Dieser Beitrag veranschaulicht zwei unserer häufig vorkommenden Kundenszenarien:
a) Ein Beispiel für komplexe XML-Verarbeitung und
b) Ein praktisches Beispiel dafür, wie HR On-Boarding/Off-Boarding mit Workday-Daten aussehen könnte
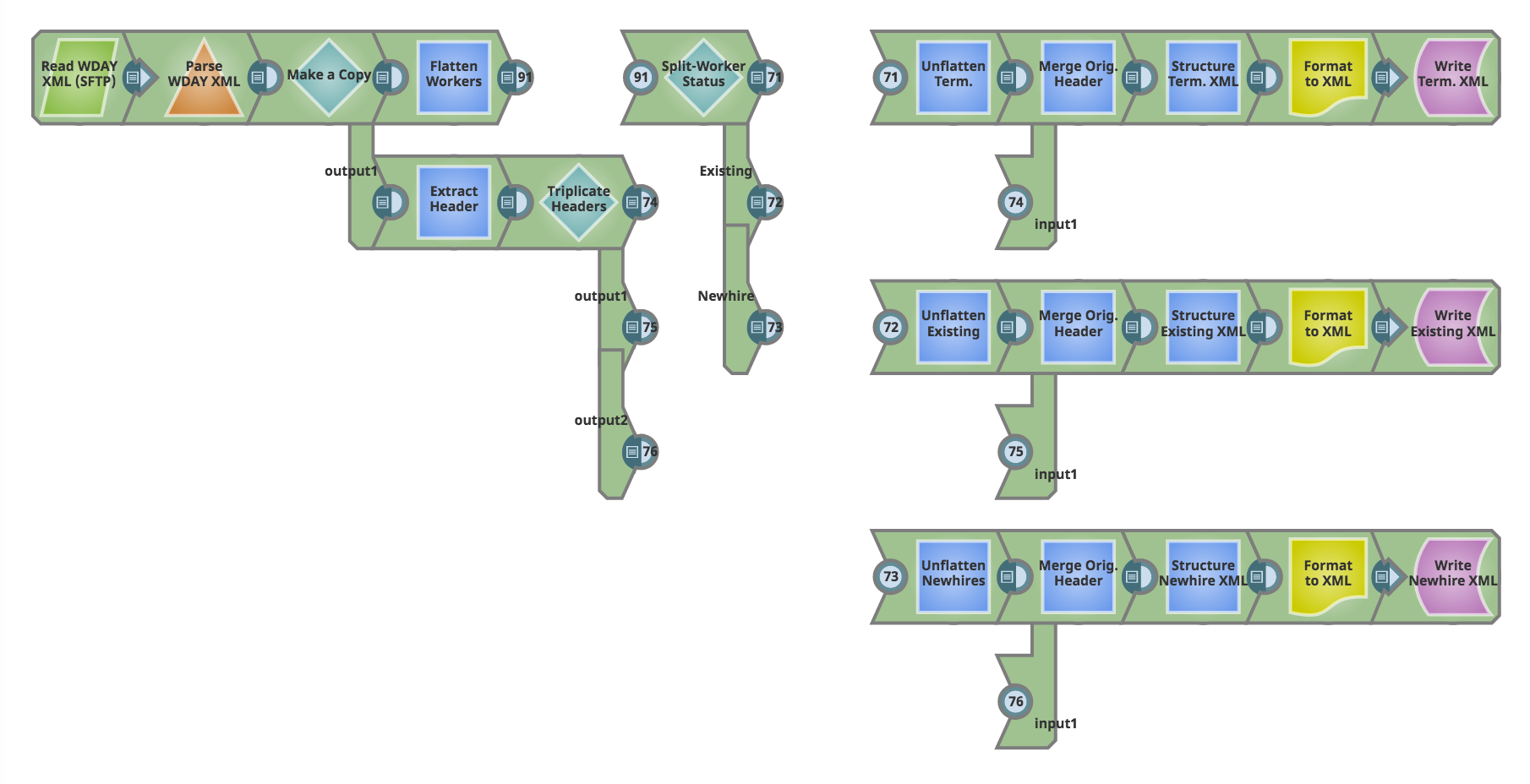
Nachfolgend finden Sie einen Screenshot der Pipeline und eine ausführliche Beschreibung, was sie zu erreichen versucht.
