalten REVOL_UTIL hinzufügen, um Zeilen aus dem eingehenden Datensatz zu entfernen, wenn der Wert fehlt
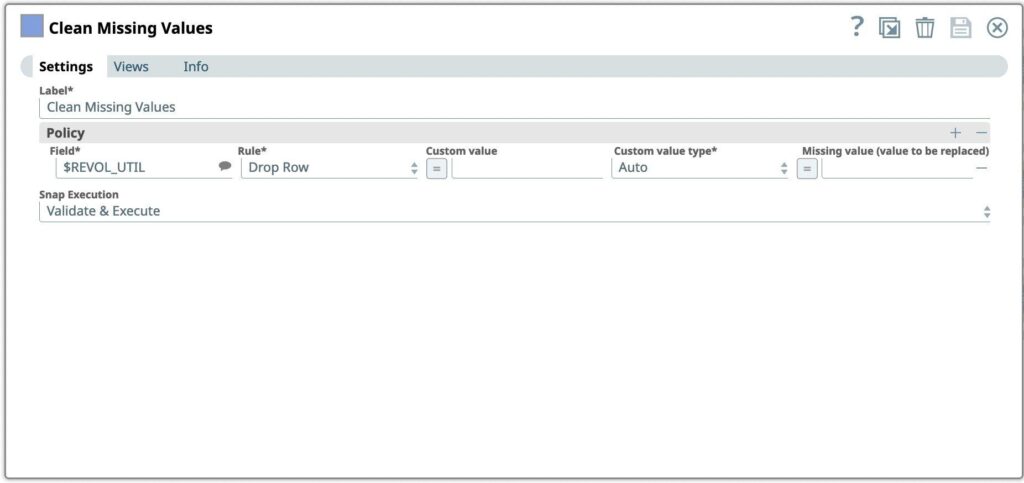
Abbildung 4: Bereinigung fehlender Werte Snap-Einstellungen
Daten umwandeln
Als Nächstes wollen wir die eingehenden Daten mit Hilfe der gegebenen Mappings transformieren und neue Ausgabedaten erzeugen. Dieser Snap wertet einen Ausdruck aus und schreibt das Ergebnis in den angegebenen Zielpfad.
- Ziehen Sie den Mapper-Snap auf den Canvas und klicken Sie auf den Snap, um seine Einstellungen zu öffnen.
- Wenn wir uns die Spalten ansehen, stellen wir fest, dass MNTHS_SINCE_LAST_DELINQ und MNTHS_SINCE_LAST_RECORD höchstwahrscheinlich als Zahlentyp und nicht als String dargestellt werden sollten.
- Wenn wir uns die Daten ansehen, können wir feststellen, dass die Felder EMP_TITLE, URL, DESCRIPTION und TITLE in unserem Anwendungsfall wahrscheinlich keinen Wert für unser Modell haben, also lassen wir sie weg.
- Als Nächstes suchen wir nach Spalten, bei denen es sich um Zeichenketten handelt, die so formatiert werden können, dass sie für eine spätere Verwendung besser geeignet sind. Bei der Durchsicht unseres Datensatzes sehen wir, dass INT_RATE in einem zukünftigen Modell als Fließkommazahl nützlich sein könnte, aber ein nachgestelltes Zeichen von % hat. Bevor wir eine andere integrierte Transformation (parse as type) verwenden können, um dies in eine Fließkommazahl umzuwandeln, müssen wir das nachgestellte Zeichen entfernen.
- Anschließend wird der String-Wert in der Spalte TERM aktualisiert, um das Leerzeichen durch '_' zu ersetzen.
- Wir erstellen eine neue boolesche Spalte LOAN_STATUS auf der Grundlage von LOAN_DEFAULT.
