Selon Gartner, la mauvaise qualité des données coûte en moyenne 12,9 millions de dollars par an aux entreprises. C‘est une somme stupéfiante, mais qui n‘est pas surprenante si l‘on considère que des données de mauvaise qualité conduisent à des analyses inexactes et à de mauvaises décisions.
Les pipelines de données ETL permettent d‘améliorer la qualité des données. Ils aident les organisations dans divers cas d‘utilisation, tels que la migration vers cloud , la réplication de bases de données et l‘entreposage de données.
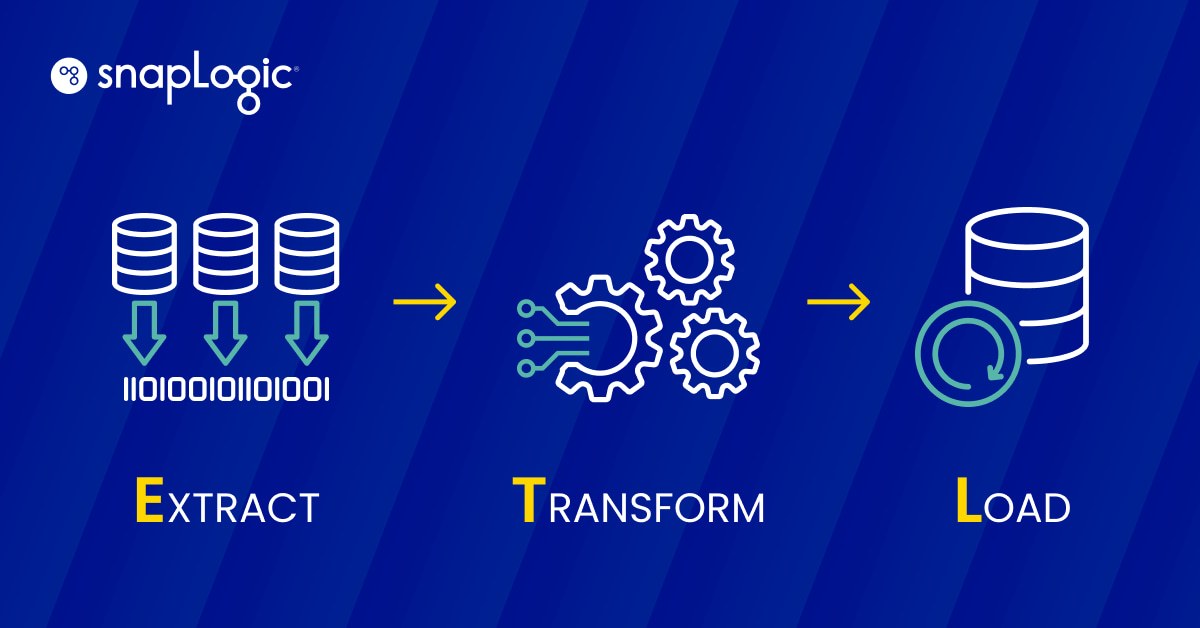
Qu‘est-ce qu‘un pipeline de données ETL ?
Un pipeline de données ETL est un processus en trois étapes qui consiste à extraire(E) des données, à les transformer(T) et à les charger(L) dans un magasin de données afin qu‘elles soient utilisées par un outil de veille stratégique ou un algorithme d‘apprentissage automatique.
- Extraction: Les données structurées et non structurées provenant d‘une ou de plusieurs sources sont copiées ou déplacées vers une zone de transit.
- Transformation: Les données de la zone de transit sont traitées en vue de leur utilisation prévue. Ce traitement des données peut inclure le nettoyage, le filtrage, la déduplication, la conversion, le cryptage et bien d‘autres processus, en fonction du cas d‘utilisation.
- Chargement: Les données transformées sont chargées dans un entrepôt.
Les cas d‘utilisation de l‘ETL vont du plus simple au plus complexe.
Par exemple, un magasin possédant plusieurs sites peut mettre en place un pipeline de données ETL pour collecter les informations sur les ventes de tous ses sites et les envoyer chaque jour à un référentiel central. Cet exemple est relativement simple comparé à celui de Netflix.
Netflix s‘appuie sur le processus ETL pour soutenir son infrastructure de données en temps réel. L‘ETL aide Netflix à traiter les données qui sont ensuite utilisées pour fournir des recommandations hautement personnalisées à ses abonnés. Jusqu‘en 2015, l‘entreprise s‘appuyait sur le traitement par lots pour gérer ses données. Les données générées par les processus internes, ainsi que les données des utilisateurs, passaient par des pipelines ETL conventionnels et aboutissaient dans des référentiels de données.
