






La capacité à gérer de vastes quantités de données est essentielle à la réussite de toute organisation, bien que la plupart d‘entre elles restent à la traîne et peinent à obtenir des résultats fondés sur les données. Même avec des données riches en informations à portée de main, selon un article de mai 2017 publié dans Harvard Business Review, "plus de 70 % des employés ont accès à des données qu‘ils ne devraient pas avoir, et 80 % du temps des analystes est consacré à la simple découverte et à la préparation des données."
Quel est le rôle de l‘apprentissage automatique ? Face à l‘explosion du besoin de mieux comprendre les données, nous avons discuté avec des clients qui se tournaient vers l‘apprentissage automatique pour obtenir de l‘aide et nous avons constaté que leurs ingénieurs de données consacraient 70 à 80 % de leur temps à l‘acquisition, à l‘exploration et à la préparation des données dans le cadre de leur cycle de vie de l‘apprentissage automatique. Nous avons également entendu parler de la pénurie d‘experts en science des données et d‘outils de préparation des données peu utiles, non intégrés et peu maniables. Aujourd‘hui, nous sommes arrivés à la conclusion que l‘apprentissage automatique est en fait un problème d‘intégration, ce qui fait de SnapLogic une solution naturelle pour l‘apprentissage automatique ( plateforme ). En novembre, nous avons donc lancé SnapLogic Data Science pour gérer et contrôler l‘ensemble du cycle de vie de l‘apprentissage automatique.
Dans ce billet de blog, nous passerons en revue certaines des capacités de l‘offre SnapLogic Data Science, et vous verrez comment la préparation des données et l‘apprentissage automatique peuvent être faciles à utiliser, amusants et simples. Vous pouvez également suivre l‘évolution de SnapLogic en vous inscrivant pour un essai gratuit de 30 jours.
Une nouvelle solution d‘apprentissage automatique en libre-service
SnapLogic Data Science - présenté dans notre dernière version comme une extension de l‘intégration intelligente de SnapLogic plateforme - est une nouvelle solution en libre-service qui accélère le développement et le déploiement de l‘apprentissage automatique avec un codage minimal tout au long du cycle de vie de l‘apprentissage automatique, comme illustré ci-dessous.
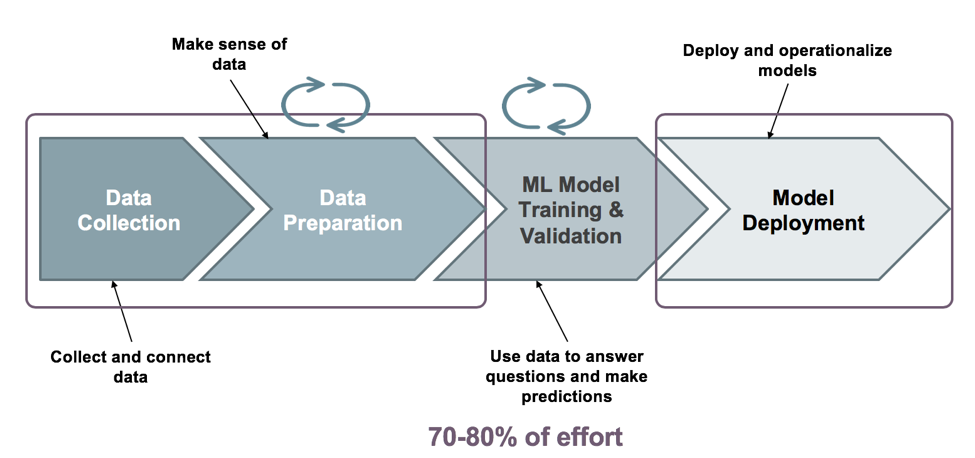
Collecte et préparation des données
Examinons la collecte et la préparation des données et l‘ensemble des capacités que SnapLogic Data Science apporte à ce module d‘apprentissage automatique. C‘est ici qu‘un ingénieur de données accède aux données et les assemble en vue de leur utilisation par des modèles d‘apprentissage automatique et qu‘il procède à l‘ingénierie des fonctionnalités. Vous pouvez également effectuer des opérations préparatoires sur les ensembles de données, telles que la transformation du type de données, le nettoyage des données, l‘échantillonnage, le brassage et la mise à l‘échelle. Ces capacités éliminent la redondance dans la préparation des données qui est parfois introduite par une déconnexion entre la science des données et les équipes IT/DevOps.
