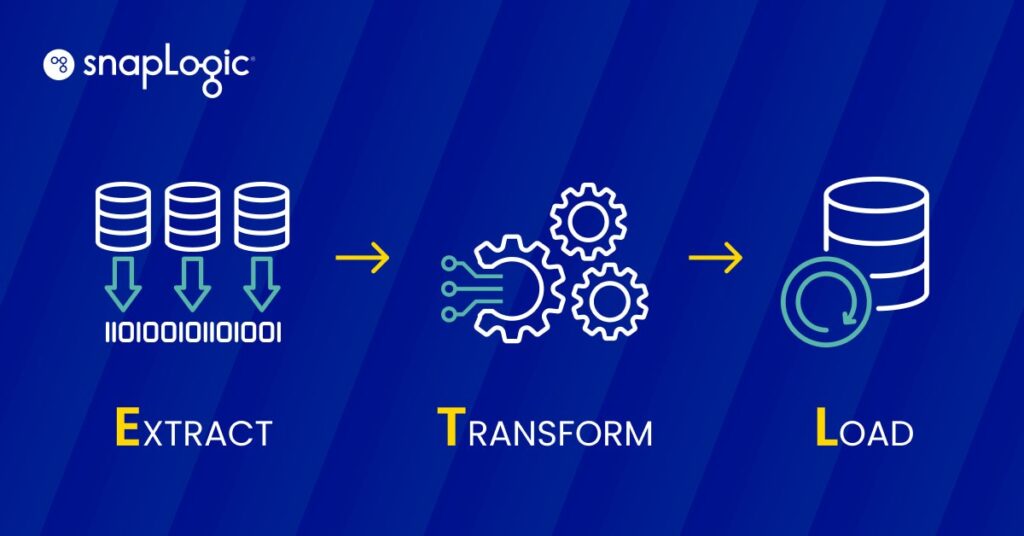
Was ist ETL?
ETL (Extrahieren, Transformieren, Laden) ist ein Datenintegrationsprozess, der drei wichtige Schritte umfasst: Extrahieren von Daten aus unterschiedlichen Quellen, Transformieren der Daten, um sie an die betrieblichen Anforderungen anzupassen, und Laden der Daten in ein Zielsystem für Analyse und Berichterstattung. Dieser Prozess ist die Grundlage für das Data Warehousing und ermöglicht eine effektive Datenkonsolidierung, -verwaltung und -nutzung für Business Intelligence.
Wie funktioniert ETL?
ETL arbeitet mit einem dreistufigen Prozess, der darauf ausgelegt ist, die Datenextraktion, -umwandlung und das Laden in ein zentrales Repository effektiv zu verwalten.
- Extraktion: In diesem ersten Schritt werden Daten aus verschiedenen Quellen wie Datenbanken, Tabellenkalkulationen oder anderen Formaten extrahiert. Das Ziel besteht darin, die erforderlichen Daten in ihrem ursprünglichen Format zu sammeln, unabhängig von der Struktur oder dem Typ der Quelle.
- Umwandlung: Sobald die Daten extrahiert sind, durchlaufen sie eine Transformationsphase, in der sie bereinigt und konvertiert werden, damit sie den Anforderungen des Zielsystems entsprechen. Dieser Schritt kann das Filtern, Sortieren, Validieren und Aggregieren von Daten beinhalten, um sicherzustellen, dass sie den Qualitäts- und Formatstandards für analytische Zwecke entsprechen.
- Laden: Der letzte Schritt ist das Laden der umgewandelten Daten in ein Zielsystem, z. B. ein Data Warehouse oder eine Datenbank. Diese Phase ist von entscheidender Bedeutung, da sie die Daten für Geschäftsanalysen und Entscheidungsprozesse zugänglich macht.
Jede Phase ist entscheidend, um sicherzustellen, dass die Daten nutzbar, sicher und effizient gespeichert sind, was ETL zu einem wesentlichen Prozess für Data Warehousing- und Business Intelligence-Initiativen macht.
Was ist eine ETL-Pipeline?
Eine ETL-Pipeline formalisiert den bereits in diesem Artikel beschriebenen Prozess der Datenbewegung und -umwandlung. Es handelt sich um eine Abfolge von Vorgängen, die in einem ETL-Tool implementiert werden, um sicherzustellen, dass die Daten aus den Quellsystemen extrahiert, korrekt transformiert und zur Analyse in ein Data Warehouse oder andere Systeme geladen werden.
Strukturierter Arbeitsablauf: Die ETL-Pipeline fasst die drei Hauptphasen von ETL - Extraktion, Transformation und Laden - in einem strukturierten Workflow zusammen. Dieser strukturierte Ansatz hilft bei der Verwaltung des Datenflusses und gewährleistet, dass jede Phase abgeschlossen ist, bevor die nächste beginnt.
Automatisierung: ETL-Pipelines automatisieren die sich wiederholenden und routinemäßigen Aufgaben der Datenverarbeitung. Diese Automatisierung unterstützt die kontinuierliche Aufnahme von Daten, ihre Umwandlung gemäß den Geschäftsregeln und -anforderungen und das anschließende Laden der verarbeiteten Daten in analytische oder operative Systeme für Business Intelligence, Berichterstattung und Entscheidungsfindung.
