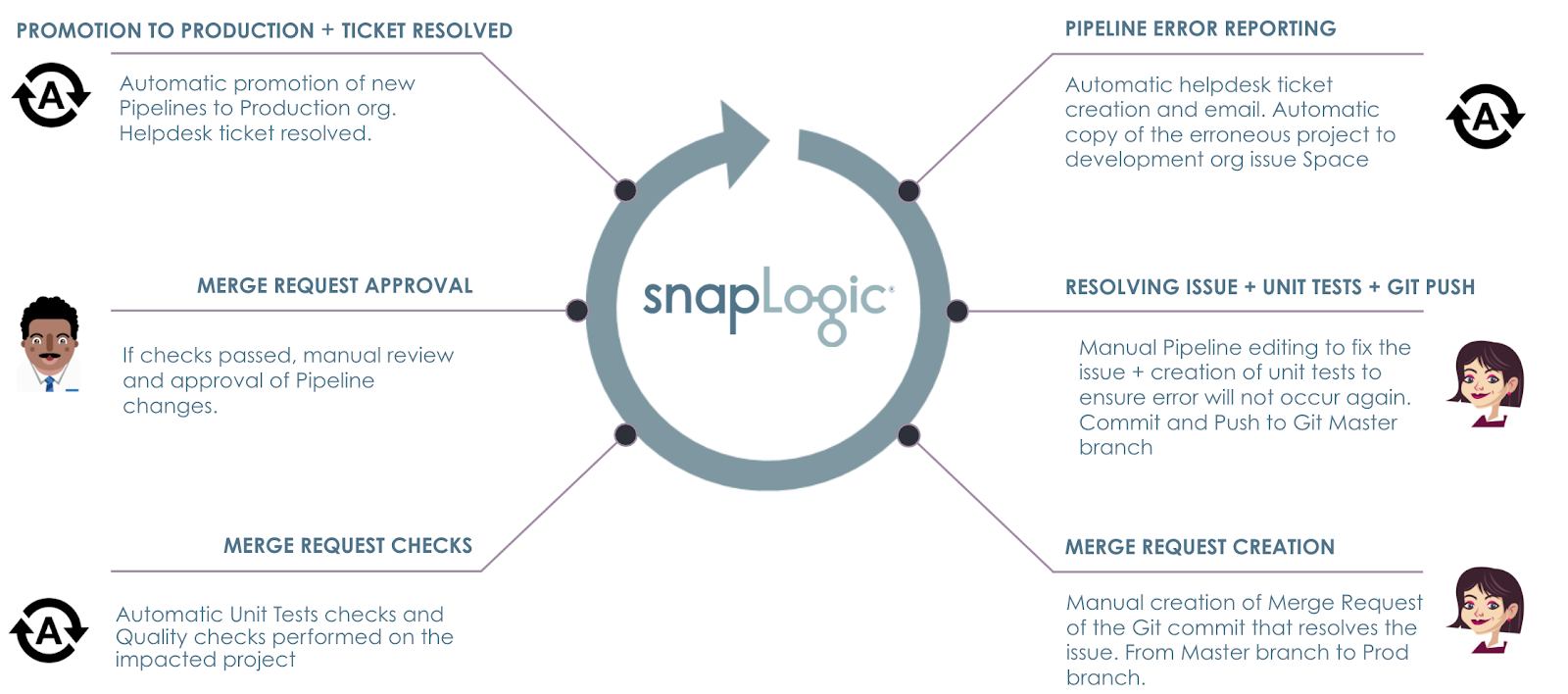
Cet article de blog est la deuxième partie d‘une série qui vise à présenter un ensemble de défis auxquels les entreprises sont confrontées dans le cadre du développement d‘une intégration moderne et comment vous pouvez relever ces défis facilement avec SnapLogic. Vous pouvez trouver lapremière partie de cette série ici.
Vous apprendrez ainsi comment SnapLogic plateforme vous aide efficacement à
- effectuer des contrôles de qualité à l‘aide de tests unitaires et veiller au respect de la politique.
- gérer les demandes de fusion
- promouvoir les changements dans la production et informer les parties prenantes
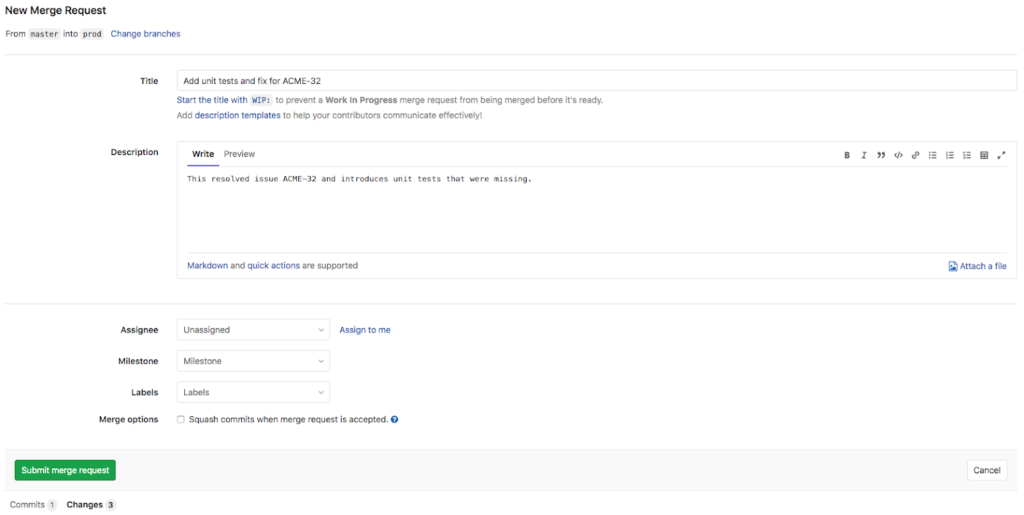
Création d‘une demande de fusion
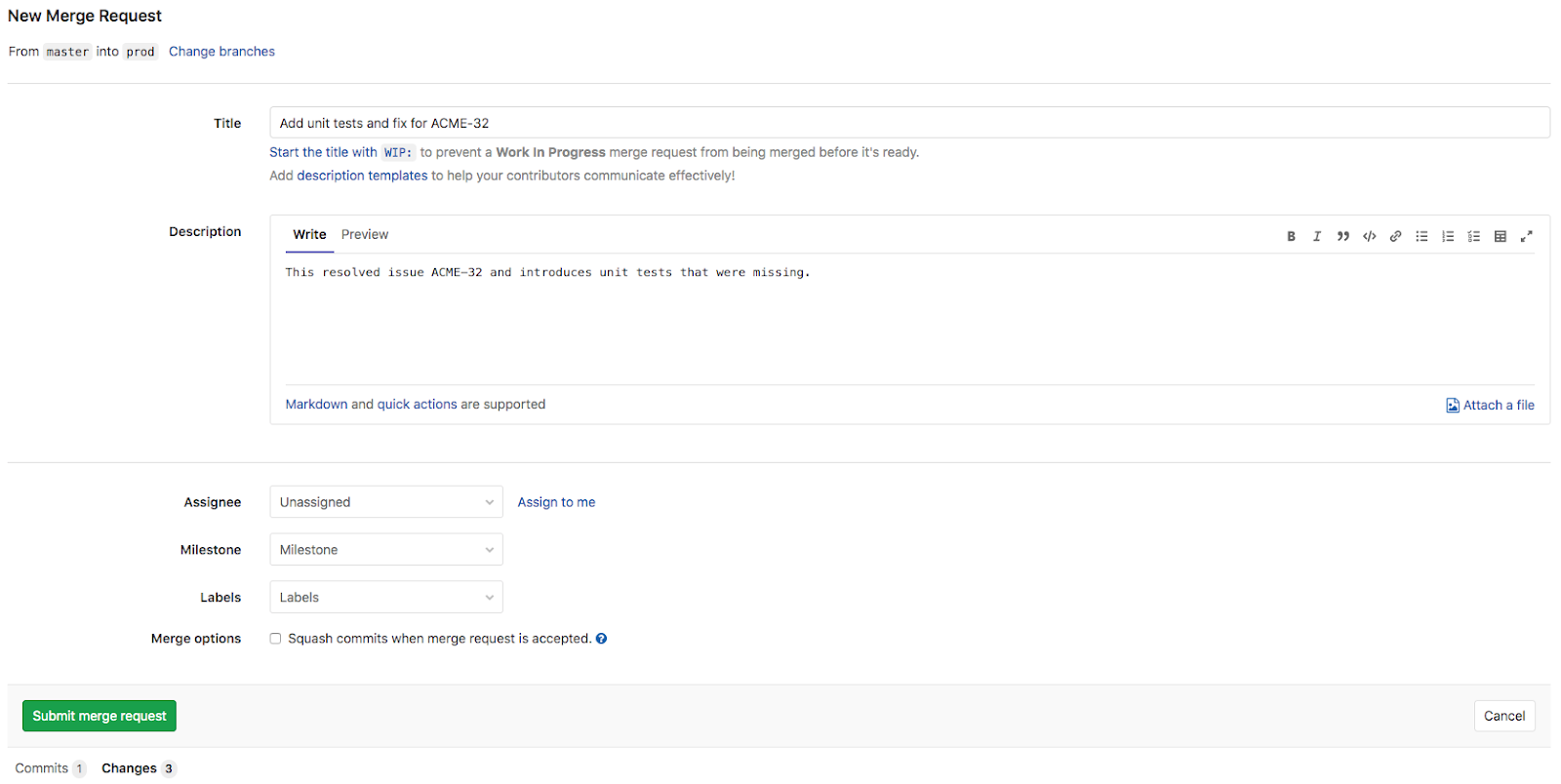
Après qu‘un intégrateur a identifié une solution pour résoudre les problèmes, la dernière étape consiste pour l Intégrateur va maintenant créer une demande de fusion dans GitLab pour demander que les changements soient fusionnés dans la branche Prod à partir de la branche Master.
Note : Ce billet de blog passe directement de la branche Master à la branche Prod - promouvant ainsi les ressources de l‘environnement de développement à l‘environnement de production. Cela ne reflète pas nécessairement les meilleures pratiques pour les structures d‘organisation et les politiques de tous les clients.