- Klicken Sie auf das [+]-Zeichen neben der Mapping-Tabelle, um einen neuen Ausdruck hinzuzufügen. Transformation, die zur Umwandlung von Daten in Spalten angewendet werden soll:
Ausdruck* Zielpfad parseFloat(+$MNTHS_SINCE_LAST_DELINQ) MNTHS_SINCE_LAST_DELINQ parseFloat(+$MNTHS_SINCE_LAST_RECORD) MNTHS_SINCE_LAST_RECORD parseFloat(+$INT_RATE.replace("%", "")) $INT_RATE_PERCENTAGE $TERM.replace(" Monate", "_Monate") $TERM $EMP_TITLE $URL $BESCHREIBUNG $TITEL $MTHS_SINCE_LAST_MAJOR_DEROG $LOAN_DEFAULT == 1 ? true:false $LOAN_DEFAULT_STATUS - Drücken Sie das Symbol Speichern
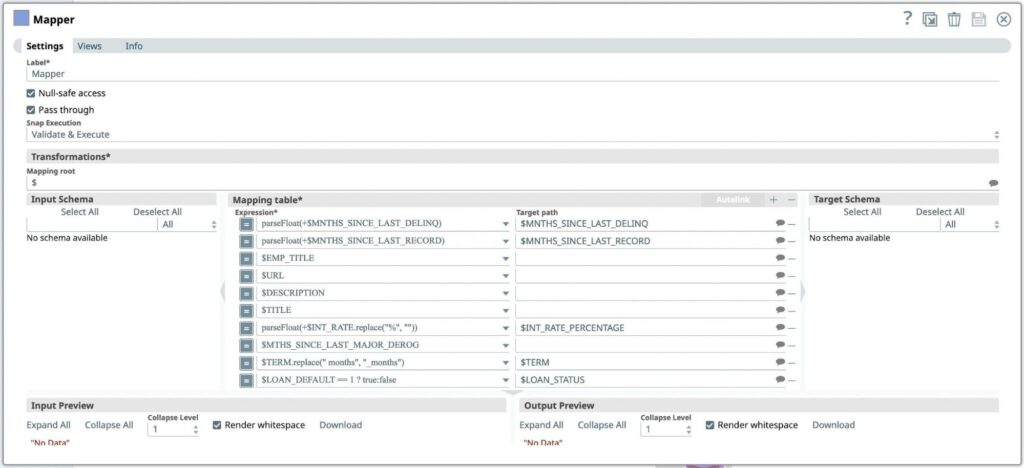
Abbildung 5: Mapper Snap Einstellungen
Arbeitsdaten vom Snowflake-Marktplatz abrufen
Wir werden nun Arbeitsdaten von Snowflake Marketplace hinzufügen, die für die Verbesserung von ML-Modellen hilfreich sein können. Bei der Analyse von Kreditausfällen kann es sinnvoll sein, die Beschäftigungsdaten in der Region zu betrachten. Wir werden den Knoema - Arbeitsdatenatlas vom Snowflake Marketplace in die Snowflake-Datenbank übertragen, wo die Lastdaten bereits vorhanden sind.