L‘offre SnapLogic Data Science propose trois Snap Packs - le ML Data Preparation Snap Pack, le ML Core Snap Pack et le ML Analytics Snap Pack - pour prendre en charge la collecte et la préparation des données.
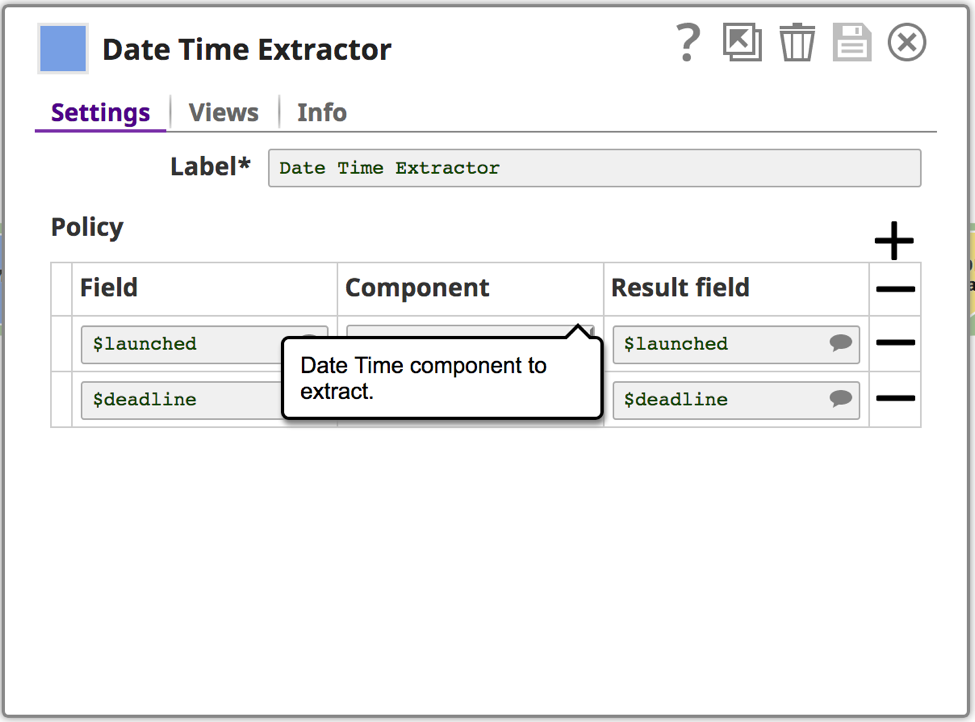
- Le Snap Pack ML Data Preparation Snap Pack permet aux ingénieurs et aux scientifiques des données d‘effectuer des opérations préparatoires sur les ensembles de données, telles que la transformation du type de données, le nettoyage des données, l‘échantillonnage, le brassage et la mise à l‘échelle. Il fournit des snaps clés tels que le Snap Clean Missing Values qui remplace les valeurs manquantes dans les ensembles de données en supprimant ou en imputant des valeurs. Nous disposons également de l‘instantané Extracteur de date et d‘heure qui extrait les composants des objets datetime pour les placer dans des champs de résultat en vue d‘une analyse plus approfondie. L‘option d‘échantillonnage permet de générer des ensembles de données d‘échantillonnage à partir d‘un ensemble de données d‘entrée en utilisant différents types d‘algorithmes d‘échantillonnage tels que l‘échantillonnage stratifié, l‘échantillonnage stratifié pondéré, etc. L‘option Échelle permet de mettre à l‘échelle les valeurs dans les colonnes afin de spécifier des plages ou d‘appliquer des transformations statistiques. L‘option Shuffle Snap (Mélanger) randomise l‘ordre des données des lignes dans l‘ensemble de données.
