





Pour alimenter un lac de données basé sur Hadoop, de nombreuses entreprises utilisent un modèle courant qui consiste à obtenir des données à partir de bases de données relationnelles et d‘entrepôts de données préexistants. Lorsque l‘on prévoit d‘ingérer des données dans le lac de données, l‘une des principales considérations est de déterminer comment organiser un pipeline d‘ingestion de données et permettre aux consommateurs d‘accéder aux données. Hive et Impala fournissent une infrastructure de données au-dessus de Hadoop - communément appelée SQL sur Hadoop - qui fournit une structure aux données et la possibilité de les interroger à l‘aide d‘un langage de type SQL.
Avant de commencer à introduire des données dans les bases de données, les schémas et les tables de Hive, les deux aspects essentiels à prendre en compte sont les suivants :
- Quels formats de stockage de données utiliser pour stocker des données ? (HDFS prend en charge un certain nombre de formats de données pour les fichiers tels que SequenceFile, RCFile, ORCFile, AVRO, Parquet, etc.)
- Quelles sont les options de compression optimales pour les fichiers stockés sur HDFS ? (Les exemples incluent gzip, LZO, Snappy et d‘autres).
Ensuite, lors de la conception des schémas de la base de données Hive, vous êtes généralement confronté aux problèmes suivants :
- Créer le schéma de la base de données Hive de la même manière que le schéma de la base de données relationnelle. Cela permet d‘ingérer rapidement des données dans Hive avec un minimum d‘effort pour le mappage et les transformations dans le cadre de vos pipelines de flux de données d‘ingestion.
- Créer un nouveau schéma de base de données différent du schéma de la base de données relationnelle. Cela permet de redéfinir le schéma de la base de données Hive et d‘éliminer certaines des lacunes de votre schéma de base de données relationnelle actuel. Cela augmente également l‘effort de mappage et de transformation des données dans le cadre de vos pipelines de flux de données d‘ingestion.
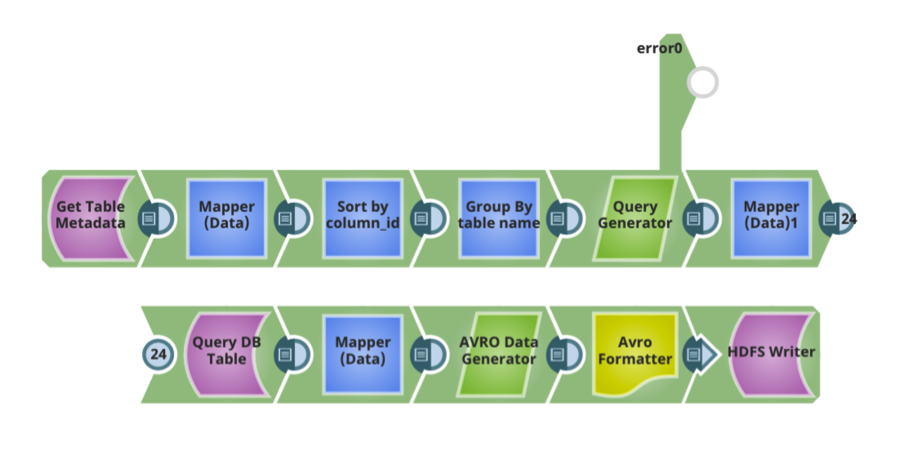 Typiquement, nous avons vu que le schéma Hive était créé de manière similaire au schéma de la base de données relationnelle. Une fois que le schéma Hive, le format des données et les options de compression sont en place, il existe d‘autres configurations de conception pour déplacer les données dans le lac de données via un pipeline d‘ingestion de données :
Typiquement, nous avons vu que le schéma Hive était créé de manière similaire au schéma de la base de données relationnelle. Une fois que le schéma Hive, le format des données et les options de compression sont en place, il existe d‘autres configurations de conception pour déplacer les données dans le lac de données via un pipeline d‘ingestion de données :
- La capacité d‘analyser les métadonnées des bases de données relationnelles telles que les tables, les colonnes d‘une table, les types de données pour chaque colonne, les clés primaires/étrangères, les index, etc. Chaque base de données relationnelle fournit un mécanisme permettant d‘interroger ces informations. Chaque base de données relationnelle fournit un mécanisme permettant d‘interroger ces informations. Ces informations permettent de concevoir des flux de données d‘ingestion efficaces.
- Les formats de données utilisés sont généralement associés à un schéma. Par exemple, si l‘on utilise le format AVRO, il faut définir un schéma AVRO. La possibilité de générer automatiquement le schéma sur la base des métadonnées de la base de données relationnelle, ou le schéma AVRO pour les tables Hive sur la base du schéma des tables de la base de données relationnelle, est un élément clé à prendre en considération.
- La possibilité de générer automatiquement des tables Hive pour les tables source basées sur des données relationnelles.
- Lors de la conception de vos flux de données d‘ingestion, tenez compte des éléments suivants :
- La possibilité d‘effectuer automatiquement tous les mappages et transformations nécessaires pour déplacer les données de la base de données relationnelle source vers les tables Hive cibles.
- Possibilité de partager automatiquement les données pour déplacer efficacement de grandes quantités de données.
- La possibilité de paralléliser l‘exécution sur plusieurs nœuds d‘exécution.
Les tâches ci-dessus sont des modèles d‘ingénierie des données, qui encapsulent les meilleures pratiques pour traiter le volume, la variété et la vitesse de ces données.
Dans mon prochain article, je décrirai une approche pratique de l‘utilisation de ces modèles avec l‘intégration de big data de SnapLogic plateforme en tant que service sans avoir besoin d‘écrire du code. En attendant, vous pouvez en savoir plus sur l‘intégration des big data ici et ne manquez pas de revenir pour d‘autres articles sur les pipelines d‘ingestion de données.
Prasad Kona est architecte d‘entreprise Big Data et fait partie de l‘équipe d‘intégration Big Data chez SnapLogic.



