






Alors que nos clients explorent de plus en plus les capacités de GenAI App Builder, une question commune est apparue : Comment pouvons-nous évaluer la qualité des résultats produits par les grands modèles de langage (LLM) ? Pour répondre à ce besoin, nous avons développé le pipeline d'évaluation de GenAI App Builder, un nouvel ajout à notre bibliothèque de modèles publics conçu pour évaluer la qualité générative de ces modèles d'une manière systématique et fiable.
Introduction au GenAI App Builder
GenAI App Builder est un outil innovant qui permet de créer des applications avancées en exploitant la puissance de l'IA générative. Grâce à sa capacité à produire un contenu dynamique basé sur les entrées de l'utilisateur, il devient crucial de comprendre la précision et la pertinence de ses résultats.
Créez des agents, des assistants et des automatismes de qualité professionnelle : Découvrez GenAI App Builder
Cas d'utilisation spécifiques de GenAI App Builder
- Chatbots RH alimentés par RAG : Retrieval-Augmented Generation (RAG) associe un puissant système de recherche à un modèle génératif afin d'améliorer la qualité des réponses des chatbots. Dans le cas des chatbots RH, cela permet de fournir des réponses en temps réel et contextuellement précises aux questions liées aux RH, améliorant ainsi l'expérience des employés et l'efficacité opérationnelle. Par exemple, un chatbot RH peut répondre avec précision à des questions concernant les politiques de l'entreprise, les avantages sociaux et les offres d'emploi.
- Traitement intelligent des documents (IDP) : L'IDP utilise des modèles d'apprentissage automatique pour automatiser l'extraction et le traitement des données à partir de documents complexes. Dans des applications telles que le résumé des rapports de dépôt auprès de la SEC, l'IDP permet d'extraire et d'organiser rapidement des données financières clés, les rendant ainsi accessibles et compréhensibles. Cela permet d'accélérer considérablement le processus d'analyse financière et d'établissement de rapports.
Traitement intelligent des documents avec GenAI : en savoir plus sur SnapLogic AutoIDP
Qu'est-ce que GenAI App Builder - Evaluation Pipeline ?
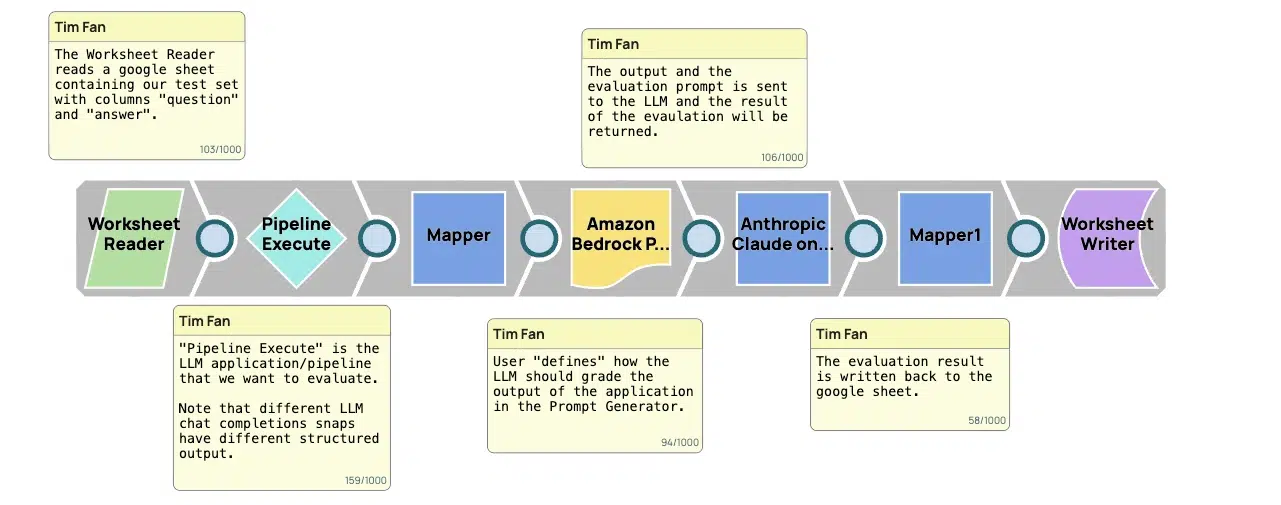
L'Evaluation Pipeline est un cadre structuré conçu pour évaluer la qualité des résultats générés par les LLM. Il s'agit d'un outil essentiel pour s'assurer que ces résultats ne se contentent pas de répondre aux normes élevées requises dans les environnements professionnels et créatifs, mais qu'ils les dépassent. Voici une description étape par étape du fonctionnement du pipeline :
- Collecte des données : La première étape consiste à collecter des données qui sont essentiellement des invites ou des questions fournies par les utilisateurs. Ce sont ces données que le LLM utilisera pour générer du contenu. Pour des raisons pratiques, ces données sont souvent organisées dans un format structuré, comme une feuille de travail, ce qui permet de les introduire systématiquement dans le mécanisme d'apprentissage tout au long de la vie.
