






Snowpark est un ensemble de bibliothèques et de moteurs d‘exécution dans la base de données Snowflake cloud plateforme qui permet aux développeurs de traiter en toute sécurité du code Python, Java ou Scala non SQL, sans mouvement de données dans le moteur de traitement élastique de Snowflake.
Cela permet d‘interroger et de traiter les données, à grande échelle, dans Snowflake. Les opérations de Snowpark peuvent être exécutées passivement sur le serveur, ce qui réduit les coûts de gestion et garantit des performances fiables.
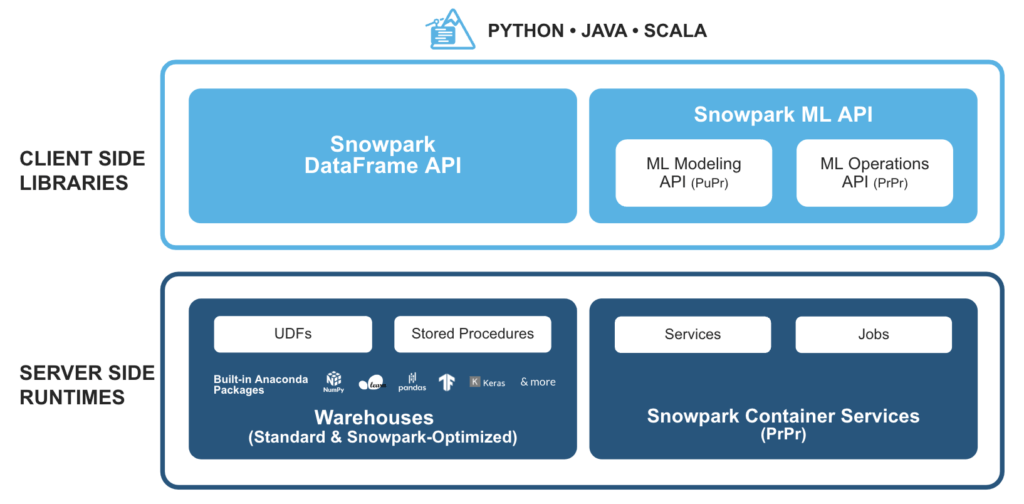
Comment Snowpark fonctionne-t-il avec SnapLogic ?
La plateforme d‘intégration intelligente (IIP) de SnapLogic permet d‘exploiter facilement les fonctions personnalisées définies par l‘utilisateur (UDF) pour Snowpark. En outre, le Snowflake Snap Pack est utilisé pour mettre en œuvre des cas d‘utilisation avancés d‘apprentissage automatique et d‘ingénierie des données avec Snowflake.
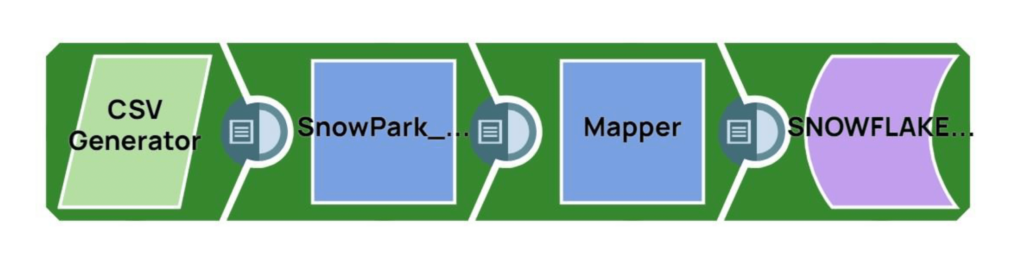
Exemple d‘intégration entre Snowpark et SnapLogic
Examinons les étapes pour invoquer les bibliothèques Snowpark en utilisant le Remote Python Script Snap dans SnapLogic :
Étape 1 : Lecture d‘un échantillon de lignes à partir d‘une source (un générateur CSV dans ce cas)
Étape 2 : Utilisez le script Python à distance pour :
- Invoquer les bibliothèques Python de Snowpark
- Effectuer des opérations supplémentaires sur les lignes de données source
Étape 3 : Charger les données traitées dans une table Snowflake cible
Configurations SnapLogic IIP
Du côté de SnapLogic, le Remote Python Executor (RPE) devra être installé en suivant les étapes suivantes :
Etapes 1 et 2: Les deux premières étapes de l‘installation du RPE sont expliquées en détail dans la documentation SnapLogic IIP. Le port d‘accès par défaut du RPE est le 5301, la "communication entrante" doit donc être activée sur ce port.