Contrôles des demandes de fusion
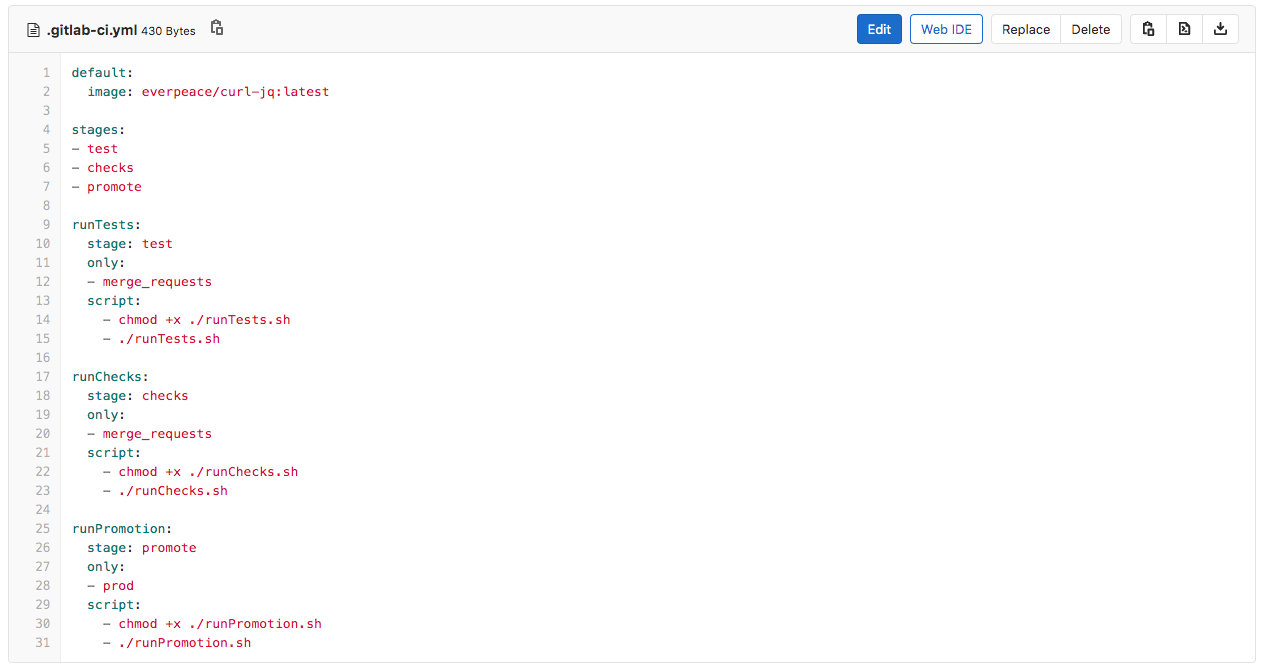
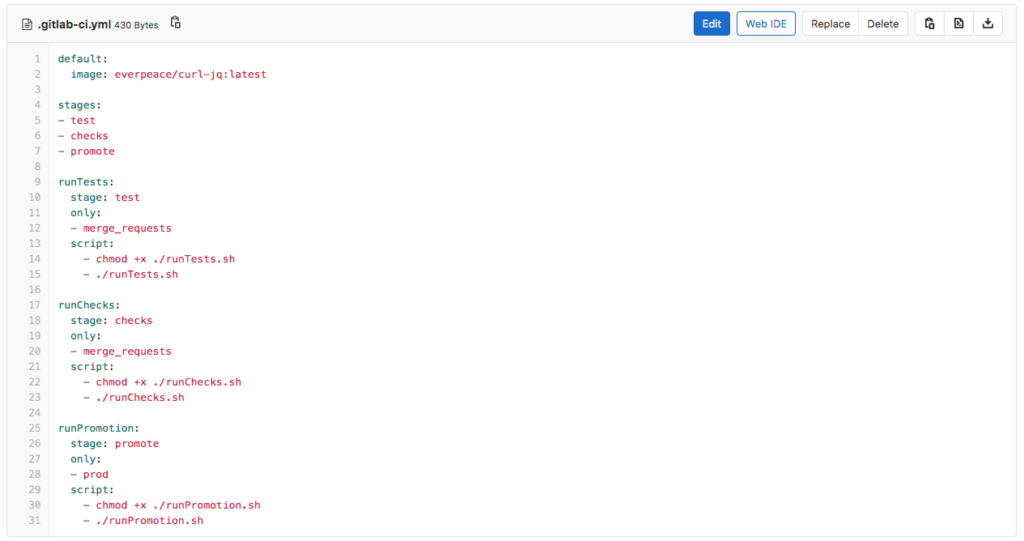
Lors de la création de la demande de fusion, GitLab lancera automatiquement un pipeline CI/CD qui comprend deux tâches ; runTests et runChecks. Pour que cela fonctionne, l ingénieur CI/CD (veuillez vous référer à la partie 1 de cette série) a créé un fichier de configuration CI/CD GitLab. Le fichier de configuration CI/CD (voir ci-dessous) effectue les tâches suivantes :
- Exécuter les tests
- Ne fonctionne que pour les demandes de fusion
- Les exécutions de la première étape appelée test
- Exécute le script runTests.sh
- Exécuter les contrôles
- Ne fonctionne que pour les demandes de fusion
- La deuxième étape, appelée contrôles
- Exécute le script runChecks.sh
- exécuterPromotion
- Ne s‘exécute que pour les modifications de la branche Prod
- La troisième étape, appelée promouvoir
- Exécute le script runPromotion.sh
Note : Bien que ce billet de blog utilise les fonctionnalités de GitLab pour CI/CD, il est important de comprendre qu‘en raison du support REST et JSON de SnapLogic plateforme, la création de jobs similaires dans d‘autres outils comme Azure DevOps, GitHub, Bamboo, etc. suit la même logique et les mêmes technicités.