Mais Netflix connaissait une croissance rapide et le traitement par lots n‘était tout simplement pas une solution durable. L‘entreprise générait plus de 10 Po de données par jour et s‘attendait à en générer encore plus. Netflix a construit Keystone, un site de données plateforme pour traiter les flux de données en temps réel à des fins d‘analyse, et Mantis, un site similaire plateforme pour traiter les cas d‘utilisation opérationnelle.
Le passage du traitement par lots au traitement en flux a été itératif - il a fallu cinq ans à Netflix pour passer complètement à un modèle de traitement en flux. En plus de fournir des recommandations personnalisées, ses pipelines ETL aident également l‘entreprise à améliorer son efficacité opérationnelle.
ETL vs. autres pipelines de données : quelles sont les différences ?
Un pipeline de données ETL est un type de pipeline de données, mais tous les pipelines de données ne sont pas ETL. Un pipeline de données est un processus dans lequel un logiciel prend des données d‘une source et les envoie à une destination. Outre l‘ETL, il existe d‘autres types de pipelines de données :
ELT
Un pipeline ELT ressemble à l‘ETL, mais les données sont chargées dans un magasin de données avant le processus de transformation. Les pipelines ELT sont utilisés pour traiter de grands volumes de données non structurées pour les cas d‘utilisation de l‘apprentissage automatique.
Saisie des données de changement (CDC)
Le CDC est un type de pipeline de données dans lequel un logiciel suit toutes les modifications apportées aux données d‘une base de données et transmet ces modifications à un autre système en temps réel. Le CDC est utilisé pour la synchronisation des données et la création de journaux d‘audit.
Réplication des données
La réplication des données est le processus qui consiste à copier en continu les données d‘une source et à les enregistrer dans plusieurs autres sources afin de les utiliser comme sauvegarde. La réplication des données est également utilisée pour transférer des données de production vers des entrepôts de données opérationnels à des fins d‘analyse.
Virtualisation des données
La virtualisation des données est le processus d‘intégration de toutes les sources de données au sein d‘une organisation afin que les utilisateurs puissent accéder à ces données par le biais d‘un tableau de bord. La virtualisation des données est utilisée pour créer des tableaux de bord et des rapports pour la conformité réglementaire, la gestion de la chaîne d‘approvisionnement et la veille stratégique.
Quels sont les avantages d‘un pipeline de données ETL ?
Les pipelines de données ETL vous permettent de contrôler entièrement la gestion des données dans votre organisation. Vous pouvez :
- Accédez à des données propres et précises pour l‘analyse et débarrassez-vous des enregistrements inexacts, dupliqués et incomplets au moment de la transformation des données.
- Suivre facilement le cheminement des données, ce qui facilite la mise en œuvre d‘un cadre de gouvernance des données et le suivi du flux de données dans les différents pipelines au sein de l‘organisation.
- Améliorer l‘efficacité du traitement des données au sein de l‘organisation grâce à l‘automatisation.
- Visualisez les architectures de données qui utilisent des pipelines de données ETL. En créant de tels diagrammes, vous pouvez comprendre le flux de données et planifier des ajustements au pipeline si nécessaire.
Les pipelines de données ETL sont faciles à mettre en place, en particulier grâce aux outils d‘intégration de données. Ces outils sont principalement disponibles via des plates-formes "low-code" et "no-code" où vous pouvez utiliser une interface utilisateur graphique (GUI) pour construire des pipelines de données ETL et automatiser le flux de données au sein de votre organisation.
Types de pipelines de données ETL
Les pipelines de données ETL sont de trois types. Cette classification est basée sur la manière dont les outils d‘extraction de données extraient les données de la source.
Traitement par lots
Dans ce type de pipeline de données ETL, les données sont extraites par lots. Le développeur définit une synchronisation périodique entre les sources de données et l‘environnement de mise en scène, et les données sont extraites à la date prévue. Cela signifie que la charge du serveur n‘augmente qu‘au moment de la synchronisation. Voici quelques-uns des cas d‘utilisation du traitement par lots :
- Petites et moyennes organisations: Les petites et moyennes entreprises travaillent avec des ressources limitées et ne traitent pas de gros volumes de données. Le traitement par lots leur permet de gérer efficacement la charge du serveur au moment de la synchronisation et de gérer leurs données en fonction de leurs ressources.
- Données dispersées dans plusieurs bases de données de l‘organisation: S‘il y a de nombreuses bases de données dans l‘organisation et que les données sont réparties sur plusieurs sites sur des serveurs sur site, il est préférable de créer plusieurs pipelines de données ETL par lots qui se synchronisent avec le référentiel de données central à différents moments de la journée.