Integration und Planung: In einer ETL-Pipeline werden Aufgaben in der Regel von einem Orchestrierungs-Tool geplant und verwaltet, das die Ausführung verschiedener Aufgaben auf der Grundlage der Datenverfügbarkeit, der Abhängigkeiten und des erfolgreichen Abschlusses vorangegangener Aufgaben koordiniert. Diese Planung ist von entscheidender Bedeutung für die Aufrechterhaltung der Aktualität und Relevanz der Daten, insbesondere in dynamischen Geschäftsumgebungen, in denen sich die Datenanforderungen ständig weiterentwickeln.
Überwachung und Wartung: Zu einer effektiven ETL-Pipeline gehören auch Überwachungsfunktionen, um den Datenfluss zu verfolgen, Fehler zu verwalten und die Datenqualität sicherzustellen. Die Wartung umfasst die Aktualisierung der Transformationen und Prozesse als Reaktion auf Änderungen in den Quellsystemen oder Geschäftsanforderungen.
Was ist der Unterschied zwischen ETL und ELT?
Der Unterschied zwischen ETL (Extract, Transform, Load) und ELT (Extract, Load, Transform) liegt in erster Linie in der Reihenfolge und dem Ort der Datenumwandlung, was sich auf die Datenverarbeitungsabläufe auswirkt, insbesondere bei der Verarbeitung großer Datenmengen aus verschiedenen Quellen.
ETL-Prozess: Beim herkömmlichen ETL-Prozess werden die Daten zunächst aus den Quellsystemen extrahiert, zu denen relationale Datenbanken, Flat Files, APIs und andere gehören können. Diese extrahierten Daten werden dann in einem Staging-Bereich transformiert, wo Datenbereinigung, Deduplizierung und andere Transformationsprozesse stattfinden, um die Datenqualität und -konsistenz sicherzustellen. Der Transformationsprozess kann komplexe SQL-Abfragen, den Umgang mit verschiedenen Datentypen und Data-Engineering-Aufgaben wie Schema-Mapping und Metadatenmanagement umfassen. Erst nach diesen Umwandlungen werden die Daten in die Zieldatenbank oder das Data Warehouse (z. B. Snowflake oder Microsoft SQL Server) geladen und für Datenanalysen, Business Intelligence und Visualisierung verwendet.
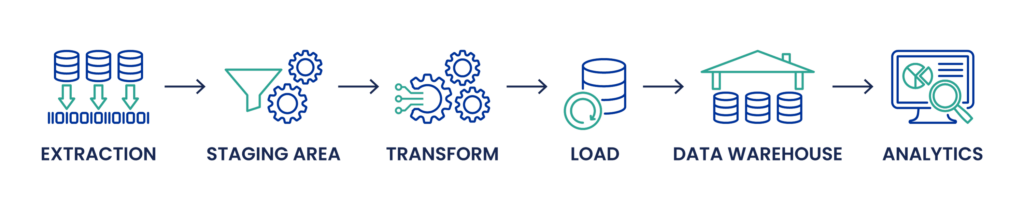
ELT-Prozess: ELT hingegen kehrt die letzten beiden Schritte von ETL um. Die Daten werden zunächst extrahiert und in einen Data Lake oder einen modernen Datenspeicher wie Google BigQuery oder Amazon Redshift geladen, oft in ihrer Rohform. Dieser Ansatz ist besonders vorteilhaft, wenn es um große Datenmengen geht, einschließlich unstrukturierter Daten aus IoT-Geräten, NoSQL-Datenbanken oder JSON- und XML-Dateien. Die Umwandlung erfolgt nach dem Laden, wobei die leistungsstarken Datenverarbeitungssysteme dieser Plattformen genutzt werden. Diese Methode ermöglicht mehr Flexibilität bei der Verwaltung von Datenschemata und kann Datenverarbeitungsanforderungen in Echtzeit bewältigen, was flexiblere Anpassungen der Datenpipeline ermöglicht und Anwendungen für maschinelles Lernen und künstliche Intelligenz erleichtert.
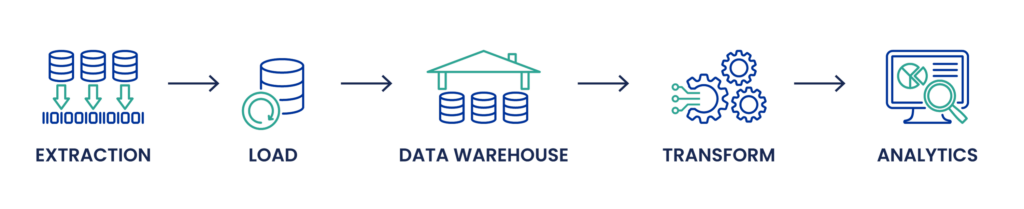
Hauptunterschiede:
- Datenmenge und -vielfalt: ELT eignet sich im Allgemeinen besser für Big-Data-Szenarien, in denen große Datenmengen aus verschiedenen Quellen aufgenommen werden. Es verwaltet unstrukturierte Daten effizient und automatisiert die Datenumwandlung innerhalb des Datenspeichersystems.