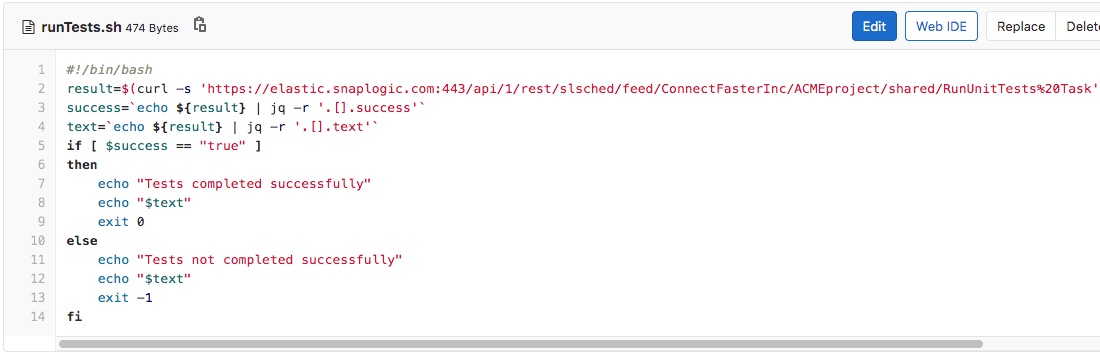
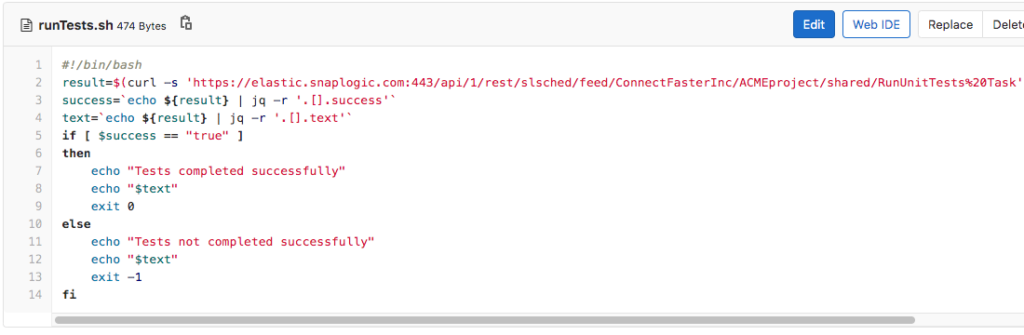
Comme indiqué, l ingénieur CI/CD n‘a configuré que deux tâches à exécuter lors de la création d‘une demande de fusion : runTest et runCheckset ils seront exécutés dans cet ordre. Voyons d‘abord ce qui se passe lorsque la première tâche (runTests) est lancé et que le script runTests.sh (illustré ci-dessous) est exécuté. Tout d‘abord, il exécute une tâche déclenchée par SnapLogic nommée RunUnitTests Task. Il vérifie ensuite si le résultat est positif ou négatif, et en fonction du résultat, il fait passer ou échouer l‘ensemble du pipeline CI/CD.
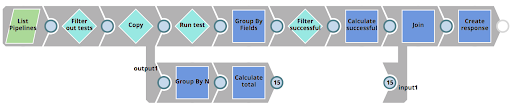
La tâche RunUnitTests exécute un pipeline appelé RunUnitTests, comme indiqué ci-dessous. Ce pipeline effectue les opérations suivantes
- Liste de tous les pipelines du projet concerné
- Filtre les pipelines qui ne sont pas soumis à des tests unitaires
- Pour chaque pipeline, exécute le pipeline 01_UnitTestingTemplate à l‘aide de l‘action d‘exécution du pipeline (intitulée Run test).
- Filtre les résultats testés avec succès
- Compare le nombre de tests réussis au nombre total de tests et crée une réponse au client, indiquant le nombre de tests terminés par rapport au nombre de tests échoués.