- Si l‘instance Snaplex est un Groundplex, le RPE peut être installé sur le même nœud Snaplex.
- Si l‘instance Snaplex est un Cloudplex, le RPE peut être installé comme n‘importe quel autre nœud distant accessible par le Snaplex.
Étape 3 : L‘étape suivante consiste à installer le paquetage RPE personnalisé en suivant les étapes de la section "image personnalisée" de la documentation. Pour installer les bibliothèques Snowpark sur le nœud, mettez à jour le fichier requirements.txt comme suit :
exigences.txtsnaplogicnumpy==1.22.1snowflake-snowpark-pythonsnowflake-snowpark-python[pandas]
L‘instance Snaplex dans notre exemple est un Cloudplex, et le nœud distant est une VM Ubuntu Azure. Le paquetage RPE personnalisé est installé sur la VM Azure.
Configurations des flocons de neige
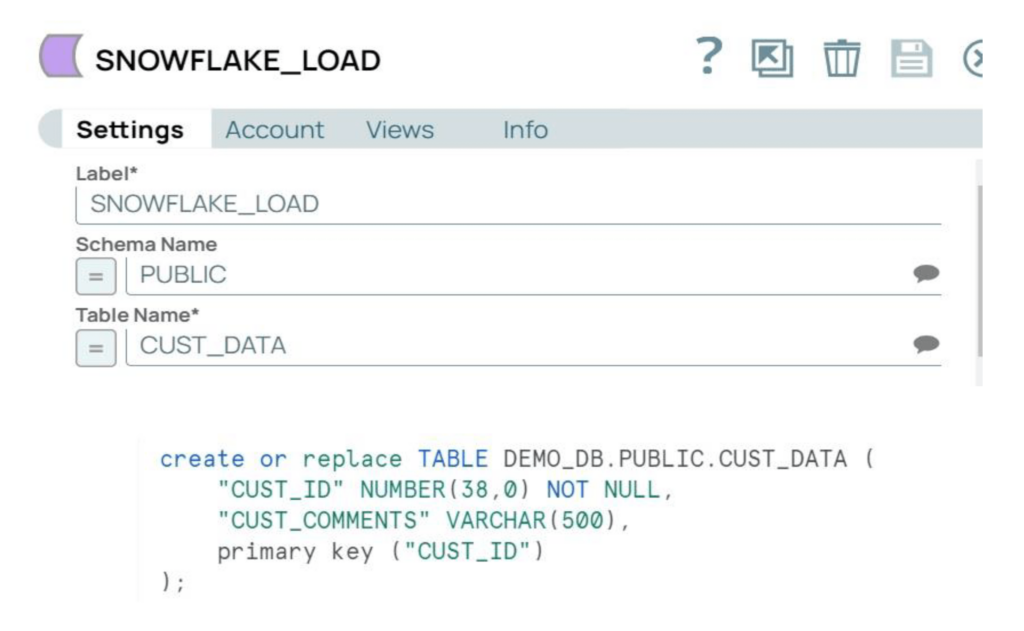
Du côté de Snowflake, nous devons définir les configurations et créer une table cible.
