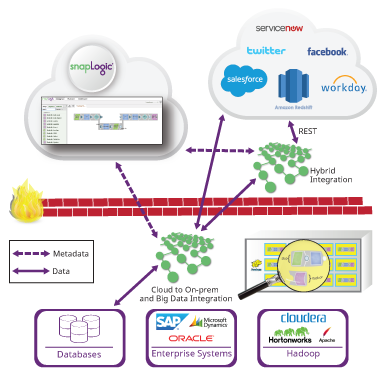
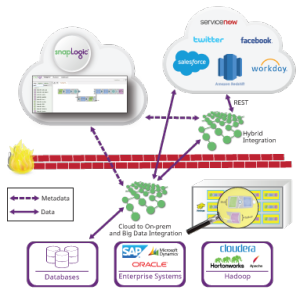
 L‘un des objectifs de SnapLogic est de faire correspondre les exigences d‘exécution des flux de données avec une exécution appropriée plateforme. Les différentes plateformes de données offrent des avantages différents. L‘objectif de ce billet est d‘expliquer la nature des pipelines de flux de données et la manière de choisir l‘architecture d‘intégration de données appropriée. Outre la catégorisation des pipelines, j‘expliquerai les cibles d‘exécution actuellement prises en charge et la prise en charge prévue d‘Apache Spark.
L‘un des objectifs de SnapLogic est de faire correspondre les exigences d‘exécution des flux de données avec une exécution appropriée plateforme. Les différentes plateformes de données offrent des avantages différents. L‘objectif de ce billet est d‘expliquer la nature des pipelines de flux de données et la manière de choisir l‘architecture d‘intégration de données appropriée. Outre la catégorisation des pipelines, j‘expliquerai les cibles d‘exécution actuellement prises en charge et la prise en charge prévue d‘Apache Spark.
Tout d‘abord, quelques préliminaires. Toutes les données traitées par les pipelines SnapLogic sont gérées nativement dans un format JSON interne. C‘est ce que nous appelons le traitement orienté documents. Même les données plates, orientées enregistrement, sont converties en JSON pour le traitement interne. Cela nous permet de gérer les données plates et hiérarchiques de manière transparente. Les pipelines sont construits à partir de Snaps. Chaque Snap encapsule une application spécifique ou une fonctionnalité technologique. Les Snaps sont connectés entre eux pour réaliser un processus de flux de données. Les pipelines sont construits à l‘aide de notre concepteur visuel. Certains snaps assurent la connectivité, comme la connexion à des bases de données ou à des applications cloud . Certains Snaps permettent de transformer les données, par exemple en filtrant les documents, en ajoutant ou en supprimant des champs ou en modifiant des champs. Nous avons également des Snaps qui effectuent des opérations plus complexes telles que le tri, la jointure et l‘agrégation.
Compte tenu de cette configuration, nous pouvons classer les pipelines en deux catégories : les pipelines de flux et les pipelines d‘accumulation. Dans une chaîne de traitement en continu, les documents peuvent circuler indépendamment les uns des autres. Le traitement d‘un document ne dépend pas d‘un autre document lorsqu‘ils circulent dans le pipeline. Les pipelines de ce type sont peu gourmands en mémoire, car les documents peuvent quitter le pipeline une fois qu‘ils ont atteint le dernier Snap. En revanche, un pipeline à accumulation exige que tous les documents de la source d‘entrée soient collectés avant que des documents de résultat puissent être émis par un pipeline. Les pipelines avec tri, jointure et agrégation sont des pipelines à accumulation. Dans certains cas, un pipeline peut être partiellement accumulateur. Ces pipelines accumulateurs peuvent avoir des besoins en mémoire élevés en fonction du nombre de documents provenant d‘une source d‘entrée.
Passons maintenant aux plates-formes d‘exécution. SnapLogic dispose d‘un système interne de traitement des données plateforme appelé Snaplex. Imaginez un Snaplex comme une collection de nœuds de traitement ou de conteneurs qui peuvent exécuter les pipelines SnapLogic. Nous avons plusieurs types de Snaplex :
- Un Cloudplex est un Snaplex que nous hébergeons sur le site cloud et qui peut s‘adapter automatiquement à l‘augmentation de la charge du pipeline.
- Un Groundplex est un ensemble fixe de nœuds installés sur place ou dans un VPC du client. Avec un Groundplex, les clients peuvent effectuer tous leurs traitements de données derrière leur pare-feu, de sorte que les données ne quittent pas leur infrastructure.