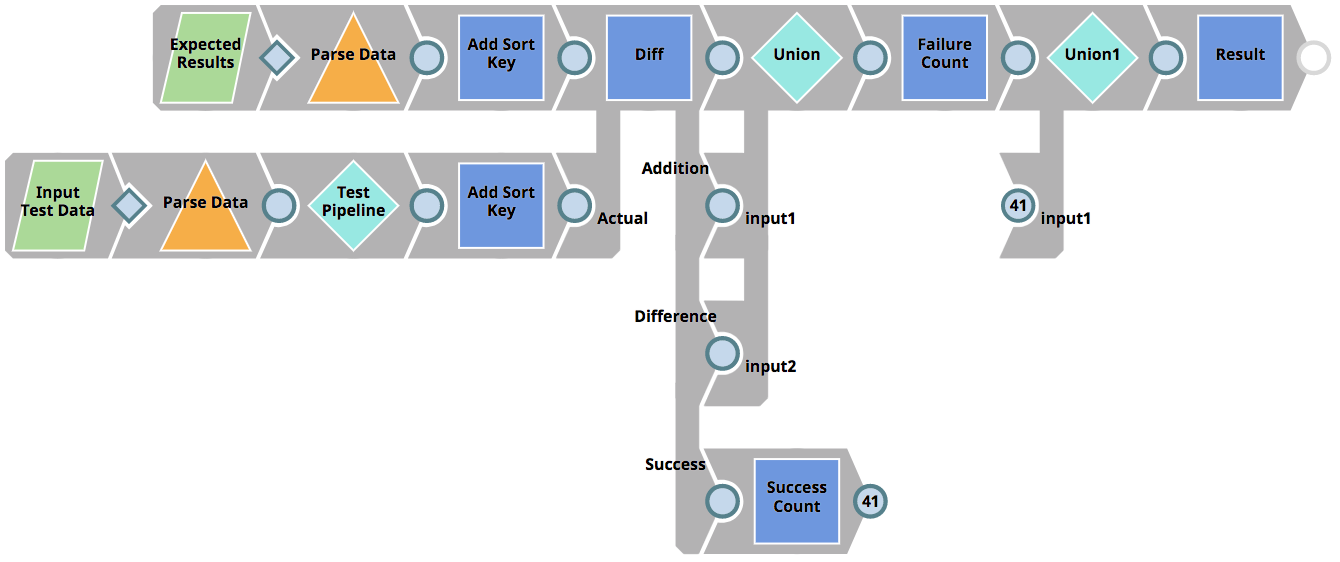
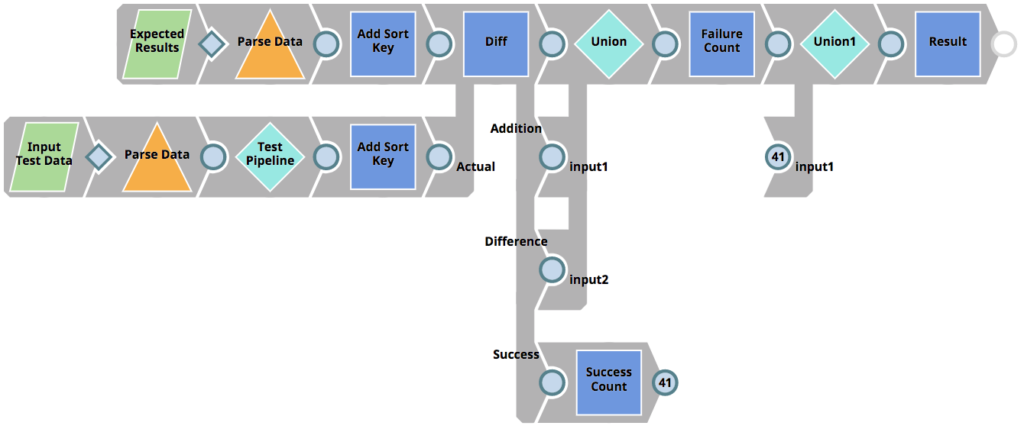
Comme indiqué plus haut, le pipeline RunUnitTests détermine les pipelines pour lesquels des tests doivent être effectués et renvoie les résultats des tests au client, mais il n‘exécute pas les tests eux-mêmes. Au lieu de cela, il invoque le pipeline 01_UnitTestingTemplate pour chaque pipeline soumis à des tests. Cette ligne de conduite est présentée ci-dessous. Elle effectue les opérations suivantes.
- Reads the expected results (parameterized as <Pipeline_name>_result.json) – in our case from the file CustomerToSalesforce_result.json (see previous chapters).
- Read the input test data (parameterized as <Pipeline_name>_input.json) – in our case from the file CustomerToSalesforce_input.json (see previous chapters).
- Executes the target Pipeline (parameterized as <Pipeline_name>_target) – in our case from the file CustomerToSalesforce_target (see previous chapters) using the Pipeline Execute Snap (labelled as Test Pipeline)
- Utilise le Diff Snap pour comparer les données du résultat attendu avec les résultats réels basés sur le pipeline exécuté (la cible CustomerToSalesforce_target avec les données de test CustomerToSalesforce_input.json). Le Diff Snap affiche chaque ligne comme étant soit supprimée, soit insérée, soit modifiée, soit non modifiée. Ce n‘est que si toutes les lignes sont non modifiées (vue étiquetée comme Succès) que le test sera considéré comme réussi.
- Renvoie le résultat du test individuel au pipeline parent (RunUnitTests)
Le processus et les lignes de conduite ci-dessus ont été approuvés par le responsable du test et l‘ingénieur ingénieur CI/CD ainsi que l‘ensemble de l‘équipe d‘intégration sur la base des exigences et des politiques d‘ACME. Il peut y avoir d‘autres tests - tels que des tests de performance et des tests fonctionnels - qui sont hors de portée pour ce poste.
Note : Vous verrez le résultat des tests unitaires et des contrôles de qualité plus loin dans ce billet.
Si tous les tests sont réussis et que le script runTests.sh aboutit, l‘étape et le travail suivants (runChecks) dans la configuration CI/CD de GitLab est exécutée - en invoquant le script runChecks.sh. Le script runChecks a été convenu entre l‘ingénieur ingénieur CI/CD et le responsable de la sécurité. Le responsable responsable de la sécurité exige qu‘un ensemble de règles et de politiques soit appliqué aux pipelines et aux autres actifs SnapLogic qui doivent être mis en production. Ces politiques pourraient inclure
- Conventions d‘appellation sur les pipelines, les étiquettes Snap ou d‘autres propriétés
- Snaps interdits
- Paramètres interdits dans les Snaps
Pour ACME, le responsable de la sécurité fournit les politiques suivantes (définies au format JSON)
[
{
"class" : "com-snaplogic-snaps-transform-recordreplay",
"conditionnel" : faux
},
{
"class" : "com-snaplogic-snaps-binary-aesencrypt",
"conditionnel" : vrai,
"paramètres" : [
{
"name" : "cipherMode",
"allowedValue" : "CBC"
}
]
}
]
En effet, l‘intention de la politique susmentionnée est de
- Évitez d‘utiliser l‘option Record Replay Snap dans l‘organisation de production. ACME est une entreprise fortement auditée qui ne peut autoriser l‘enregistrement de données clients sur un support de stockage persistant.
- Évitez d‘utiliser l‘option AES Encrypt Snap si le paramètre du mode de chiffrement est pas n‘est pas réglé sur CBC. ACME a mis en place une politique de sécurité à l‘échelle de l‘entreprise qui consiste à n‘utiliser que le mode CBC lors du cryptage.