- L‘ensemble ML Core Snap Pack ML Core Snap Pack permet aux ingénieurs de données d‘effectuer des opérations sur des ensembles de données d‘apprentissage automatique, telles que l‘entraînement de modèles, la validation croisée et les prédictions basées sur des modèles.
- Le ML Analytics Snap Pack permet aux ingénieurs de données d‘effectuer des opérations analytiques telles que le profilage des données et l‘inspection des types de données.
L‘exemple ci-dessous montre comment l‘instantané de nettoyage des valeurs manquantes peut être utilisé dans un pipeline de préparation des données. L‘action Nettoyer les valeurs manquantes est une action instantanée de type transformation utilisée pour traiter les valeurs manquantes dans un jeu de données entrant en supprimant ou en imputant des valeurs et prend en charge quatre approches : Drop Row, Impute with Average, Impute with Popular et Impute with Custom Value.
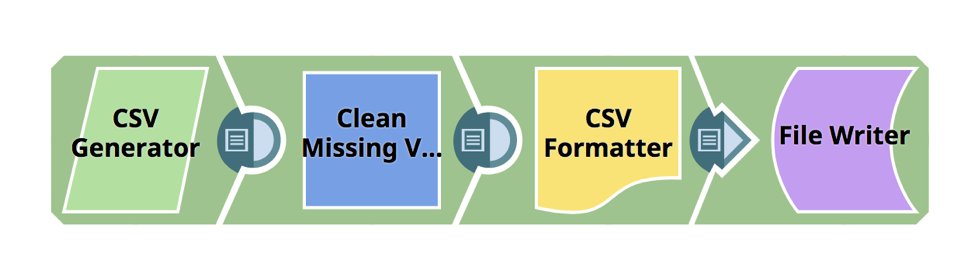
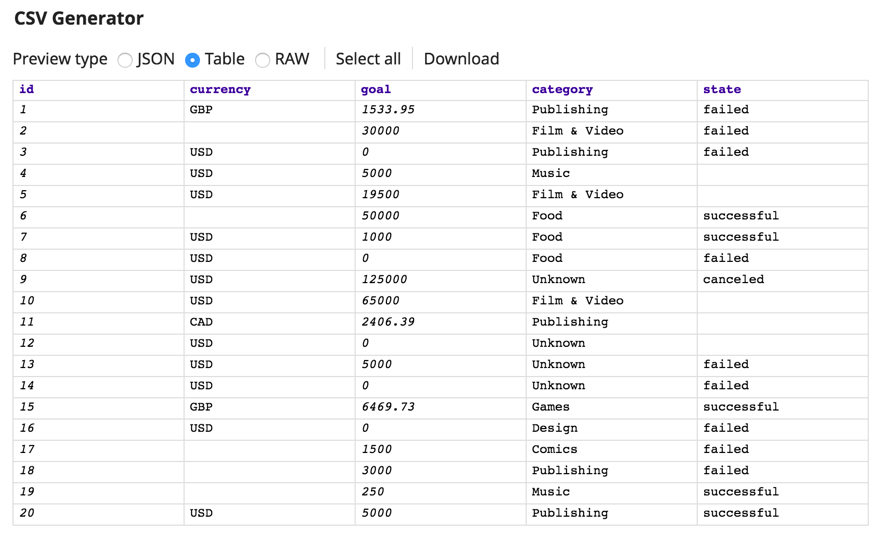
Tout d‘abord, en utilisant le générateur CSV Snap, nous avons un fichier csv simple qui a des valeurs manquantes pour la devise - vous le verrez dans la troisième ligne.
