La semaine dernière, une partie de l‘équipe SnapLogic était à New York pour la conférence Strata/Hadoop World. Il s‘agit de l‘un des plus grands événements sur les big data aux États-Unis, qui n‘a cessé de prendre de l‘ampleur au cours des dernières années. L‘ordre du jour a également évolué, passant de discussions essentiellement académiques et de présentations pratiques par des committers open source à des études de cas réels par des entreprises non-ISV.
C‘est dans cet esprit que j‘aimerais vous raconter l‘histoire de l‘une de nos entreprises clientes. En fait, il s‘agit d‘une institution financière vieille de plus de 100 ans. Ce n‘est peut-être pas une entreprise que vous associeriez à la pointe des technologies de gestion des données... En raison de la nature de son secteur d‘activité, je ne peux pas vous communiquer son nom.
Comme beaucoup d‘entreprises bien établies, les systèmes de traitement et de stockage des données de cette banque ont été acquis ou ajoutés au fil des ans en fonction des besoins les plus pressants et des exigences de conformité du moment. En fin de compte, la banque s‘est retrouvée à essayer de gérer un mélange difficile de plus de 240 interfaces et applications.
Comme vous pouvez l‘imaginer, les données se présentaient sous une grande variété de formats, tels que des fichiers Excel, des fichiers texte délimités (csv), des copybooks de longueur fixe ou variable et des fichiers zippés. Les sources de données étaient également très variées : ftb/sftp, QlikView business intelligence, bases de données SQL Server, Oracle et Sybase. La gestion de cet environnement était non seulement difficile, mais elle prenait aussi beaucoup de temps, ce qui pesait lourdement sur les ressources du personnel informatique et grevait les budgets.
La conservation des données pendant une période donnée étant une exigence réglementaire dans le secteur bancaire, la recherche d‘une solution de stockage rentable et efficace était le cas d‘utilisation le plus urgent, mais l‘entreprise souhaitait également utiliser plus efficacement les données de ses clients.
Cherchant à moderniser son approche de la gestion et du stockage des données et, en fin de compte, à offrir un service à la clientèle plus rationalisé et amélioré, l‘entreprise a décidé d‘éliminer un certain nombre de ses anciennes bases de données et applications mainframe, de moderniser son approche de la conservation des données et d‘accélérer l‘analyse des activités grâce à Hadoop et à un lac de données.
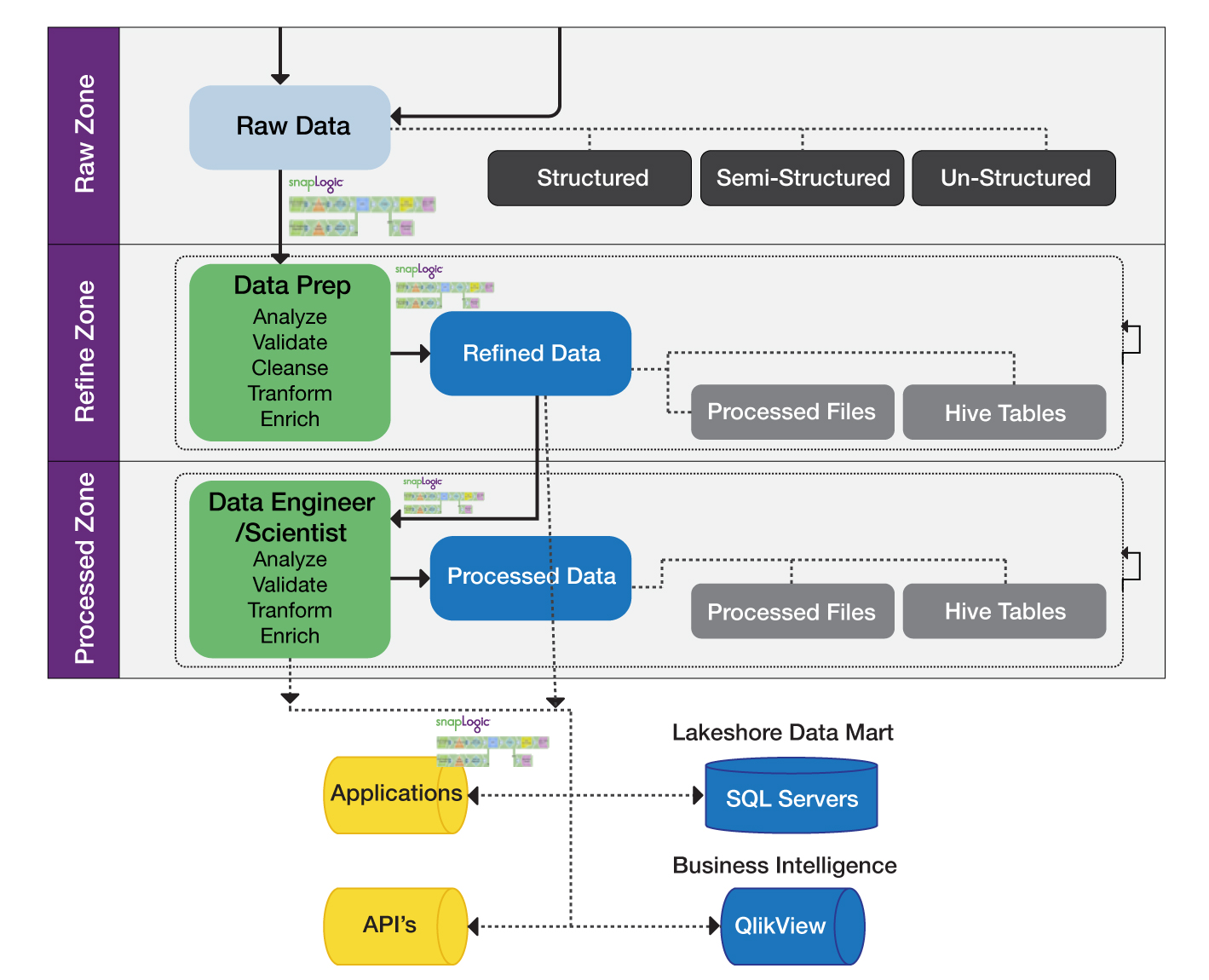