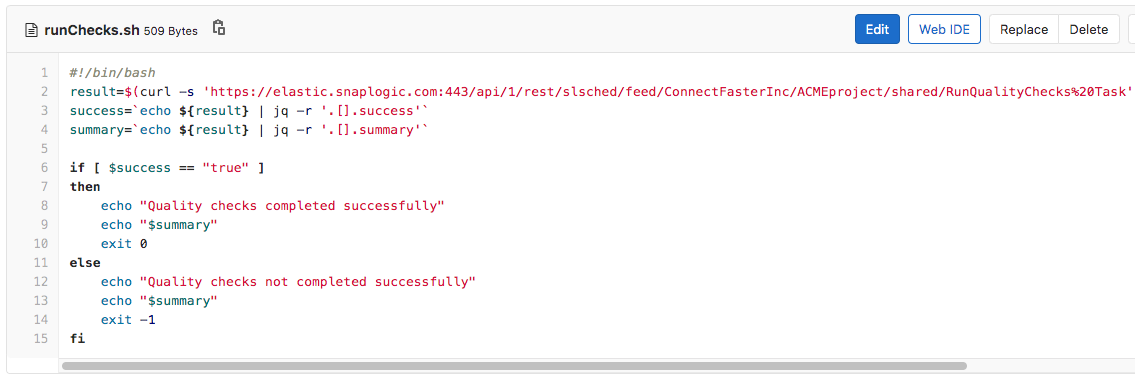
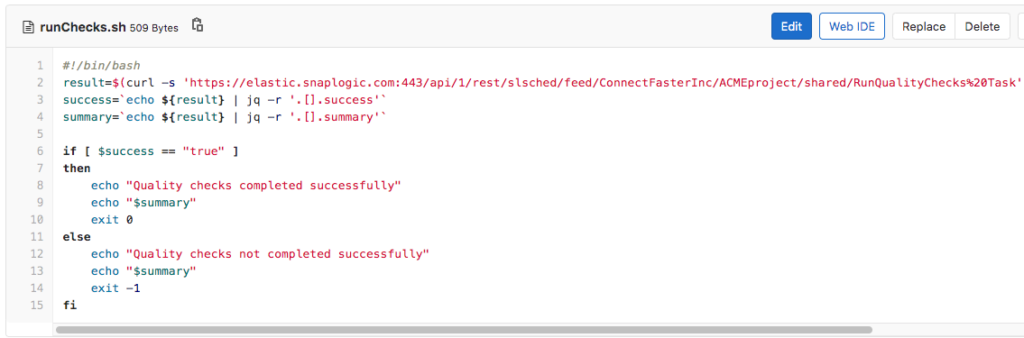
Cette politique signifie que tout Snap Record Replay ou tout Snap AES Encrypt (qui n‘a pas CBC comme mode de chiffrement) ne sera pas autorisé en production. Pour ce faire, le script runChecks.sh appellera une tâche SnapLogic Triggered Task pour vérifier les pipelines impactés par rapport au document de politique et faire échouer le travail s‘il enfreint les politiques. Le script runChecks.sh est présenté ci-dessous.
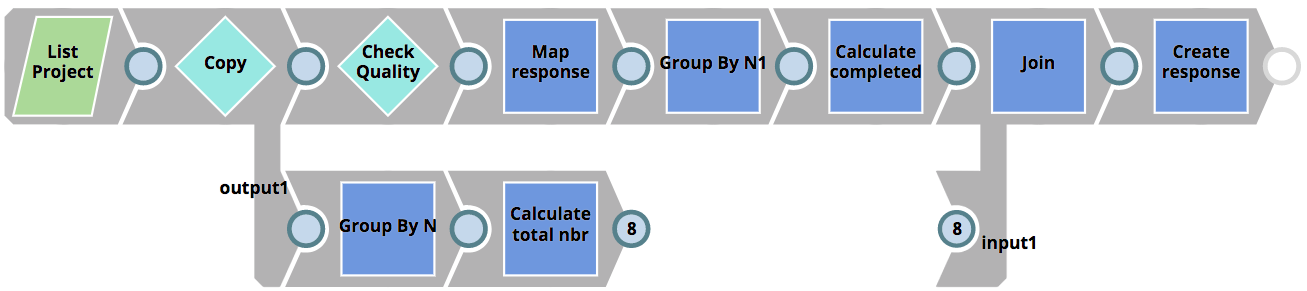
La tâche RunQualityChecks Triggered Task invoquée par le script runChecks.sh exécute le pipeline RunQualityChecks que l‘on peut voir ci-dessous. Sa logique ressemble à celle du pipeline RunUnitTests présenté plus haut.
- Liste de tous les pipelines du projet concerné
- Pour chaque pipeline, exécute le pipeline 01_QualityCheck à l‘aide de l‘instantané d‘exécution du pipeline (intitulé Check Quality).
- Calcul du nombre de pipelines réussis
- Compare le nombre de contrôles réussis au nombre total de contrôles, puis envoie une réponse au client, contenant le nombre de contrôles réussis et le nombre de contrôles échoués, ainsi que la raison pour laquelle les tests ont échoué.
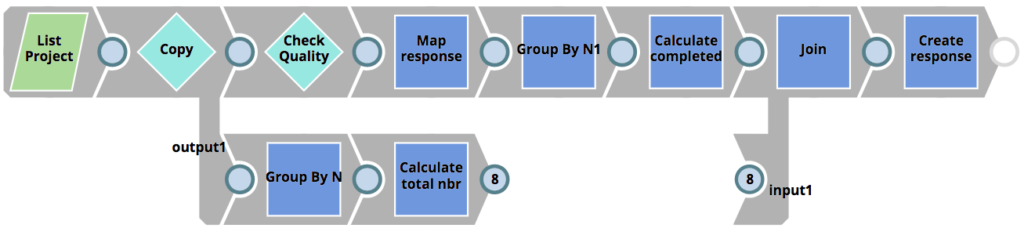
Comme pour les pipelines de tests unitaires, le pipeline RunQualityChecks détermine les pipelines pour lesquels des contrôles doivent être effectués et renvoie les résultats des contrôles au client, mais il n‘exécute pas lui-même les contrôles de qualité. En revanche, il invoque le pipeline 01_QualityCheck pour chaque pipeline soumis à des contrôles de qualité. Ce pipeline est illustré ci-dessous. Elle effectue les opérations suivantes.
- Lire la ligne de conduite sous réserve de contrôles de qualité
- Extrait tous les Snaps utilisés dans le Pipeline. Comme SnapLogic est une application JSON native plateforme, les Snaps et leurs propriétés sont simplement des objets JSON.
- Lit et analyse le document JSON de la politique de l‘ACME fourni par le responsable de la sécurité.
- Joindre les Snaps aux Snaps de la politique pour s‘assurer que seuls les Snaps qui ont une correspondance dans la politique sont vérifiés.
- Vérifie si un Snap est autorisé ou non
- Vérifie si un Snap est autorisé sous conditions ou non (par exemple, les paramètres sont autorisés).
- Crée une réponse au pipeline parent avec les résultats.

Si les contrôles de qualité sont satisfaisants (après que les tests unitaires ont été réussis), la demande de fusion est prête à être approuvée.
