"Ce n‘est pas l‘ETL de votre père. Ce n‘est pas le bus de messages de votre mère. Ce n‘est pas l‘intégration d‘applications de votre oncle".
- Rich Dill commente la nécessité de penser différemment l‘intégration des applications et des données avec SnapLogic
 Cette semaine, je me suis entretenu avec Rich Dill, l‘un des gourous de l‘intégration de données de SnapLogic, qui a plus de vingt ans d‘expérience dans le domaine de la gestion et de l‘entreposage de données. Rich a parlé du bond en avant en termes de facilité d‘utilisation et d‘habilitation des utilisateurs que permet une intégration plateforme en tant que service (iPaaS). Il a également évoqué les différences de latence lorsqu‘il s‘agit de déplacer des données d‘un site cloud à un autre ou d‘un site cloud à un centre de données, par rapport au déplacement de données d‘une application à un entrepôt de données dans un centre de données.
Cette semaine, je me suis entretenu avec Rich Dill, l‘un des gourous de l‘intégration de données de SnapLogic, qui a plus de vingt ans d‘expérience dans le domaine de la gestion et de l‘entreposage de données. Rich a parlé du bond en avant en termes de facilité d‘utilisation et d‘habilitation des utilisateurs que permet une intégration plateforme en tant que service (iPaaS). Il a également évoqué les différences de latence lorsqu‘il s‘agit de déplacer des données d‘un site cloud à un autre ou d‘un site cloud à un centre de données, par rapport au déplacement de données d‘une application à un entrepôt de données dans un centre de données.
"Lors de l‘utilisation d‘une nouvelle technologie, les gens ont tendance à utiliser les anciennes méthodes. Et sans formation, ils ne sont pas en mesure de tirer parti des caractéristiques et des capacités de la nouvelle technologie. C‘est le vieil adage qui veut que l‘on mette une cheville carrée dans un trou rond.
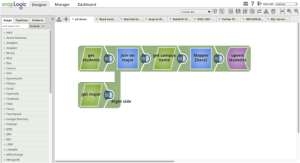
Pour mettre en évidence la puissance de SnapLogic, qui réunit plusieurs styles d‘intégration en un seul site plateforme, Rich a réalisé cette démonstration, dans laquelle il crée un flux de données, appelé pipeline, qui se concentre sur un cas d‘utilisation classique d‘extraction, de transformation et de chargement (ETL), mais qui va beaucoup plus loin. Voici un résumé de SnapLogic consommant, transformant et fournissant des données.
Partie 1 : ETL en tant que service
- Rich sélectionne des données dans deux bases de données, en expliquant comment vous pouvez prévisualiser les données et les visualiser dans plusieurs formats au fur et à mesure qu‘elles circulent dans le site plateforme.
- Il explique comment SnapLogic traite les documents JSON, ce qui permet à plateforme de coupler librement la structure du travail d‘intégration à la cible, puis d‘effectuer des jointures internes et externes avant de formater la sortie et d‘écrire les données jointes dans un File Writer.
- Il revient ensuite en arrière et ajoute une consultation du serveur SQL pour obtenir des informations supplémentaires.
- Il exécute le pipeline et en crée une version.
Partie 2 : Gestion du changement (Vous est-il déjà arrivé qu‘on vous demande d‘ajouter quelques colonnes à une base de données et que vous deviez modifier votre tâche d‘intégration de données ?)
- Il se rend sur place et modifie la table SQL sous-jacente.
- Il ré-exécute le pipeline SnapLogic et montre les nouveaux résultats, sans avoir à faire de changement. Cela met en évidence la flexibilité et l‘adaptabilité de la plate-forme d‘intégration élastique SnapLogic.
Partie 3 : Chargement des données Salesforce
- Il fait appel à Data Mapper Snap pour mettre en correspondance les données avec ce qui se trouve dans Salesforce.
- Il glisse et dépose l‘encart Salesforce Upsert et détermine s‘il doit utiliser l‘API REST ou l‘API Bulk.
- Il utilise SmartLink pour effectuer une recherche floue et mettre en correspondance les champs d‘entrée et de sortie.
- Il passe en revue l‘éditeur d‘expression pour mettre en évidence les types de transformations de données possibles.
- Il montre comment les données sont désormais insérées dans Salesforce et enregistre cette version du pipeline.
Partie 4 : Pipelines RESTful
- Il supprime le Data Mapper Snap parce que la sortie sera différente et il introduit le JSON Formatter.
- Ici, Rich prend une minute pour expliquer que SnapLogic est non seulement un modèle de document faiblement couplé, mais qu‘il est également basé à 100 % sur REST. Cela signifie que chaque pipeline est abstrait et, comme il le dit, "adressable, utilisable, consommable, déclenchable, programmable comme un appel REST".
- Il se rend dans Manager > Tâches et crée une nouvelle tâche qu‘il définit comme étant un déclencheur.
- Il exécute la tâche pour démontrer que, lors de l‘appel du pipeline basé sur REST, il peut montrer comment un appareil mobile peut effectuer un REST Get pour apporter les données à un appareil mobile.
- Il termine la démonstration en changeant le pipeline pour passer d‘un document JSON à un document XML.
J‘ai intégré la vidéo ci-dessous. N‘oubliez pas de consulter notre centre de ressources pour obtenir d‘autres informations sur l‘intégration élastique de SnapLogic plateforme. Merci pour cette excellente démonstration, Rich !