





Comment SnapLogic simplifie le processus complexe de chargement des données Salesforce dans Amazon Redshift
Alors que je travaillais sur un projet complexe d‘intégration de données Salesforce, j‘ai commencé à construire quelque chose qui, pour moi, s‘est transformé en œuvre d‘art. Pourquoi est-ce que je pense cela ? Je m‘explique. J‘ai travaillé avec de nombreux outils d‘intégration de données et d‘applications, mais aucun ne m‘a procuré la même satisfaction artistique que la SnapLogic Intelligent Integration Platform. Il n‘y a pas de code en jeu - il s‘agit uniquement de glisser-déposer et de simples scripts. Et pourtant, la solution résout le problème très complexe du chargement des données Salesforce dans l‘entrepôt de données Amazon Redshift cloud .
D‘après mon expérience avec d‘autres outils d‘intégration, aucun n‘a pu résoudre ce problème de manière aussi simple, élégante et artistique. En fait, j‘ai imprimé et encadré le pipeline d‘intégration SnapLogic que j‘ai construit pour ce cas d‘utilisation et je l‘ai accroché au mur de ma salle d‘étude.
Avant d‘entrer dans les détails de la construction du pipeline, permettez-moi de définir le problème.
Le défi : Transférer les données Salesforce dans Redshift
Il y a quelque temps, j‘ai aidé Box, une société leader dans la gestion de contenu cloud et un client de SnapLogic, avec un projet d‘intégration important. L‘équipe de Box a émis les exigences suivantes.
"Nous souhaitons extraire les données Salesforce dans un entrepôt de données, en l‘occurrence Amazon Redshift. Mais les objets de données Salesforce sont fréquemment mis à jour et de nouveaux champs sont régulièrement ajoutés. Par conséquent, les schémas de table ‘Load‘ de Redshift doivent être modifiés et les nouveaux champs extraits de Salesforce. En outre, dans Redshift, nous avons défini de nombreuses vues de base de données qui dépendent des schémas de table "Load". Toutes les vues devront être mises à jour.
Actuellement, il s‘agit d‘un processus manuel qui consiste à modifier les schémas des tables Redshift pour les faire correspondre aux entités Salesforce, à mettre à jour le script SOQL Salesforce pour récupérer les nouveaux champs de données Salesforce, à charger les données dans les tables Redshift et, enfin, à mettre à jour les schémas de vue Redshift dépendants. Si l‘on multiplie ces opérations par le nombre d‘entités Salesforce, la tâche devient très fastidieuse.
Et maintenant, l‘art !
Pipeline SnapLogic : Intégration Low-code des données Salesforce
Le premier pipeline compare les champs d‘entité Salesforce avec le schéma de la table ‘Load‘ de Redshift associée pour déterminer les différences, effectue une mise à jour de la table ‘Load‘ de Redshift, et enfin construit l‘instruction SOQL de Salesforce.
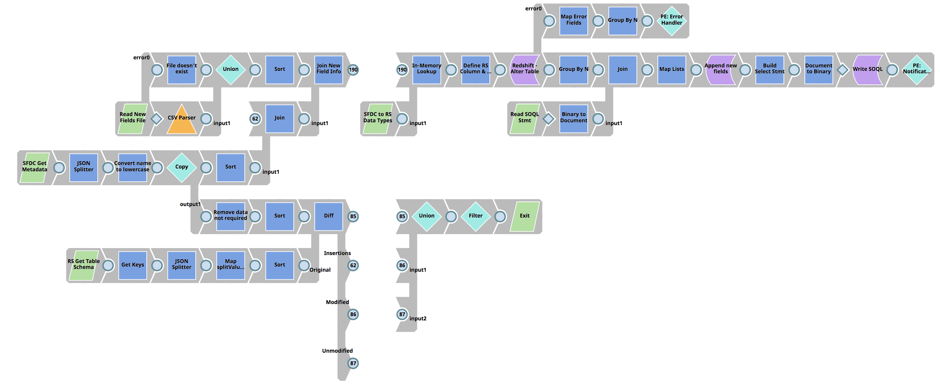
Des étapes plus détaillées :
- Utilise l‘API Salesforce Metadata pour renvoyer tous les champs d‘une entité Salesforce.
- Récupérer le schéma de la table de chargement Redshift de l‘entité Salesforce associée.
- Utiliser la fonction Diff Snap pour déterminer les différences entre les champs d‘entités de Salesforce et les colonnes de la table de chargement de Redshift.
- Avec le résultat du Diff Snap (les différences entre Salesforce Entity et Redshift Load Table), joindre les métadonnées de Salesforce pour obtenir toutes les informations sur les champs d‘entité de Salesforce.