Nous élargissons également notre prise en charge des plates-formes de données externes. Nous avons récemment lancé notre technologie Hadooplex qui permet aux clients SnapLogic d‘utiliser Hadoop comme cible d‘exécution pour les pipelines SnapLogic. Un Hadooplex s‘appuie sur YARN pour planifier les conteneurs Snaplex sur les nœuds Hadoop afin d‘exécuter les pipelines. De cette manière, il est possible de procéder à une mise à l‘échelle automatique à l‘intérieur d‘un cluster Hadoop. Nous avons récemment introduit SnapReduce 2.0, qui permet à un Hadooplex de traduire les pipelines SnapLogic en tâches MapReduce. Un utilisateur construit un pipeline SnapReduce désigné et spécifie les fichiers HDFS ainsi que l‘entrée et la sortie. Ces pipelines sont compilés en tâches MapReduce pour être exécutés sur de très grands ensembles de données qui se trouvent dans HDFS (voir la démonstration dans notre récent article sur cloud et l‘analyse des grandes données webinar).
Enfin, comme nous l‘avons annoncé la semaine dernière dans le cadre de l‘annonce de Cloudera sur le streaming en temps réel, nous avons commencé à travailler sur notre support de Spark en tant que cible big data plateforme. Un Sparkplex pourra utiliser la connectivité étendue de SnapLogic pour amener les données dans et hors des RDD (Resilient Distributed Datasets) de Spark. De plus, comme pour SnapReduce, nous allons permettre aux utilisateurs de compiler les pipelines SnapLogic en codes Spark afin que les pipelines puissent s‘exécuter en tant que jobs Spark. Nous prendrons en charge les tâches Spark en streaming et en batch. En incluant Spark dans notre support des données plateforme , nous donnerons à nos clients un ensemble complet d‘options pour l‘exécution des pipelines.
Le choix de la bonne solution big data plateforme dépend de nombreux facteurs : taille des données, exigences en matière de latence, connectivité et type de pipeline (streaming ou accumulation). Voici quelques lignes directrices pour le choix d‘une intégration de big data particulière plateforme:
Cloudplex
- Cloud-to-cloud flux de données
- Diffusion en continu d‘un nombre illimité de documents
- Pipelines d‘accumulation dans lesquels les données accumulées peuvent tenir dans la mémoire du nœud
Complexe Terrestre
- Flux de données sol à sol, sol àcloud et cloud-to-ground
- Diffusion en continu d‘un nombre illimité de documents
- Pipelines d‘accumulation dans lesquels les données accumulées peuvent tenir dans la mémoire du nœud
Hadooplex
- Flux de données sol à sol, sol àcloud et cloud-to-ground
- Diffusion en continu d‘un nombre illimité de documents
- Les pipelines d‘accumulation peuvent opérer sur des données de taille arbitraire via MapReduce
Sparkplex
- Flux de données sol à sol, sol àcloud et cloud-to-ground
- Permettre la connectivité Spark à tous les comptes SnapLogic
- Diffusion en continu d‘un nombre illimité de documents
- Les pipelines d‘accumulation peuvent opérer sur des données dont la taille peut tenir dans la mémoire d‘un cluster Spark.
 Il est à noter que les travaux récents de la communauté Spark ont augmenté la prise en charge des calculs hors cœur, tels que le tri. Cela signifie que les pipelines d‘accumulation qui ne sont actuellement adaptés qu‘à l‘exécution MapReduce peuvent être pris en charge par Spark lorsque la prise en charge de Spark hors du cœur se généralise. Hadooplex et Sparkplex ont ajouté des avantages en matière de fiabilité d‘exécution, de sorte que les pipelines à long terme sont garantis de se terminer.
Il est à noter que les travaux récents de la communauté Spark ont augmenté la prise en charge des calculs hors cœur, tels que le tri. Cela signifie que les pipelines d‘accumulation qui ne sont actuellement adaptés qu‘à l‘exécution MapReduce peuvent être pris en charge par Spark lorsque la prise en charge de Spark hors du cœur se généralise. Hadooplex et Sparkplex ont ajouté des avantages en matière de fiabilité d‘exécution, de sorte que les pipelines à long terme sont garantis de se terminer.
Chez SnapLogic, notre objectif est de permettre aux clients de créer et d‘exécuter des pipelines de flux de données arbitraires sur les données les plus appropriées plateforme. En outre, nous fournissons une interface graphique simple et cohérente pour développer des pipelines qui peuvent ensuite être exécutés sur n‘importe quel support plateforme. Notre approche plateforme agnostique dissocie la spécification du traitement des données de l‘exécution du traitement des données. Lorsque votre volume de données augmente ou que les exigences en matière de latence changent, le même pipeline peut s‘exécuter sur des données plus volumineuses et à un rythme plus rapide en changeant simplement les données cibles plateforme. En fin de compte, SnapLogic vous permet de vous adapter à vos exigences en matière de données et ne vous enferme pas dans un big data spécifique plateforme.