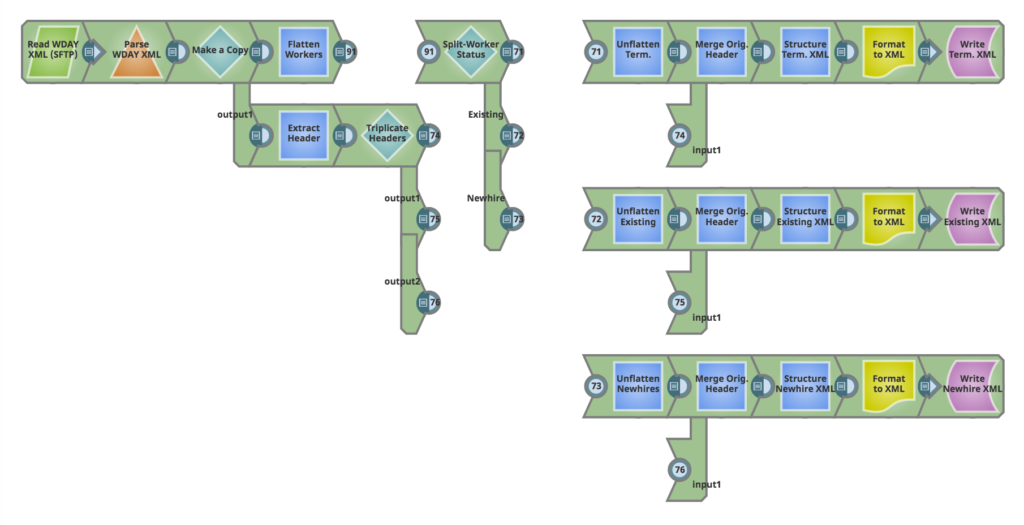
Lassen Sie uns diese Pipeline überprüfen.
Auf der linken Seite lesen wir zunächst einen XML-Auszug aus Workday, der Folgendes enthält,
a) Neu eingestellte Arbeitnehmer,
b) Beendete Arbeitnehmer und
c) Aktive (die weder neu eingestellt noch gekündigt wurden)
Unser Ziel in dieser Pipeline ist es, diese drei Arten von Arbeitnehmern zu trennen und sie in ihre eigenen XML-Dateien zu schreiben. Diese Ziel-XMLs stellen Feeds für ein oder mehrere Systeme dar, die das On-/Off-Boarding von Mitarbeitern verarbeiten.
Der Workday-Mitarbeiterextrakt liefert auch einige aggregierte Daten im XML-Header. Diese Header-Informationen sind auch in unserem Quellextrakt vorhanden. Unser Ziel ist es, auch diese Kopfzeile beizubehalten und sie in jede der Ziel-XML-Dateien einzufügen, und zwar mit einer Aktualisierung eines bestimmten Kopfzeilenfeldes (Anzahl der Mitarbeiter), das die Gesamtzahl der Mitarbeiter widerspiegelt, die in jede Ziel-XML-Datei geschrieben werden.
Pipeline-Durchgang
Sobald wir die XML-Quelldatei des Workers einlesen und die Datei teilen, erstellen wir eine Kopie. Auf dem oberen Pfad verarbeiten wir die XML-Nutzdaten. Entlang des unteren Pfades der Kopie extrahieren und bewahren wir den Header für eine spätere Verwendung. Sehen wir uns jeden dieser Pfade einzeln an.
A. Verarbeitung von XML-Nutzdaten
Zunächst entfernen wir die Hierarchie in den Worker-Daten mit Hilfe eines JSON-Splitters (Flatten Workers). Der Kern der Worker-Verarbeitung findet in der Phase "Split-Worker Status" statt, die mit einem Router-Snap mit aktiviertem "First Match" implementiert wird. Wir trennen die drei Arten von Arbeitern mit Hilfe der folgenden Logik:
a) Fügen Sie das Präfix ws: wieder hinzu:
Dies geschieht über den Snap "Gruppieren nach N" mit einem $ws-Zielfeld.
b) Wiedereinführung der XML-Kopfzeile
Wir fügen die erhaltene XML-Kopfzeile in die Ausgabe von Schritt a) oben ein. Weitere Einzelheiten zur Einführung des Headers werden weiter unten behandelt.
B. XML-Header-Verarbeitung
Der Name des Stammelements (Worker_Sync) bleibt durch die Zuordnung erhalten:

Wir fügen die verarbeitete Nutzlast (die Worker getrennt nach Typ) unter Worker_Sync durch das Mapping hinzu: 
Schließlich aktualisieren wir das Feld für die Anzahl der Arbeiter ($['ws:Worker_Sync']['ws:Header']['ws:Worker_Count']) innerhalb des neu eingeführten Headers durch:

Sobald dies geschehen ist, kann unser XML formatiert und in die Zieldatei geschrieben (oder an einen anderen Endpunkt weitergeleitet) werden. Bitte beachten Sie, dass Sie das Root-Element im XML-Formatierer leer lassen müssen, damit die Standard-Tags nicht eingeführt werden.
Hari Shankar ist ein SnapLogic Solutions Engineer Advisor.