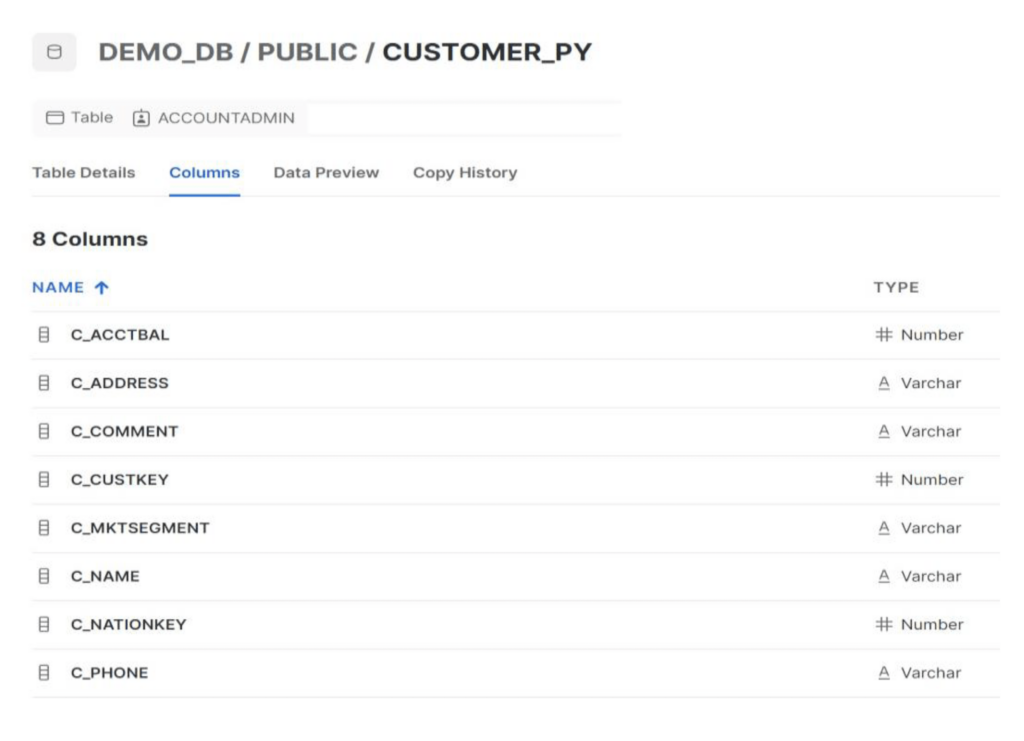
Etape 1 : Mettre à jour les "network policies" de Snowflake pour autoriser les nœuds SnapLogic et RPE. Pour cet exemple, nous utiliserons la table CUSTOMER_PY sous le schéma Public.
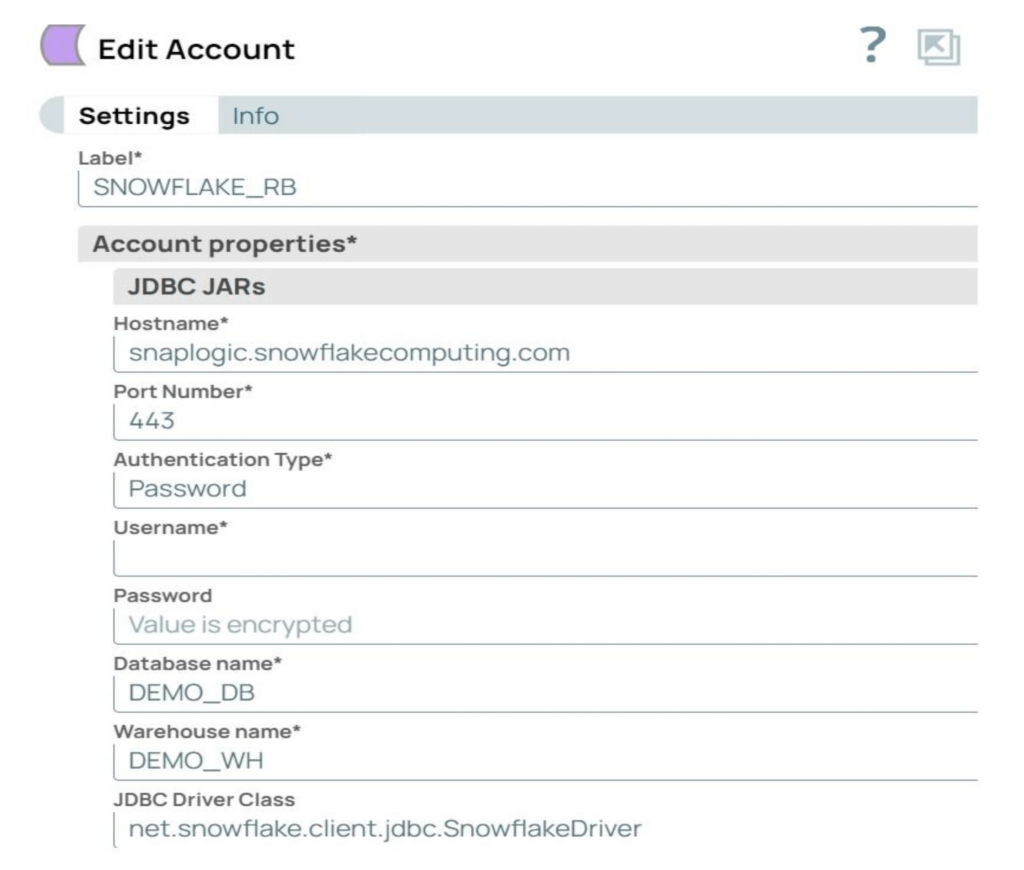
Etape 2 : Créer le compte Snowflake dans SnapLogic avec les paramètres requis. Le compte utilisé dans notre exemple est un compte Snowflake S3 Database.