Approbation de la demande de fusion
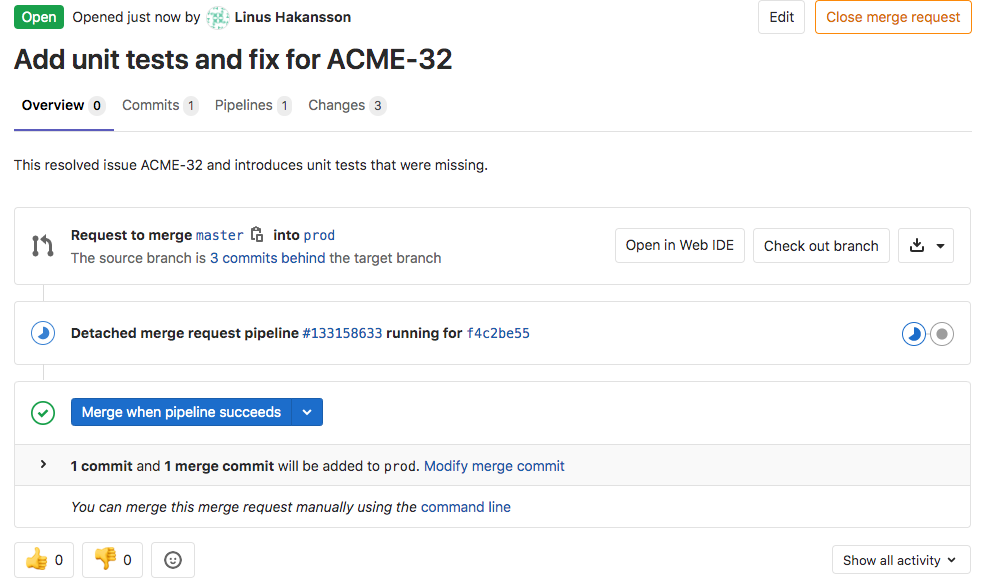
L‘architecte L‘architecte est maintenant chargé d‘examiner la demande de fusion. Si les modifications sont pertinentes et que les tests unitaires automatiques et les contrôles de qualité ont été effectués avec succès, l architecte approuvera et fusionnera la demande. Il commence par ouvrir la demande de fusion (voir ci-dessous) pour voir le résumé de son contenu.
- Le titre de la demande de fusion a été remplacé par défaut par le titre du commit Git unique.
- La demande de fusion contient un seul commit
- Le commit unique contient trois changements : 1 fichier modifié et 2 ajouts.
- Un pipeline CI/CD de demande de fusion est en cours d‘exécution (indiqué par l‘icône de progression bleue).
- Il existe une option permettant de fusionner la demande lorsque ce pipeline a abouti.
Avant d‘examiner les modifications de la demande de fusion, le pipeline se termine par le résumé ci-dessous des étapes/travaux. Comme on peut le voir, les étapes runTetsts s‘est achevé avec succès. Cependant, le job runChecks ne l‘a pas fait. Nous pouvons nous pencher sur ces deux tâches pour comprendre ce qui s‘est passé.
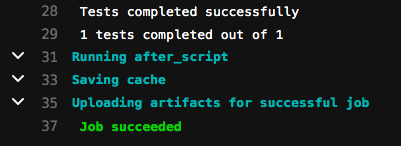
Tout d‘abord, ouvrons la fenêtre runTests pour en voir le résumé. Comme vous pouvez le voir ci-dessous, les tests se sont terminés avec succès.
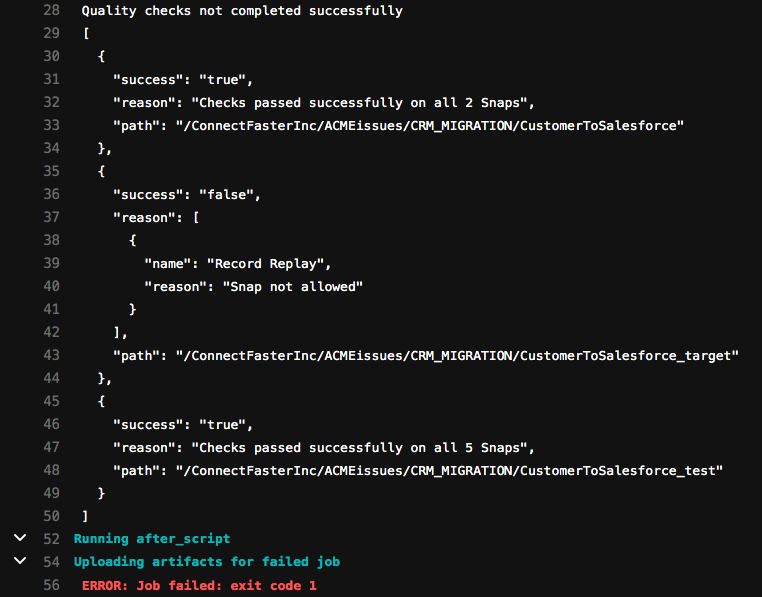
Deuxièmement, examinons le résumé de la tâche runChecks. Contrairement au résumé de runTests, ce travail n‘est pas terminé. Il indique que les contrôles de qualité n‘ont pas été menés à bien. Sur les trois pipelines contrôlés (CustomerToSalesforce, CustomerToSalesforce_target et CustomerToSalesforce_test), l‘un d‘entre eux a échoué - le pipeline CustomerToSalesforce_target. Si vous vous référez à la conception de ce pipeline présentée plus haut dans ce billet, vous verrez que nous avons utilisé un Snap de relecture d‘enregistrement pour nous aider pendant le développement. Cependant, conformément aux politiques fournies par le responsable de la sécuritécela n‘est pas autorisé en production.
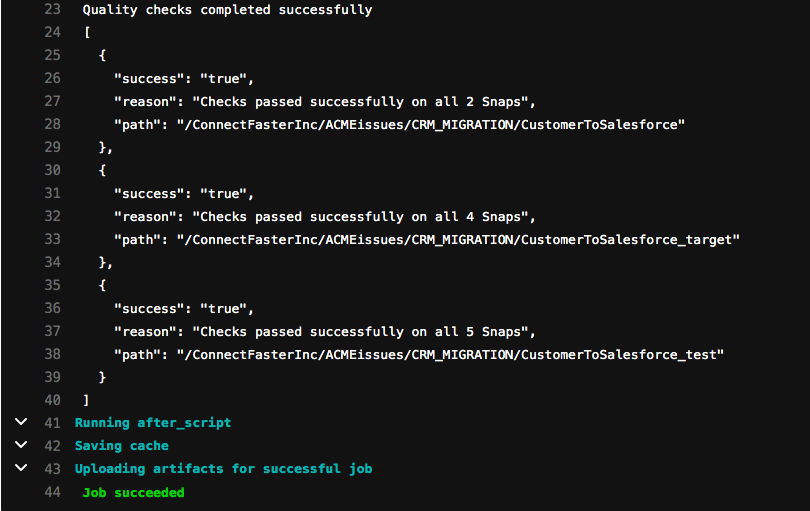
L‘architecte Architecte peut maintenant se synchroniser avec l intégrateur pour examiner la question - si elle n‘a pas déjà été prise en compte par l intégrateur par le biais d‘une alerte. Comme le processus de changement a déjà été couvert dans ce billet de blog, nous allons maintenant supposer qu‘une nouvelle itération a été faite avec un commit modifié et une demande de fusion mise à jour, en supprimant l‘instantané de relecture de l‘enregistrement. La sortie du job runChecks est maintenant comme ci-dessous.