- Leistung und Skalierbarkeit: ELT kann eine bessere Leistung für große Datenmengen bieten und ist aufgrund der leistungsstarken Verarbeitungsfunktionen moderner Cloud-basierter Datenspeicher hoch skalierbar.
- Flexibilität: ELT bietet mehr Flexibilität bei der Abfrage und Verwaltung von Daten, da Transformationen je nach Bedarf im Data Lake oder Warehouse angewendet werden.
Zusammenfassend lässt sich sagen, dass die Entscheidung zwischen ETL und ELT von den spezifischen Datenverwaltungsanforderungen, der Art der Datenquellen, den beabsichtigten Anwendungsfällen für die Daten und der vorhandenen Dateninfrastruktur abhängt. ELT wird immer beliebter in Umgebungen, in denen Flexibilität, Skalierbarkeit und Datenverarbeitung in Echtzeit im Vordergrund stehen, während ETL für Szenarien relevant bleibt, die eine intensive Datenbereinigung und -umwandlung erfordern, bevor die Daten gespeichert oder analysiert werden können.
Kostenloses eBook: ETL vs. ELT: Was ist das Richtige für Ihr Unternehmen?
Was ist traditionelle ETL im Vergleich zu Cloud-ETL?
Herkömmliches ETL und Cloud-ETL sind zwei Methoden zur Handhabung von Datenextraktions-, -umwandlungs- und -ladeprozessen, die jeweils für unterschiedliche technologische Umgebungen und Geschäftsanforderungen geeignet sind.
Traditionelle ETL: Traditionelle ETL-Prozesse sind für den Betrieb in einer lokalen Infrastruktur ausgelegt. Dazu gehören physische Server und Speicher, die sich im Besitz eines Unternehmens befinden und von diesem gewartet werden. Die ETL-Tools in dieser Umgebung sind in der Regel Teil eines geschlossenen, sicheren Netzwerks. Zu den wichtigsten Merkmalen gehören:
- Kontrolle und Sicherheit: Da sich die Infrastruktur vor Ort befindet, haben Unternehmen die vollständige Kontrolle über ihre Systeme und Daten, was für Branchen mit strengen Anforderungen an die Datensicherheit und die Einhaltung von Vorschriften entscheidend sein kann.
- Vorab-Investitionen: Traditionelles ETL erfordert erhebliche Vorabinvestitionen in Hardware und Infrastruktur.
- Wartung: Erfordert laufende Wartung von Hardware und Software, einschließlich Upgrades und Fehlerbehebung, was ressourcenintensiv sein kann.
- Herausforderungen bei der Skalierbarkeit: Die Skalierung erfordert zusätzliche physische Hardware, was langsam und kostspielig sein kann.
Cloud-ETL: Cloud-ETL hingegen nutzt Cloud-Computing-Umgebungen, in denen die Ressourcen virtuell skalierbar sind und von Drittanbietern verwaltet werden. Dieser Ansatz hat aufgrund seiner Flexibilität, Skalierbarkeit und Kosteneffizienz an Beliebtheit gewonnen. Zu den Merkmalen gehören:
- Skalierbarkeit und Flexibilität: Cloud-ETL kann die Ressourcen je nach Verarbeitungsbedarf leicht nach oben oder unten skalieren, oft sogar automatisch. Diese Flexibilität ist wertvoll für die Bewältigung variabler Arbeitslasten und die Verarbeitung großer Datenmengen.
- Geringerer Kapitalaufwand: Mit Cloud-ETL vermeiden Unternehmen die hohen Vorlaufkosten, die mit herkömmlicher ETL verbunden sind, und zahlen stattdessen für das, was sie nutzen, oft auf Abonnementbasis.
- Bessere Zusammenarbeit und Zugänglichkeit: Cloud-Lösungen bieten eine bessere Zugänglichkeit für verteilte Teams und ermöglichen die Zusammenarbeit über verschiedene geografische Standorte hinweg.
- Integration mit modernen Datendiensten: Cloud-ETL-Tools sind so konzipiert, dass sie sich nahtlos in andere Cloud-Dienste integrieren lassen, einschließlich fortschrittlicher Analysen, maschineller Lernmodelle und mehr, und so eine umfassende Datenverarbeitungspipeline bieten.
Die Entscheidung zwischen traditionellem und Cloud-ETL hängt von mehreren Faktoren ab, darunter die Datenstrategie des Unternehmens, die Sicherheitsanforderungen, Budgetbeschränkungen und spezifische Anwendungsfälle. Cloud-ETL bietet einen modernen Ansatz, der mit Initiativen zur digitalen Transformation übereinstimmt und dynamischere, datengesteuerte Entscheidungsumgebungen unterstützt. Traditionelle ETL ist zwar manchmal durch ihre physische Beschaffenheit eingeschränkt, bleibt aber eine solide Wahl für Unternehmen, die eine strenge Kontrolle über ihre Dateninfrastruktur und -abläufe benötigen.