Als nächstes fügen wir Snowflake als Datenquelle hinzu.
- Ziehen Sie einen Snowflake - Execute Snap auf den Canvas und klicken Sie auf den Snap, um seine Einstellungen zu öffnen. Klicken Sie auf die Registerkarte Konto.
- Wählen Sie das im vorherigen Schritt erstellte Konto aus der Liste Konto-Referenz Dialog.
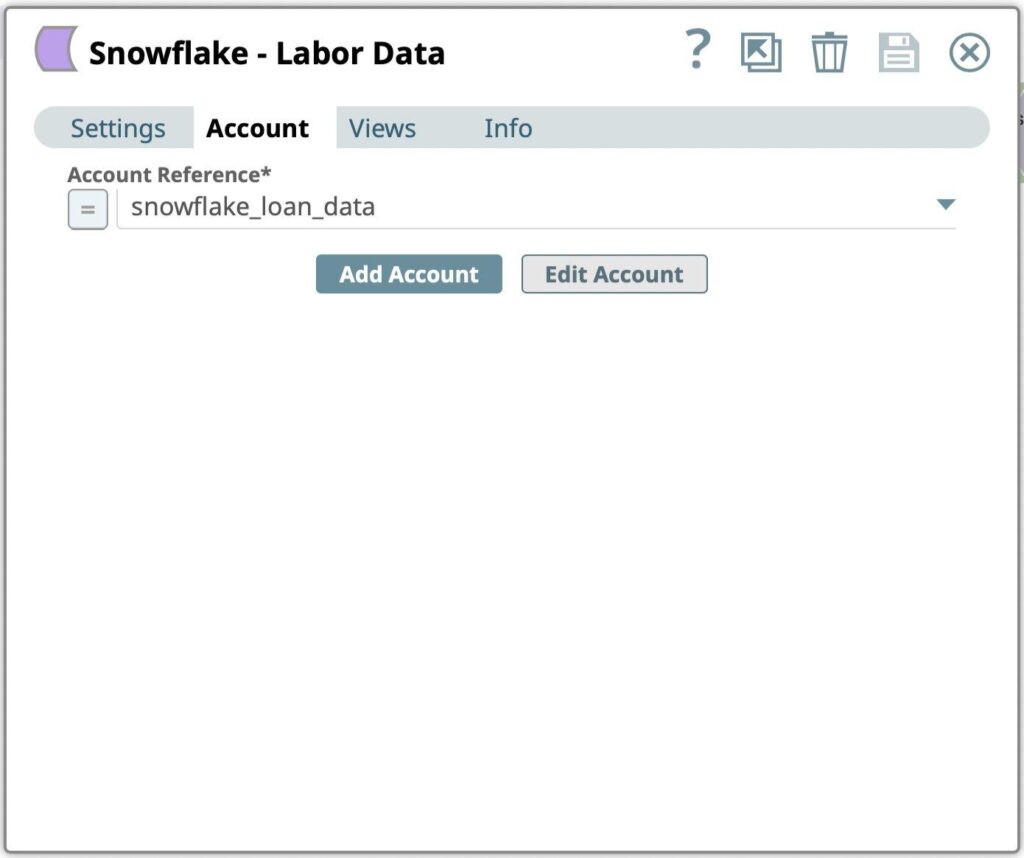
Abbildung 6: Snowflake Select Snap Kontoauswahl - Gehen Sie zur Registerkarte Einstellungen
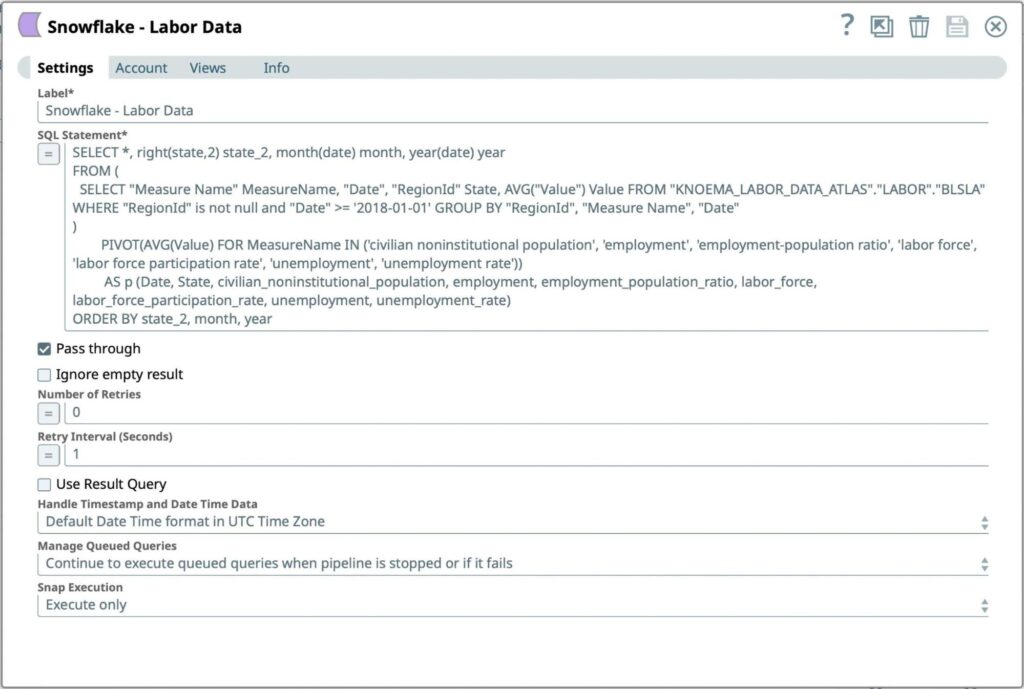
Abbildung 7: Snowflake Select Snap Einstellungen - Geben Sie die SQL-Abfrage ein, die ausgeführt werden soll, um formatierte Arbeitsdaten vom Snowflake-Konto abzurufen:
- SQL-Anweisung
- Drücken Sie das Symbol Speichern
Profil-Daten
- Ziehen Sie den Fang "Kopieren" auf das Canvas. Belassen Sie es bei den Standardeinstellungen.
- Ziehen Sie den Profilfang auf den Canvas. Dies ist hilfreich bei der Ableitung einer statistischen Analyse der Daten in Datensätzen.