- Utilisez l‘instantané en mémoire et effectuez une recherche pour faire correspondre le type de champ Salesforce avec le type de données Redshift.
- Ajouter la (les) nouvelle(s) colonne(s) au schéma de la table de chargement de Redshift, à l‘aide de la commande d‘exécution de Redshift.
- Chargez la version précédente du fichier de déclaration SOQL de Salesforce et joignez-la à la liste des nouveaux champs de données Salesforce.
- Mise à jour du fichier d‘instructions SOQL pour inclure de nouveaux champs et écrire dans la base de données SLDB
Ensuite, extrayez les données de Salesforce à l‘aide de l‘instruction SOQL et chargez-les en vrac dans Redshift :
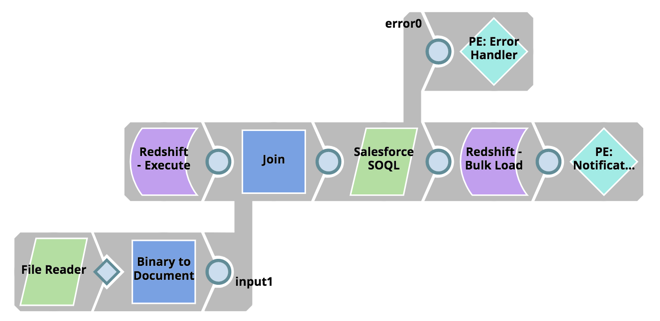
- Lire la mise à jour du script de l‘instruction SOQL de la SLDB
- Récupérer la date de dernière modification de la table de chargement Redshift
- Utiliser l‘API SOQL de Salesforce, à l‘aide de Salesforce SOQL Snap, et récupérer tous les enregistrements à partir de la date de dernière modification.
- À l‘aide de l‘outil Redshift Bulk Load Snap, chargez les données en vrac dans Redshift.
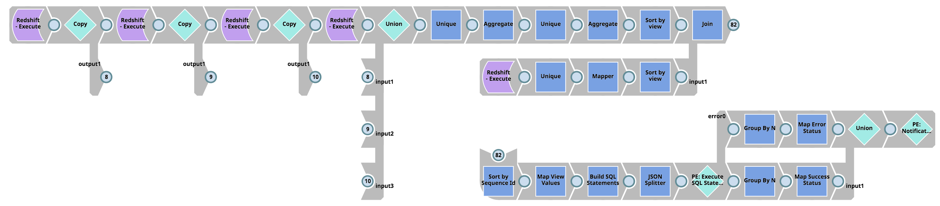
Enfin, il faut déterminer les dépendances des vues de la table ‘Load‘ de Redshift, récupérer les schémas de vues de Redshift (c‘est-à-dire la table pg_views), construire les scripts SQL pour déposer, créer et accorder des permissions pour les vues, et exécuter les instructions SQL sur Redshift :
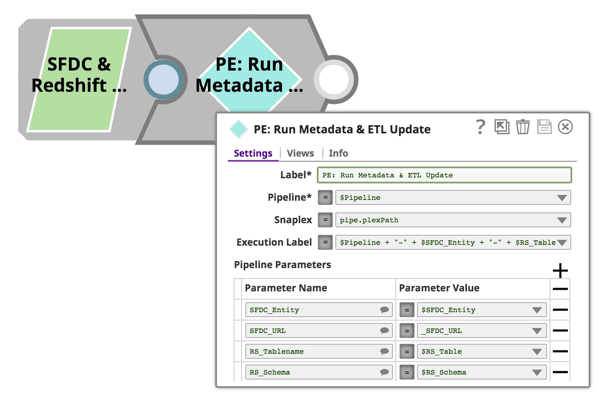
Tous les pipelines décrits ci-dessus acceptent les paramètres de pipeline, de sorte que nous pouvons utiliser une approche orientée objet et réutiliser ces pipelines pour toutes les entités Salesforce et les tables Redshift. Pour ce faire, il suffit d‘utiliser le Pipeline Execute Snap et de passer les noms des entités Salesforce, les noms des tables Redshift, les noms des pipelines, etc. Encore une fois, cela se fait via la configuration de l‘instantané d‘exécution de pipeline :
À mes yeux, l‘art ici est que toutes ces fonctionnalités sont réalisées rapidement et sans aucun codage. Les pipelines sont visuellement attrayants et d‘une grande beauté technique si l‘on considère la logique sous-jacente et les tâches lourdes effectuées par le moteur d‘exécution SnapLogic.
Vous souhaitez utiliser les plus de 500 connecteurs préconstruits (Snaps) de SnapLogic pour intégrer toutes vos données et applications disparates ? Commencez un essai gratuit dès aujourd‘hui.