- Les données n‘arrivent pas sous forme de flux: Si vous ne générez pas de données sous forme de flux, il est préférable d‘utiliser des pipelines de données ETL par lots, car ils consomment moins de ressources.
- Les analystes ont des besoins limités: Si vos analystes de données n‘ont pas besoin de données fraîches ou d‘accéder à l‘ensemble des données lorsqu‘ils effectuent différentes analyses, le traitement par lots vous conviendra parfaitement.
Intégration des données de flux (SDI)
Dans SDI, l‘outil d‘extraction de données extrait continuellement les données de leurs sources et les envoie dans un environnement de stockage. Ce pipeline de données ETL est utile dans les cas suivants
- Les grands ensembles de données doivent être traités: Les organisations qui travaillent avec de gros volumes de données qui doivent être continuellement extraites, transformées et chargées peuvent bénéficier du traitement en flux.
- Les données sont générées sous forme de flux: Toute organisation dont les données sont générées en continu sous forme de flux peut bénéficier d‘une IDS. Par exemple, sur YouTube, des millions d‘utilisateurs regardent des vidéos et génèrent des données simultanément. La SDI peut aider à acheminer ces données vers les magasins de données en temps réel.
- L‘accès aux données en temps réel est essentiel: Les systèmes de détection des fraudes arrêtent les mauvais acteurs et ne les laissent pas effectuer des transactions en temps réel. C‘est parce qu‘ils surveillent les données en temps réel. L‘IDS est très utile dans de tels cas d‘utilisation.
Comment créer un pipeline de données ETL traditionnel avec Python ?
Lors de la création d‘un pipeline de données ETL traditionnel avec Python, l‘extrait de code ressemblerait à ceci (Python pur utilisant Pandas ; il ne s‘agit pas d‘un exemple prêt pour la production).
| import os from sqlalchemy import create_engine import pandas as pd # Extract data data = pd.read_csv(‘data.csv’) # Transform data data = data.dropna() # remove missing values data = data.rename(columns={‘old_name’: ‘new_name’}) # rename columns data = data.astype({‘column_name’: ‘int64’}) # convert data type # Load data db_url = os.environ.get(‘DB_URL’) engine = create_engine(db_url) data.to_sql(‘table_name’, engine, if_exists=’append’) |
Dans cet exemple, nous :
- Extraire des données d‘un fichier CSV.
- Transformez-le en supprimant les valeurs manquantes, en renommant les colonnes et en convertissant les types de données.
- Le charger dans une table de la base de données SQL.
Il ne s‘agit là que d‘un exemple d‘écriture manuelle de code - les étapes et les bibliothèques spécifiques que vous utiliserez dépendront de la source de données et de la cible, ainsi que des transformations spécifiques requises. Snap
Comment simplifier les pipelines de données avec SnapLogic
L‘extrait ci-dessus est un exemple très basique d‘ETL. Pour des transformations plus complexes, l‘exemple du codage manuel serait beaucoup plus complexe. En outre, le codage manuel nécessite une maintenance fastidieuse, ce qui prive les ateliers d‘ingénierie et d‘entrepôt de données d‘une productivité précieuse.
Plutôt que de coder manuellement, créez des pipelines de données à l‘aide de l‘interface utilisateur visuelle et graphique de SnapLogic. Avec SnapLogic, vous pouvez créer des pipelines de données ETL, ELT, batch ou streaming. Suivez ces étapes pour une approche SnapLogic sans code :
- Recherchez un modèle existant, parmi des centaines, dans la zone Studio Patterns de SnapLogic qui correspond à votre source de données (base de données, fichiers, données Web), à votre destination de données et à vos exigences fonctionnelles.
- Copier le modèle dans le canevas de SnapLogic Designer
- Dans SnapLogic Designer, modifiez le modèle SnapLogic pour l‘adapter à vos besoins de configuration spécifiques.
- Vous pouvez également partir d‘un canevas SnapLogic Designer vierge, sélectionner la source de données dont vous avez besoin parmi des centaines de SnapLogic prédéfinis et faire glisser le Snap sur votre canevas.
- Laissez SnapLogic Iris, un assistant d‘intégration piloté par l‘IA, vous guider dans les étapes suivantes de la construction de votre pipeline (si vous placez un point de départ, un point d‘arrivée et un point médian sur votre canevas, SnapLogic peut vous recommander un pipeline de données complet sur la base de modèles similaires).
Pour une compréhension plus approfondie des méthodes modernes, basées sur l‘IA, pour créer et exécuter des pipelines de données sans code ou avec un faible code, lisez l‘approche de SnapLogic en matière d‘ETL.