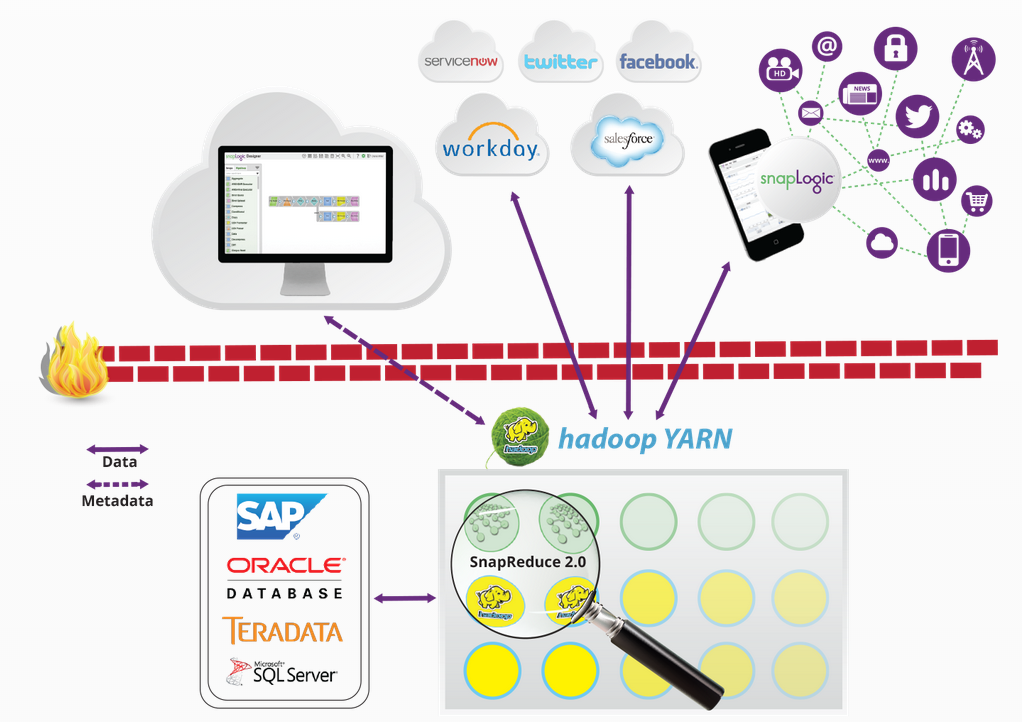
Cette semaine, SnapLogic a annoncé SnapReduce 2.0opens in new tab, qui permet à la plateforme d‘intégration élastique SnapLogic en tant que service(iPaaS)opens in new tab de fonctionner nativement sur Hadoop en tant que ressource gérée par YARN qui évolue de manière élastique et facilite l‘acquisition, la préparation et la fourniture de données volumineuses. J‘ai rencontré Greg Benson, professeur d‘informatique à l‘université de San Francisco et directeur scientifique de SnapLogic. Greg travaille depuis 20 ans sur la recherche en matière de systèmes distribués, de programmation parallèle, de noyaux de systèmes d‘exploitation et de langages de programmation. Son équipe est à l‘origine de l‘innovation de SnapLogic en matière d‘intégration des big data. Voici ce qu‘il a à dire sur SnapReduce 2.0, YARN et l‘opportunité pour les clients de bénéficier de l‘intégration définie par logiciel de SnapLogic plateforme:
Qu‘est-ce que SnapReduce ?
SnapReduce 1.0opens in new tab a exploité Hadoop en transformant les pipelines SnapLogic en Jobs Hadoop MapReduce. Ces pipelines transformés pouvaient travailler strictement sur des données Hadoop existantes. Bien que puissante, cette technologie ne permettait pas à SnapLogic d‘offrir une connectivité complète à Hadoop. Désormais, avec YARN, SnapLogic peut fonctionner au sein d‘Hadoop et permettre à n‘importe quel pipeline SnapLogic de fonctionner au sein d‘un cluster Hadoop.