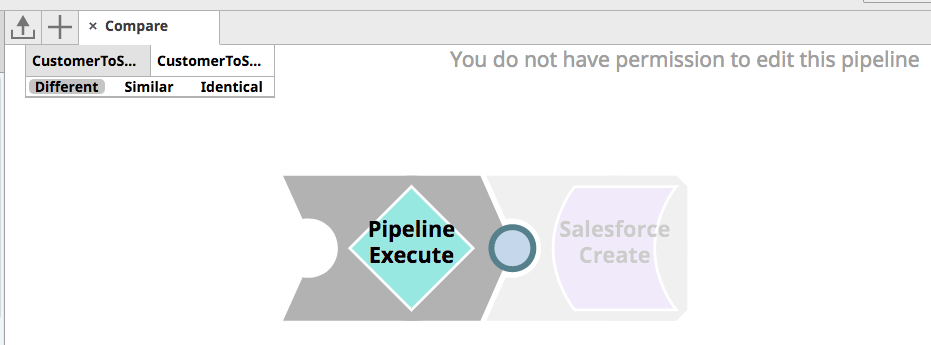
Enfin, l architecte peut examiner les modifications à l‘aide de deux méthodes. Dans la première méthode, il peut examiner les modifications apportées à la structure JSON entre les deux versions du pipeline CustomerToSalesforce, en comprenant quels Snaps et quelles propriétés ont été modifiés. Deuxièmement, il peut utiliser la fonction SnapLogic Compare Pipeline pour obtenir une comparaison visuelle de l‘ancienne et de la nouvelle version du pipeline. Comme le montre l‘image ci-dessous, il peut constater qu‘un Snap d‘exécution de pipeline a été ajouté pour abstraire la logique de transformation et de validation du pipeline lui-même afin de permettre les tests unitaires.
Après avoir examiné les modifications et confirmé que les tests unitaires et les contrôles de qualité ont été effectués avec succès, l‘ l‘architecte approuve les modifications et fusionne la demande de fusion. En conséquence, les derniers changements sont maintenant poussés vers la branche Prod.
Promotion à la production + Ticket Résolu
Dernière étape du scénario ACME de bout en bout, les nouveaux changements de Pipeline fusionnés dans la branche Prod doivent maintenant être automatiquement promus dans la branche SnapLogic Production SnapLogic. Comme mentionné précédemment, le passage direct d‘un environnement de développement à un environnement de production n‘est peut-être pas la meilleure approche, car il est généralement recommandé d‘utiliser un environnement d‘essai, comme un environnement d‘assurance qualité ou de test. Cependant, pour les besoins de cet article de blog, nous passons d‘un environnement de développement à la production directement. Lorsque les changements ont été transférés en productionnous voulons également fermer automatiquement le ticket, en mettant en évidence la façon dont le problème a été résolu. Toutes ces étapes ont été automatisées conformément à l‘accord conclu entre l‘ingénieur ingénieur CI/CD et l‘ingénieur des les opérations.
Si l‘on se réfère au chapitre sur les vérifications des demandes de fusion, le pipeline GitLab comportait une troisième tâche appelée runPromotion. Pour rappel, il fait ce qui suit :
- exécuterPromotion
-
- Ne s‘exécute que pour les modifications de la branche Prod
- La troisième étape, appelée promouvoir
- Exécute le script runPromotion.sh
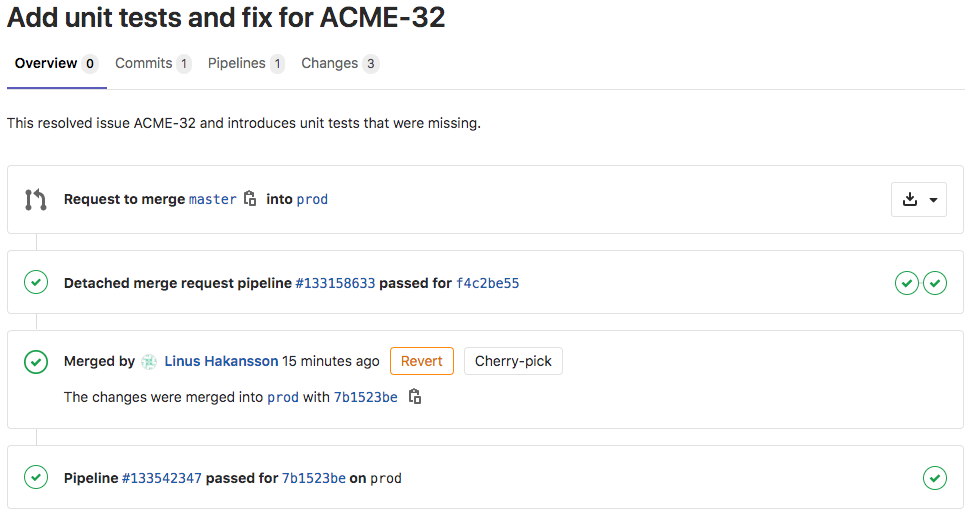
Comme l‘action de fusion de la demande de fusion prise par l Architecte a déplacé les modifications vers la branche Prod, l‘action de fusion exécuterPromotion s‘exécute automatiquement. Lorsqu‘il est exécuté, le flux complet de la demande de fusion se présente comme suit. Les étapes suivantes sont visibles dans l‘image ci-dessous.
- Une demande de déplacement des modifications entre la branche Master et la branche Prod a été créée.
- Un pipeline CI/CD a été mis en place (il s‘agissait d‘exécuter des tests unitaires et des contrôles de qualité).
- La demande a été approuvée et fusionnée par l l‘architecte
- Un autre pipeline CI/CD est passé (c‘est le pipeline de promotion)
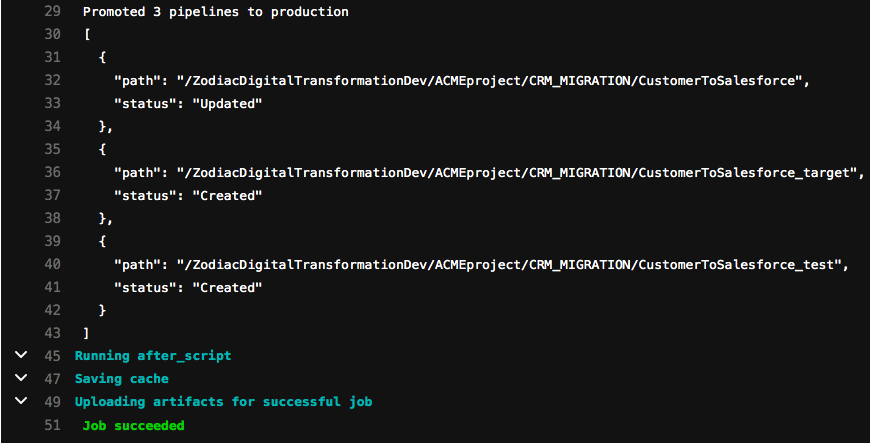
Vérifions la sortie de la tâche de promotion finale qui exécute le script runPromotion.sh. Comme vous pouvez le voir ci-dessous, le job a promu avec succès les 3 pipelines vers le serveur de Production org. L‘un d‘entre eux a été mis à jour tandis que les deux autres n‘existaient pas et ont dû être créés. S‘il s‘agissait d‘un nouvel ensemble de pipelines développés, tous les résultats auraient indiqué Created.