Eine Hot-Codierung durchführen
Als nächstes wollen wir nach kategorischen Daten in unserem Datensatz suchen. SnapLogic kann kategoriale Daten sowohl mit One-Hot Encoding als auch mit Integer Encoding kodieren. Wenn wir uns unseren Datensatz ansehen, können wir feststellen, dass die Spalten TERM, HOME_OWNERSHIP und PURPOSE kategorisch zu sein scheinen.
- Ziehen Sie den Fang kategorisch zu numerisch auf die Leinwand und klicken Sie auf den Fang, um seine Einstellungen zu öffnen.
- Geben Sie in den Einstellungen unter Policy diese Spaltennamen als Field ein und wählen Sie One Hot Encoding als Rule.
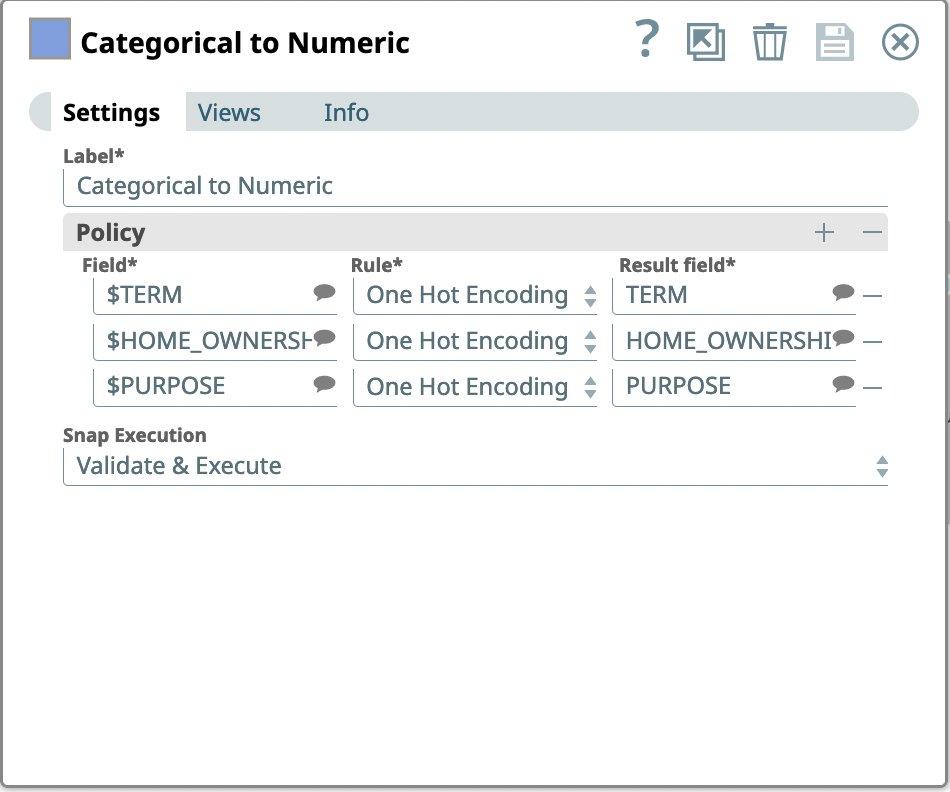
Abbildung 8: Einstellungen für kategorischen zu numerischen Snap
Laden Sie die vorbereiteten Daten in Snowflake
Als nächstes fügen wir Snowflake als Datenquelle hinzu.
- Ziehen Sie einen Snowflake - Bulk Load Snap auf die Leinwand und klicken Sie auf den Snap, um seine Einstellungen zu öffnen. Klicken Sie auf die Registerkarte Konto.