SnapReduce 2.0 tire parti de votre investissement dans Hadoop en vous permettant de multiplexer vos ressources Hadoop pour des tâches d‘intégration en plus de vos autres applications Hadoop. Les tâches d‘intégration peuvent désormais s‘adapter à la capacité de votre cluster Hadoop en fonction des besoins. En outre, SnapReduce 2.0 facilite l‘acquisition et la fourniture de données Hadoop à l‘aide d‘un concepteur graphiqueopens in new tab et d‘une connectivité Snapopens in new tab à un large éventail d‘applications et de magasins de données.
Qu‘est-ce qui rend SnapReduce 2.0 unique ?
SnapReduce 2.0opens in new tab est unique parce qu‘il est à la fois compatible avec YARN et connecté à l‘iPaaS élastique de SnapLogic. Vous bénéficiez de tous les avantages d‘Hadoop en termes d‘utilisation des ressources et d‘échelle, tout en bénéficiant de l‘absence de maintenance d‘un service cloud . En outre, la prise en charge native des documents hiérarchiques est fondamentale pour SnapLogic. Ce support natif peut être utilisé pour créer facilement des fichiers de données JSONopens in new tab dans HDFS ainsi que des enregistrements orientés ligne selon les besoins.
Quels problèmes SnapReduce 2.0 résout-il ?
Nous voyons des clients qui veulent commencer à déplacer leur entrepôt de données et leur stockage à long terme vers Hadoop pour son avantage en termes de coût par rapport aux produits de stockage propriétaires. En outre, les clients commencent à repenser l‘analyseopens in new tab en termes d‘Hadoop et veulent connecter autant de données que possible à leur hub de données d‘entreprise. Les clients considèrent cette évolution comme une opportunité de s‘affranchir de leurs anciennes contraintes ETL et de passer à une solution moderne plateformeopens in new tab qui englobe à la fois le site cloud et les données volumineuses.
Actuellement, les approches courantes pour intégrer des données dans Hadoop se limitent à Flume pour les données de journal, à Scoop pour les données relationnelles et à des applications personnalisées pour d‘autres types de données. Désormais, tout ce à quoi SnapLogic peut se connecter devient une source de données pour Hadoop, par exemple les fichiers journaux, les données relationnelles, les applications sur site et les applications cloud . De même, ces sources de données deviennent facilement des destinations de données. Nous rendons les big data élastiques en fournissant une acquisition et une livraison flexibles des données afin qu‘elles ne soient plus cloisonnées par des outils de développement difficiles à configurer et à utiliser.
Quand SnapReduce 2.0 sera-t-il disponible ?
Comme nous l‘avons indiqué dans le communiqué de presseopens in new tab, la disponibilité est prévue dans les prochaines semaines. Nous travaillons actuellement avec les principaux partenaires de distribution Hadoop sur les certifications et nous avons lancé un programme d‘accès anticipé pour certains de nos clients existants et prospects ayant des projets big data actifs. Vous pouvez en savoir plus sur SnapReduce 2.0 et vous inscrire au programme sur le site Web de SnapLogicopens in new tab.
C‘est une bonne chose. Merci pour cette mise à jour, Greg. Nous sommes impatients d‘en savoir plus sur cette initiative et sur d‘autres initiatives d‘intégration des big dataopens in new tab qui seront bientôt lancées par votre équipe !
Prochaines étapes :
- En savoir plus sur SnapReduce 2.0opens in new tab
- Télécharger le kit d‘intégration de données Elasticopens in new tab
- Découvrez comment nous optimisons les analysesopens in new tab basées sur Amazon Redshift cloudopens in new tab.
- Regarder une vidéo sur SnapTVopens in new tab
- Contactez-nous opens in new tabpour discuter de vos besoins en matière d‘intégration de cloud et de big data.