





Qu‘est-ce que Apache Hive ? Hive fournit un mécanisme permettant d‘interroger, de créer et de gérer de grands ensembles de données stockés sur Hadoop, à l‘aide d‘instructions de type SQL. Il permet également d‘ajouter une structure aux données existantes qui résident sur HDFS. Dans ce billet, je décrirai une approche pratique sur la façon d‘ingérer des données dans Hive, avec la plateforme d‘intégration élastique SnapLogic, sans avoir besoin d‘écrire du code.
Les pipelines de flux de données, également appelés pipelines SnapLogic, sont créés dans un concepteur visuel très intuitif, à l‘aide d‘une approche de type glisser-déposer. Un pipeline de flux de données se compose d‘un ou plusieurs Snaps qui sont connectés pour orchestrer le flux d‘intégration des données d‘ entreprise entre les sources et les cibles. Les Snaps sont les éléments constitutifs d‘un pipeline qui exécutent une fonction unique telle que la lecture, l‘écriture ou l‘action sur les données. Les Snaps SnapLogic prennent en charge la lecture et l‘écriture à l‘aide de divers formats, notamment CSV, AVRO, Parquet, RCFile, ORCFile, texte délimité, JSON. Les schémas de compression pris en charge comprennent LZO, Snappy, gzip.
Voici donc un scénario : Supposons que nous ayons des données de contact obtenues à partir de plusieurs sources et qu‘elles doivent être intégrées dans Hive. Nous devons combiner des données provenant de sources multiples : fichiers bruts sur HDFS, données sur S3 (AWS), données provenant de bases de données et données provenant d‘applications cloud telles que Salesforce ou Workday. Comment commencer à ingérer des données provenant de ces sources disparates dans Hive ?
La première étape consiste à créer une base de données et/ou des tables Hive. En utilisant l‘intégration SnapLogic Hive, vous pouvez exécuter n‘importe quel DML/DDL Hive, y compris la création de bases de données et de tables.
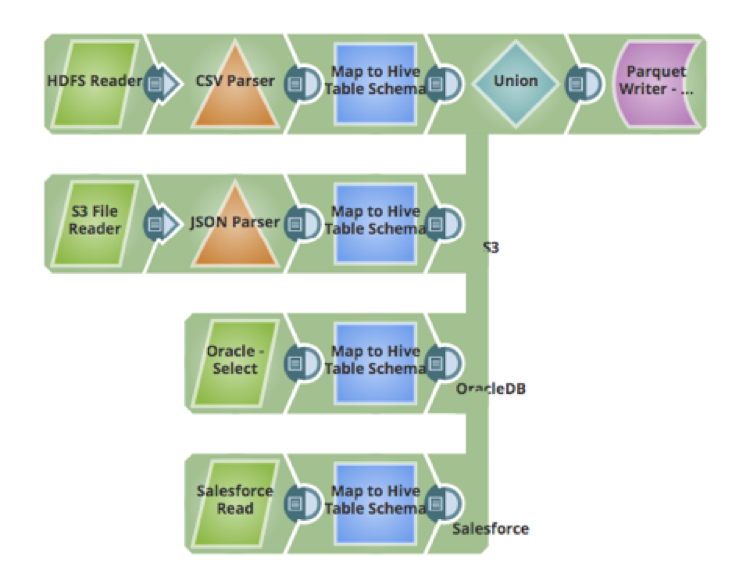
L‘étape suivante consiste à ingérer les données. L‘une des difficultés rencontrées lors de l‘ingestion de données provenant de sources multiples est de savoir comment mapper, transformer et nettoyer les données. En utilisant le snap Mapper, il est possible de mapper les champs du schéma source vers le schéma cible, de nettoyer les données, d‘effectuer des transformations sur les données, d‘ajouter de nouveaux attributs au schéma, et d‘autres actions. Voici un pipeline qui récupère les données de 4 sources, les transforme pour les faire correspondre à la table Hive et les insère dans la table Hive (qui utilise le format de données Parquet) :
- Fichiers de données brutes CSV sur HDFS
- Fichiers JSON hébergés sur Amazon S3
- Données d‘une table dans une base de données Oracle
- Données hébergées dans une application cloud telle que Salesforce
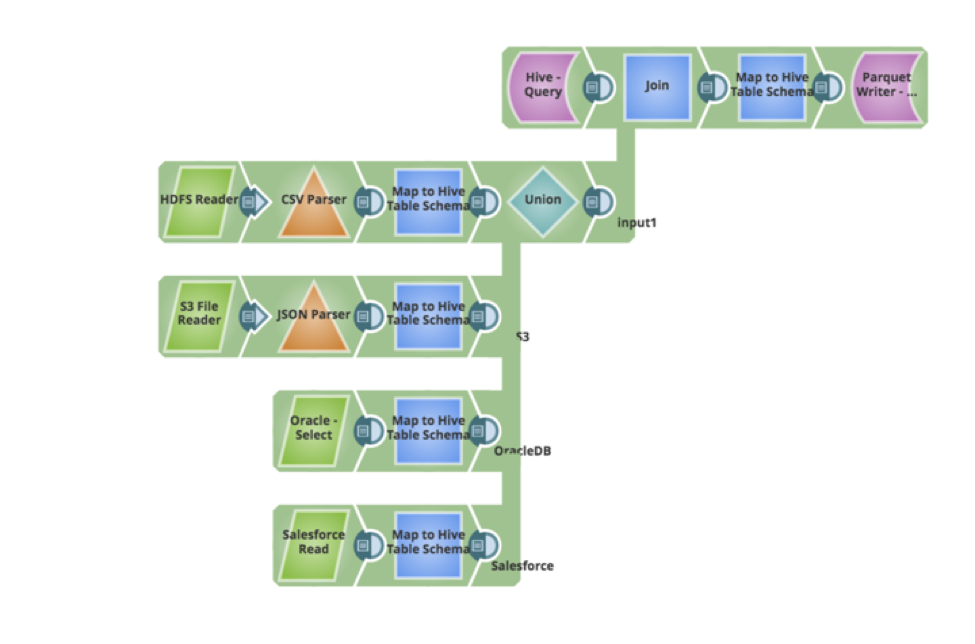
Supposons que nous ayons une nouvelle exigence de la part de vos utilisateurs - que les données existantes dans la table Hive doivent être mises à jour et que de nouveaux enregistrements de données doivent être insérés. Le pipeline peut être facilement mis à jour pour interroger les données existantes, effectuer une jointure externe complète et écrire les données en retour sous forme de parquet. Voici le pipeline qui a mis en œuvre les nouvelles exigences, le tout réalisé de manière visuelle, sans écrire de code ou de script.
Dans mon prochain article, j‘aborderai d‘autres modèles d‘ingestion et la manière de les mettre en œuvre à l‘aide de la plate-forme SnapLogic.