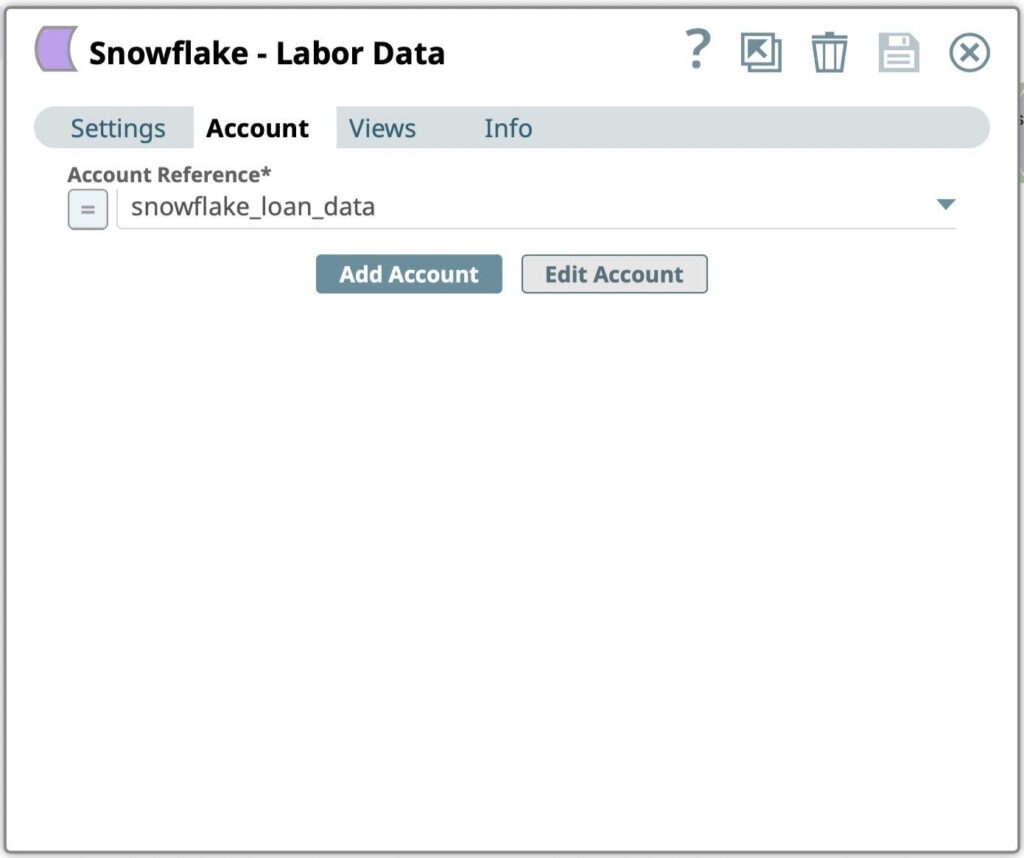
Abbildung 9: Snowflake Bulk Load Snap-Kontoeinstellungen - Wählen Sie im Dialogfeld Kontoreferenz das im vorherigen Schritt erstellte Konto aus. Sie können auch ein neues Konto erstellen, wenn Sie das Ergebnis in einer anderen Snowflake-Datenbank und einem anderen Warehouse speichern möchten.
- Gehen Sie zur Registerkarte Einstellungen
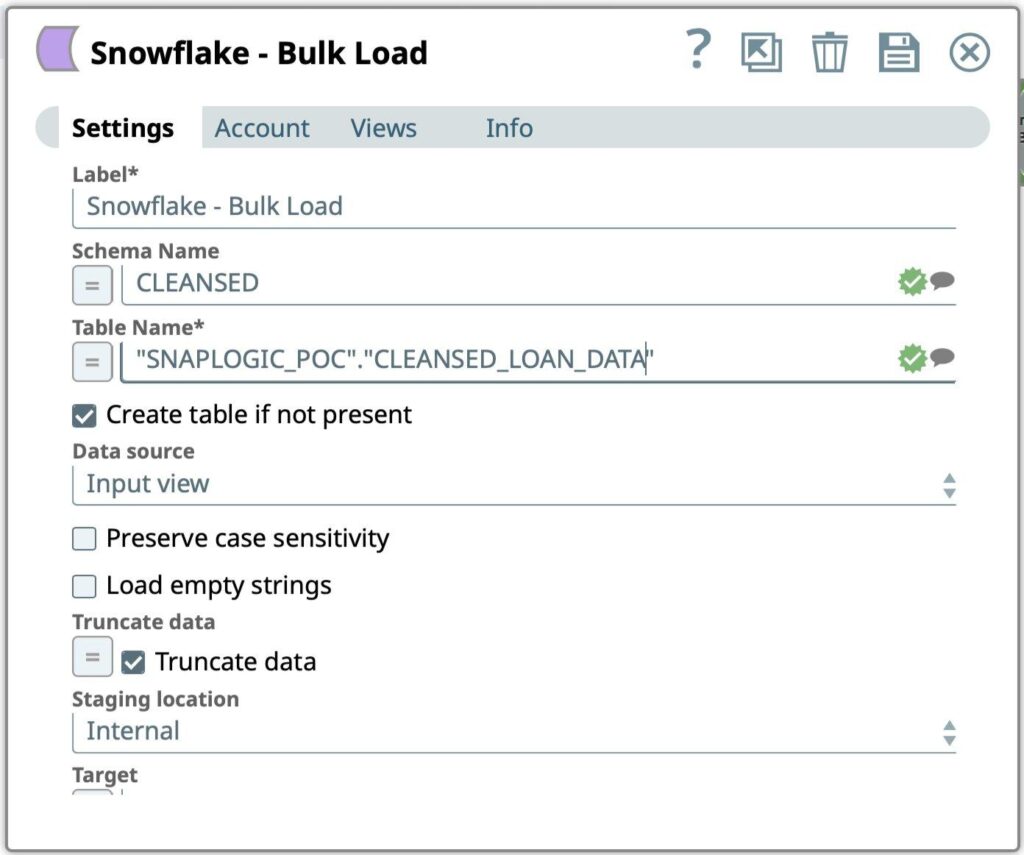
Abbildung 10: Snowflake Bulk Load Snap-Einstellungen - Geben Sie die SQL-Abfrage ein, die ausgeführt werden soll, um formatierte Arbeitsdaten vom Snowflake-Konto abzurufen:
- Schema Name
- Tabelle Name
- Drücken Sie das Symbol Speichern
Nachfolgend sehen Sie einen Screenshot der in SnapLogic erstellten End-to-End-Datenvorbereitungspipeline.
