





YARN ist die Voraussetzung für Enterprise Hadoop. Es bietet Ressourcenmanagement über Hadoop-Cluster hinweg und erweitert die Leistungsfähigkeit von Hadoop auf neue Technologien, damit diese die Vorteile von kostengünstiger, Speicherung und Verarbeitung im linearen Maßstab nutzen können. Es bietet ISVs und Entwicklern einen konsistenten Rahmen für das Schreiben von Datenzugriffsanwendungen, die in Hadoop ausgeführt werden.
Kunden, die einen Data Lake aufbauen, erwarten, dass sie mit den Daten arbeiten können, ohne sie in andere Systeme zu verschieben, indem sie die Verarbeitungsressourcen des Data Lake nutzen. Anwendungen, die YARN nutzen, erfüllen dieses Versprechen und senken die Betriebskosten bei gleichzeitiger Verbesserung der Qualität und der Zeit bis zur Einsichtnahme.
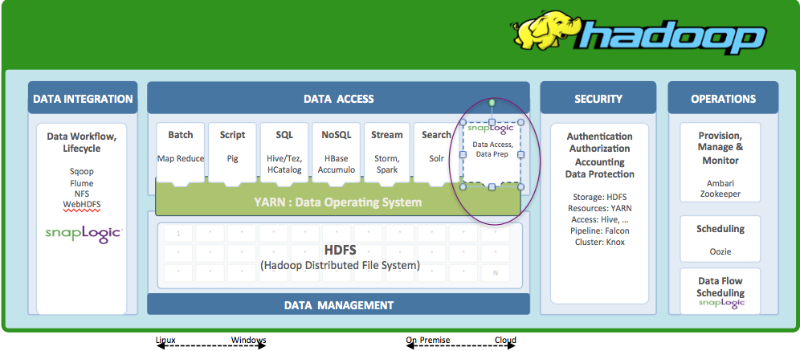
Integration mit YARN
Um die Leistungsfähigkeit von YARN zu nutzen, kann eine Anwendung eines Drittanbieters entweder YARN nativ nutzen oder ein YARN-Framework (Apache Tez, Apache Slider usw.) verwenden, und wenn sie nicht YARN nutzt, liest sie höchstwahrscheinlich direkt aus HDFS.
Für die Integration in YARN gibt es drei große Optionen.
- Volle Kontrolle oder natives YARN: Feinkörnige Kontrolle der Cluster-Ressourcen, die eine elastische Skalierung ermöglicht.
- Interaktion über ein bestehendes YARN-Framework wie MapReduce: Begrenzt auf eine der Optionen Batch, Interaktiv oder Echtzeit. Keine Unterstützung für elastische Skalierung über YARN.
- Interaktion mit Anwendungen, die bereits auf einem YARN-Framework wie Hive laufen: Begrenzt auf sehr spezifische Anwendungen oder Anwendungsfälle, z. B. mit Hive. Keine Unterstützung für elastische Skalierung mit YARN.
Offensichtlich bietet jede Anwendung, die die volle Kontrolle hat und yarn-nativ ist, einen erheblichen Vorteil, um sehr fortgeschrittene Dinge innerhalb von Hadoop mit den Fähigkeiten von YARN zu tun.
Dieser Unterschied ist notwendig, da der Bereich immer interessanter und gleichzeitig verwirrender wird. Hadoop-Anbieter wie Hortonworks bieten sowohl Yarn Native- als auch Yarn Ready-Zertifizierungen an. Yarn Ready bedeutet, dass eine Anwendung mit einer der Yarn-fähigen Anwendungen wie Hive arbeiten kann und auf diese beschränkt ist, während Yarn Native volle Kontrolle und feinkörnigen Zugriff auf Cluster-Ressourcen bedeutet.
SnapLogic ist Yarn Native. Das bedeutet, dass bei steigendem Datenvolumen oder Arbeitsaufkommen die SnapLogic Elastische Integrationsplattform kann automatisch und elastisch skalieren und bei Bedarf mehr Knoten im Hadoop-Cluster nutzen, und wenn diese Arbeitslasten abnehmen, automatisch verkleinern. Dies wird in SnapLogic als die Hadooplex. In diesem Blogbeitrag werden Beispiele für SnapLogic-Pipelines zur Integration großer Datenmengen.
Dieser Beitrag erschien ursprünglich auf LinkedIn. Ravi Dharnikota ist Senior Advisor bei SnapLogic und arbeitet eng mit Kunden an deren Big Data- und Cloud-Referenzarchitekturen.