Comment les pipelines sont-ils passés de la phase de développement à la production de production ? Jetons un coup d‘œil au contenu du script runPromotion.sh. Il exécute la tâche RunPromotion Triggered Task et transmet le message de validation de la validation réelle - dans notre cas, ce message de validation inclut le numéro de référence du ticket JIRA.

La tâche RunPromotion Triggered Task invoque le pipeline RunPromotion que l‘on peut voir ci-dessous. Elle effectue les opérations suivantes.
- Lecture de l‘espace courant (ACMEissues) dans l‘espace de développement (où résident les nouveaux pipelines) ainsi que le projet en cours (CRM_MIGRATION)
- Si cet espace et ce projet n‘existent pas dans la production il les crée
- Répertorie tous les pipelines du projet source et appelle le pipeline 01_PromotePipeline pour chaque pipeline, à l‘aide de l‘action d‘exécution du pipeline (intitulée Promote Pipeline).
- Crée une réponse au client si le pipeline 01_PromotePipeline réussit.
- Transpose et met à jour le ticket JIRA correspondant (extrait à l‘aide d‘une expression régulière du message de validation de la validation GitLab).
- Envoi d‘un courriel à Opérations avec le résultat

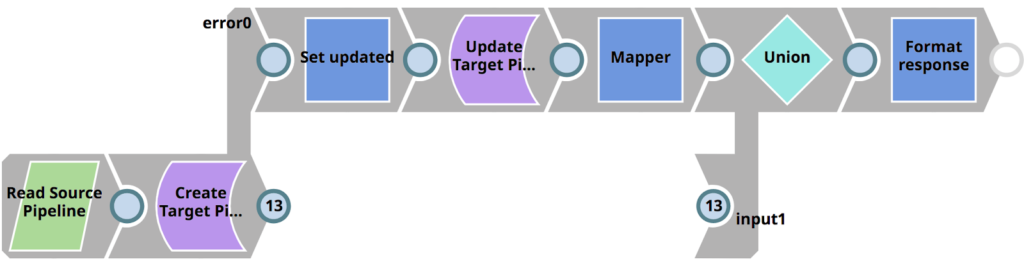
Comme indiqué, pour chaque pipeline trouvé dans le projet source, il appelle 01_PromotePipeline. Ce pipeline est visible ci-dessous et effectue les opérations suivantes
- Lit la ligne de conduite dans le projet source (dans le répertoire de développement de développement)
- Le crée dans le projet cible (dans le projet de production s‘il n‘existe pas
- Ou le met à jour dans le projet cible (dans le projet de production ) s‘il existe
- Formule une réponse au pipeline parent
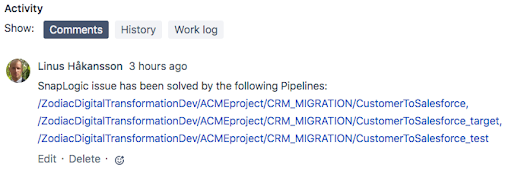
Ainsi, les modifications ont été transférées dans le système de production et le ticket JIRA a été fermé. L‘email ci-dessous a été automatiquement envoyé à l‘équipe des Opérationsavec un lien vers le ticket mis à jour.

Dans le cadre de SnapLogic, le problème a été transféré dans la section Fait un commentaire est automatiquement ajouté au ticket, indiquant quels Pipelines ont été impliqués dans la résolution du problème.
Résumé
Ce billet de blog a montré comment une entreprise ACME fictive et des personas pouvaient utiliser efficacement des outils tiers d‘automatisation, de gestion des versions et de helpdesk pour fournir une gestion de bout en bout du cycle de vie de SnapLogic Pipeline.
Comme il s‘agit d‘un long article, voici les sujets et les processus que nous avons abordés dans cet article de blog.
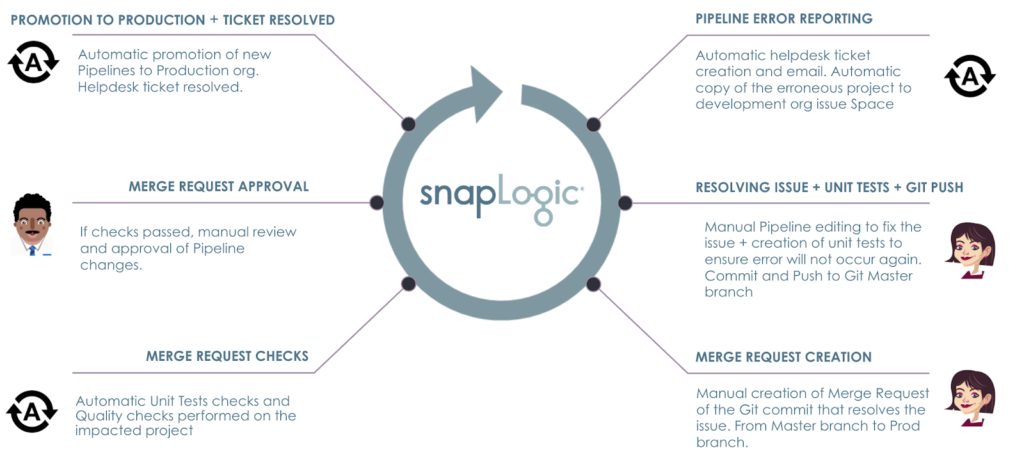
Avec SnapLogic plateforme, vous pouvez
- Capturer automatiquement les erreurs du pipeline de production
- Lancer automatiquement des tickets d‘assistance avec des informations détaillées sur l‘erreur.
- Les intégrateurs et les architectes doivent travailler en collaboration pour contrôler les versions et réviser le travail dans plusieurs environnements SnapLogic.
- Automatiser les tests unitaires et les contrôles de qualité pour respecter les politiques de l‘entreprise.
- Automatiser les migrations et les promotions pour s‘assurer que les bons actifs sont déplacés dans les environnements SnapLogic de l‘entreprise.
- Tirer parti d‘une solution REST et JSON native plateforme permet d‘automatiser et de gérer tous les aspects du cycle de vie.
Les personas, processus, politiques et outils présentés dans ce billet peuvent être facilement modifiés pour répondre aux besoins de n‘importe quelle entreprise. Si votre entreprise n‘a pas encore accès à SnapLogic Intelligent Integration Platform, inscrivez-vous à un essai gratuit gratuitement dès aujourd‘hui !