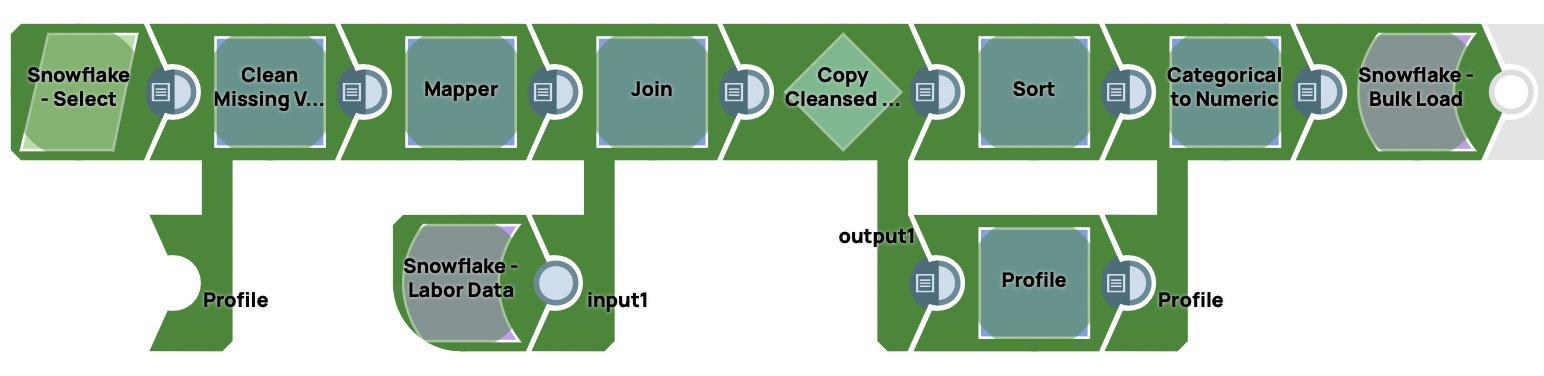
Wenn die Pipeline ausgeführt wird, lädt sie die Daten in Snowflake. Sie kann ausgelöst oder geplant werden.
Schlussfolgerung
In diesem Beitrag haben wir uns mit der Einrichtung von Snowflake als Datenquelle für SnapLogic befasst, um ein Modell für eine Kreditprognose-Pipeline zu erstellen. Dazu gehörte die Konfiguration des Snowflake-Endpunkts in SnapLogic, der Aufbau einer Pipeline mit Snaps für maschinelles Lernen, das Abrufen von Daten vom Snowflake Marketplace und schließlich das Laden der aufbereiteten Daten zurück in Snowflake. Ich hoffe, dass Sie mit diesem einfach zu bedienenden Prozess in SnapLogic ein maschinelles Lernmodell für Ihre spezifischen Geschäftsanforderungen erstellt haben.