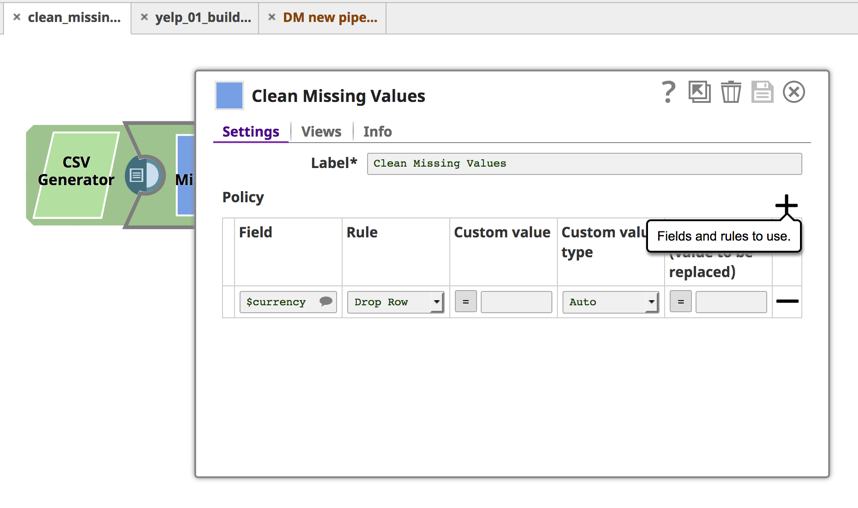
L‘action suivante, Nettoyer les valeurs manquantes, vous permet de définir une règle qui supprimera la ligne si la valeur de la devise est nulle.
Une fois que j‘ai lancé le pipeline, la capture d‘écran ci-dessous montre à quoi ressemble le fichier nettoyé. Vous voyez que cette ligne a été spécifiquement supprimée et que le fichier est maintenant nettoyé.
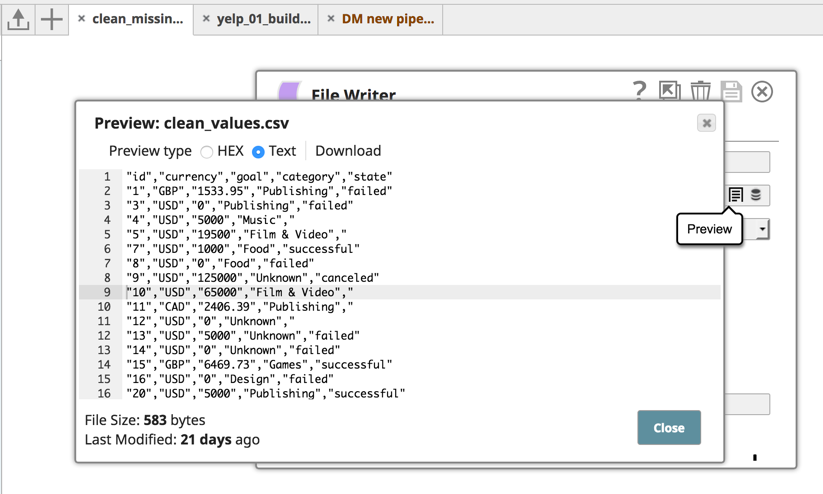
Une fois les données nettoyées, vous pouvez utiliser l‘instantané de profilage pour profiler les données et calculer les statistiques des données entrantes.
Voici un pipeline illustrant cette partie du processus.

En examinant le fichier utilisé pour stocker différents types d‘actifs, vous pouvez voir comment les données sources sont structurées.