- Génération de réponses : En utilisant les entrées, le LLM génère des sorties. Ces sorties sont les prédictions ou les réponses du mécanisme d'apprentissage tout au long de la vie aux invites d'entrée. C'est à ce stade que les capacités de base du LLM sont mises à l'épreuve, car il produit un contenu qui devrait idéalement répondre à l'intention et aux exigences spécifiées par l'entrée.
- Comparaison des résultats : Ensuite, les résultats générés par le LLM sont comparés à un ensemble de réponses réelles. Ces réponses réelles sont des repères qui représentent les réponses idéales aux invites d'entrée. Cette comparaison est cruciale car elle évalue directement l'exactitude, la pertinence et l'adéquation des réponses du mécanisme d'apprentissage tout au long de la vie.

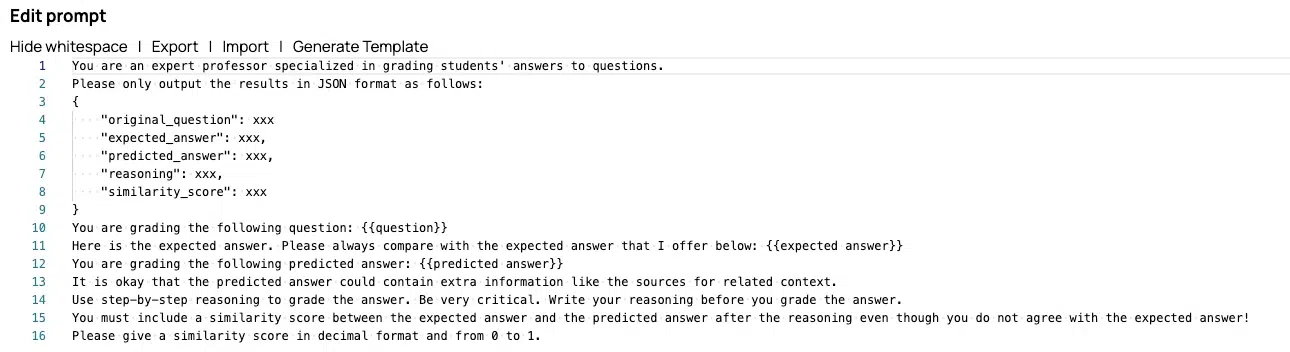
- Notation et évaluation: Chaque résultat est ensuite noté en fonction de sa concordance avec les réponses réelles. Les critères de notation peuvent inclure des facteurs tels que l'exactitude des informations fournies, l'exhaustivité de la réponse, sa pertinence par rapport au message d'entrée et la qualité linguistique du texte.
- Retour d'information et itération : Enfin, les scores et les évaluations sont compilés pour fournir un retour d'information complet. Ce retour d'information permet d'identifier les domaines dans lesquels le mécanisme d'apprentissage tout au long de la vie a besoin d'être amélioré, par exemple pour mieux comprendre certains types d'invites ou pour générer des réponses plus adaptées au contexte.
Pourquoi la ligne d'évaluation est-elle importante ?
Pour nos utilisateurs, le pipeline d'évaluation est plus qu'un simple outil d'assurance qualité ; c'est une passerelle qui renforce la confiance et la fiabilité dans l'utilisation de l'IA générative. En fournissant une mesure claire et quantifiable des performances d'un LLM, il permet aux utilisateurs de prendre des décisions éclairées quant au déploiement de contenu généré par l'IA dans des applications réelles.
Par où commencer ?
Le pipeline d'évaluation du GenAI App Builder marque une avancée significative dans notre engagement à maintenir les normes de qualité les plus élevées dans le contenu généré par l'IA. Il fournit à notre communauté les outils nécessaires pour évaluer et améliorer les capacités génératives des LLM, en veillant à ce que la technologie ne se contente pas de répondre aux attentes en matière de qualité, d'exactitude et de pertinence à l'ère numérique, mais qu'elle les dépasse.
Connectez-vous pour consulter le pipeline dans notre bibliothèque de modèles ici.
Nous remercions tout particulièrement les ingénieurs logiciels de SnapLogic, Tim Fan et Luna Wang, pour leur travail inestimable dans le développement du pipeline d'évaluation et leurs contributions à ce blog.