Après avoir réfléchi à la manière de procéder en interne et exploré les options disponibles sur le marché, notamment les outils open source, ils ont décidé d‘utiliser la plate-forme d‘intégration élastique SnapLogic en conjonction avec un environnement Hadoop basé sur Cloudera. SnapLogic leur a permis d‘effectuer l‘ingestion, la préparation et la livraison des données dans un seul Data Hub, favorisant ainsi le retrait des anciennes bases de données et des applications mainframe et consolidant les données provenant de sources multiples au sein d‘un lac de données. Dans la prochaine phase du projet, SnapLogic permettra également de concrétiser leur vision d‘un " lac de données en libre-service " pour les besoins futurs en matière de reporting.
Après avoir utilisé SnapLogic pour consolider les sources de données internes et mettre hors service un grand nombre de leurs bases de données et applications mainframe existantes prenant en charge les données commerciales internes, ils ont ajouté au Data Hub des données externes provenant de fournisseurs de données financières tiers. Une fois leur vision achevée, ils disposeront d‘un ensemble complet de données intégrées dans un Cloudera Data Hub pour une conservation efficace et rentable des données. Cela constituera également la base de leur prochain projet, qui exploitera le Data Hub pour obtenir une vue à 360 degrés du client et, par conséquent, améliorer le service à la clientèle.
Au lieu de considérer les données comme un simple problème de conservation pour la conformité réglementaire du secteur, le Data Hub ou lac de données de cette banque est considéré comme un atout stratégique. Plus qu‘un simple "stockage distribué bon marché", le lac de données basé sur Hadoop est une ressource centralisée pour l‘analyse et la compréhension des données. Grâce à ces données commerciales consolidées, ils seront en mesure de visualiser toutes les données par client et par relation, ce qui fournira des informations inestimables sur la façon d‘améliorer le service à la clientèle en général. Chez SnapLogic, nous sommes fiers d‘être un catalyseur essentiel de leur vision du lac de données.
Comme nous l‘a dit notre champion des clients, "le défi initial était de faire face aux exigences de conformité et de réglementation dans le secteur financier : "Ledéfi initial consistait à gérer la conformité et les exigences réglementaires dans le secteur financier. Lorsque nous avons réfléchi à des moyens novateurs de mieux maîtriser la situation, nous avons trouvé un moyen de faire d‘une pierre deux coups, pour ainsi dire. Que diriez-vous d‘un système d‘archivage et de conservation des données qui servirait également de centre de données pour fournir des informations ?
La solution était claire, mais la tâche était intimidante et les défis en matière de compétences étaient nombreux. Nous nous sommes donc courageusement lancés avec peu de moyens, un DBA junior pour nous aider et les conseils de Cloudera et SnapLogic qui nous ont aidés à concevoir et à mettre en œuvre notre vision".