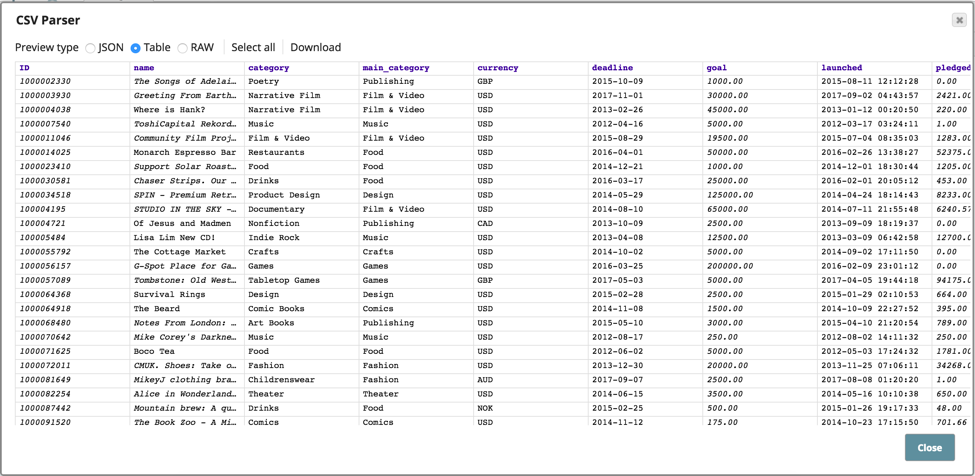
Le pipeline présenté ci-dessus a été configuré pour analyser et profiler les données CSV, puis pour écrire le profil dans un fichier de sortie JSON. Voici à quoi ressemble la sortie du profil avec la distribution des valeurs, etc.
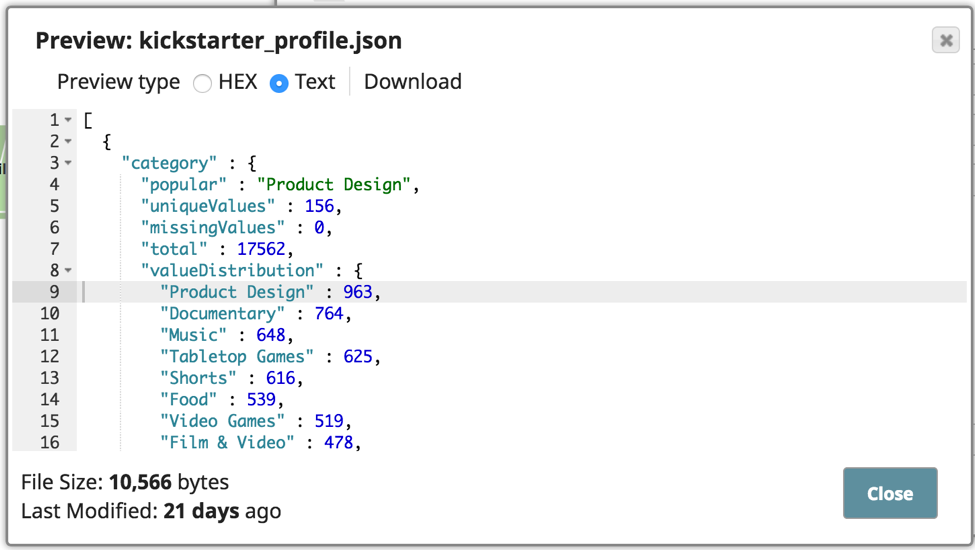
Cela permettra de déterminer les autres opérations de nettoyage des données à effectuer. Une autre chose à souligner est que j‘utilise également l‘instantané de l‘extracteur de date, qui est un instantané de type transformation qui extrait les composants des données temporelles et les ajoute au champ de résultat. Dans ce cas, j‘extrais la valeur de l‘époque dans le champ de résultat. Vous pouvez utiliser l‘action rapide pour préparer les données avant d‘effectuer l‘agrégation ou l‘analyse.
Donner du pouvoir au data scientist qui sommeille en vous
J‘espère que ce rapide pas-à-pas de SnapLogic Data Science montre que l‘exécution des tâches de préparation des données peut être à la fois amusante et simple. Désormais, les data scientists peuvent commencer leur travail d‘analyse du problème et construire des modèles basés sur la ML plus rapidement qu‘auparavant. Quant aux ingénieurs de données, ils peuvent préparer les données - en les intégrant à partir de sources multiples et en les mettant sous une forme utilisable - en libre-service.
Vous ne me croyez pas ? Inscrivez-vous à l‘essai gratuit de 30 jours.