Flux du pipeline SnapLogic (Remote_Python_Snowpark_Sample)
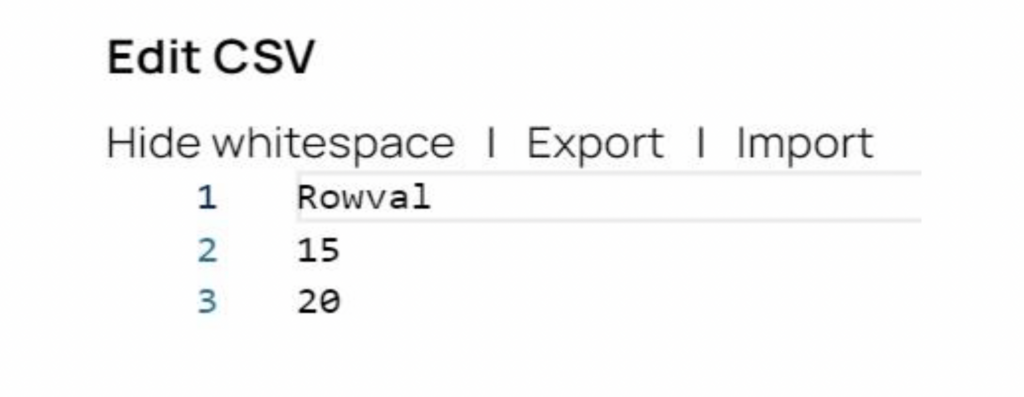
Étape 1 : Le générateur CSV Snap génère les données sources. Dans notre exemple, il y a deux enregistrements source, avec des valeurs de 15 et 20.
Etape 2 : Le Remote Python Script Snapexécute le code Python pour appeler les bibliothèques Python de Snowpark et effectuer des opérations supplémentaires sur les lignes de données source. Voir l‘extrait du code Python ci-dessous :

Le code Python effectue les opérations suivantes :
- Construire des DataFrames Snowpark pour récupérer les données des tables Snowflake. Filtrer les enregistrements pour récupérer les données de la colonne C_NATIONKEY et de la colonne C_COMMENT associée pour chaque ligne d‘entrée de l‘instantané en amont (à partir du générateur CSV).
- Créez et exécutez un UDF pour ajouter l‘horodatage actuel aux enregistrements liés dans la colonne C_COMMENT. Le nom de l‘exemple d‘UDF est append_data.
- Renvoyer les valeurs de C_NATIONKEY et les enregistrements C_COMMENT mis à jour à l‘application de mappage en aval.
Étape 3 : Valider le pipeline SnapLogic et résoudre les éventuelles erreurs de validation.
Étape 4 : Exécuter le pipeline et vérifier les données dans la base de données cible sur Snowflake.
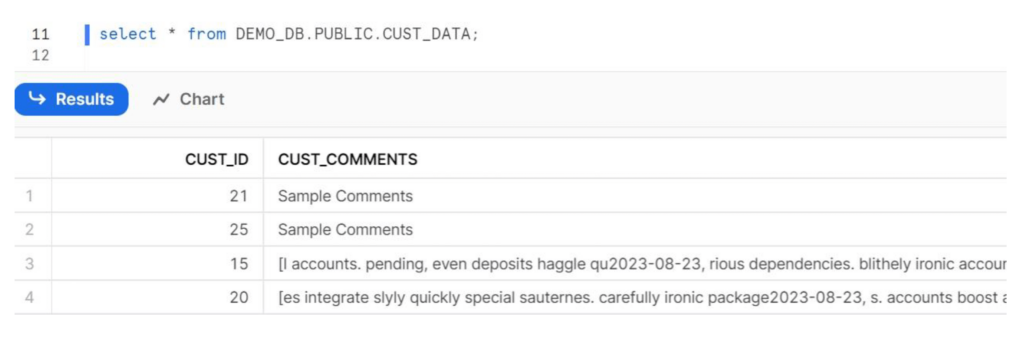
Étape 5 : Félicitations, vous avez réussi à intégrer Snowpark et SnapLogic !
Références supplémentaires
Documentation de l‘API Snowpark
Guide du développeur Snowpark pour Python
SnapLogic Remote Python Script Documentation Snap
Exportation de SnapLogic Pipeline
Code Python pour le Remote Python Script Snap






