À l‘heure actuelle, nous connaissons tous l‘augmentation du volume de données générées et disponibles pour une organisation, ainsi que les problèmes qu‘elle peut engendrer, et nous en faisons l‘expérience. On peut constater qu‘il n‘y a guère de fin en vue au tsunami de données qui est en grande partie dû à la variété accrue de données provenant de sources mobiles, de médias sociaux et de l‘IdO.
Il n‘est donc pas surprenant que les organisations se retrouvent noyées sous les données. Une étude récente du cabinet d‘études de marché indépendant Vanson Bourne a révélé que jusqu‘à 80 % des personnes interrogées pensent que les technologies existantes empêchent leur organisation de tirer parti des opportunités offertes par les données. La même étude indique également que seulement 50 % des données collectées sont analysées pour en tirer des informations commerciales. Si l‘on ajoute à cela le fait que les organisations ont besoin d‘informations sur les données à un rythme de plus en plus rapide, on obtient une recette pour un désastre ou, au mieux, une perte potentielle de revenus.
Pour collecter et analyser les données afin d‘obtenir des informations commerciales cachées et adopter véritablement une culture axée sur les données, les organisations ont besoin d‘outils permettant aux ingénieurs de données et aux utilisateurs professionnels ayant des connaissances dans le domaine d‘opérer plus efficacement dans cet environnement sans avoir à posséder des compétences techniques approfondies.
L‘essor des technologies du big data
Pour collecter et analyser tous les types de données, les organisations continuent d‘adopter les technologies big data et construisent de plus en plus de lacs de données basés sur le site cloud. Cela leur permet de profiter des avantages offerts par le site cloud , tels qu‘une réduction significative des dépenses d‘investissement.
Cependant, l‘exploitation de l‘environnement big data est souvent difficile car des compétences spécialisées sont nécessaires pour l‘installer, le configurer et le maintenir. Une fois que l‘environnement est en place et que les employés sont prêts à se lancer dans leur projet, ils auront besoin de développeurs Spark pour écrire le code nécessaire à l‘exécution des tâches d‘ingénierie des données. Ensuite, ils devront développer un mécanisme de soumission des tâches du pipeline Spark au cluster de traitement. Une fois que cela est fait et que les employés veulent profiter de la capacité transitoire qu‘offrent les clusters Big Data as a Service (BDaaS), ils devront développer leur gestion du cycle de vie.
Tout cela nécessite des centaines, voire des milliers, de lignes de code qui sont complexes, sujettes aux erreurs et dont l‘écriture prend généralement des mois. En même temps, les développeurs Spark sont très demandés et il y a une énorme pénurie de talents dans ce domaine.
Quand le big data rencontre l‘eXtreme
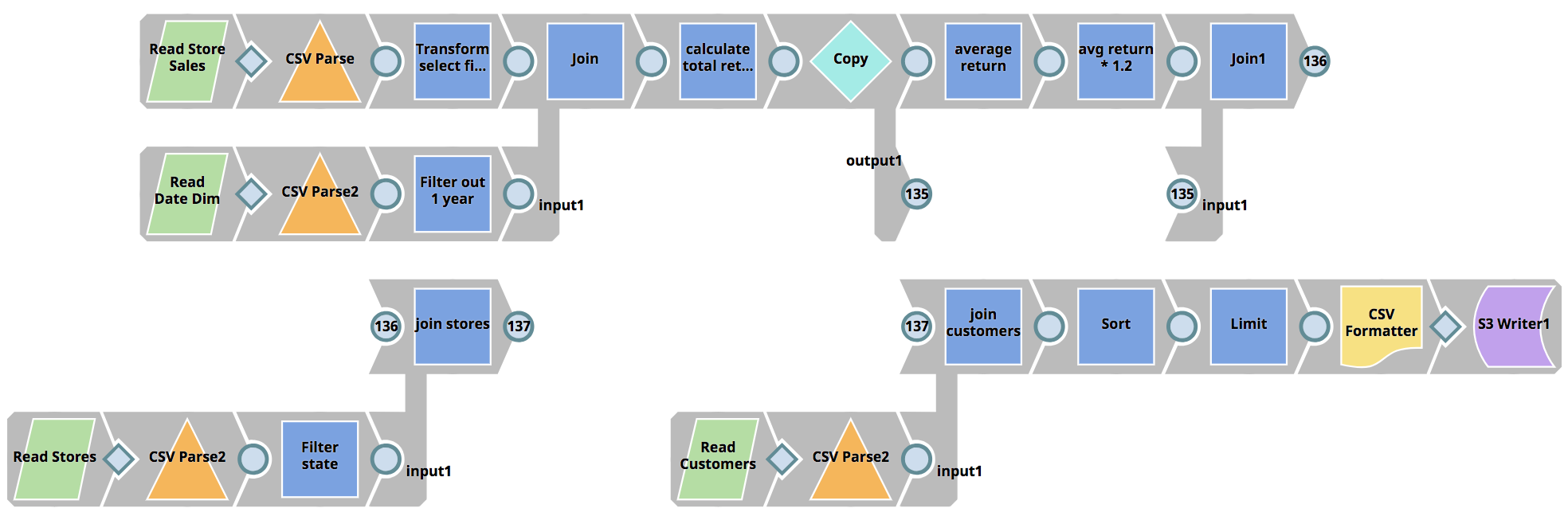
SnapLogic eXtreme répond à la pénurie de talents en ingénierie des données en améliorant l‘Enterprise Integration Cloud et son paradigme de conception visuelle permettant aux organisations de construire des pipelines Spark sans avoir besoin d‘écrire des jobs Spark en Scala, Python ou Java, réduisant ainsi considérablement l‘ensemble des compétences requises. Un projet qui nécessiterait normalement plusieurs développeurs et plusieurs mois peut être réduit à quelques heures seulement.
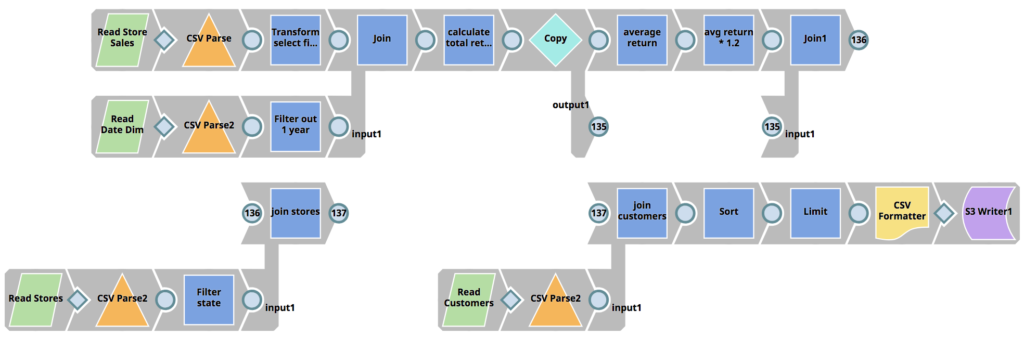
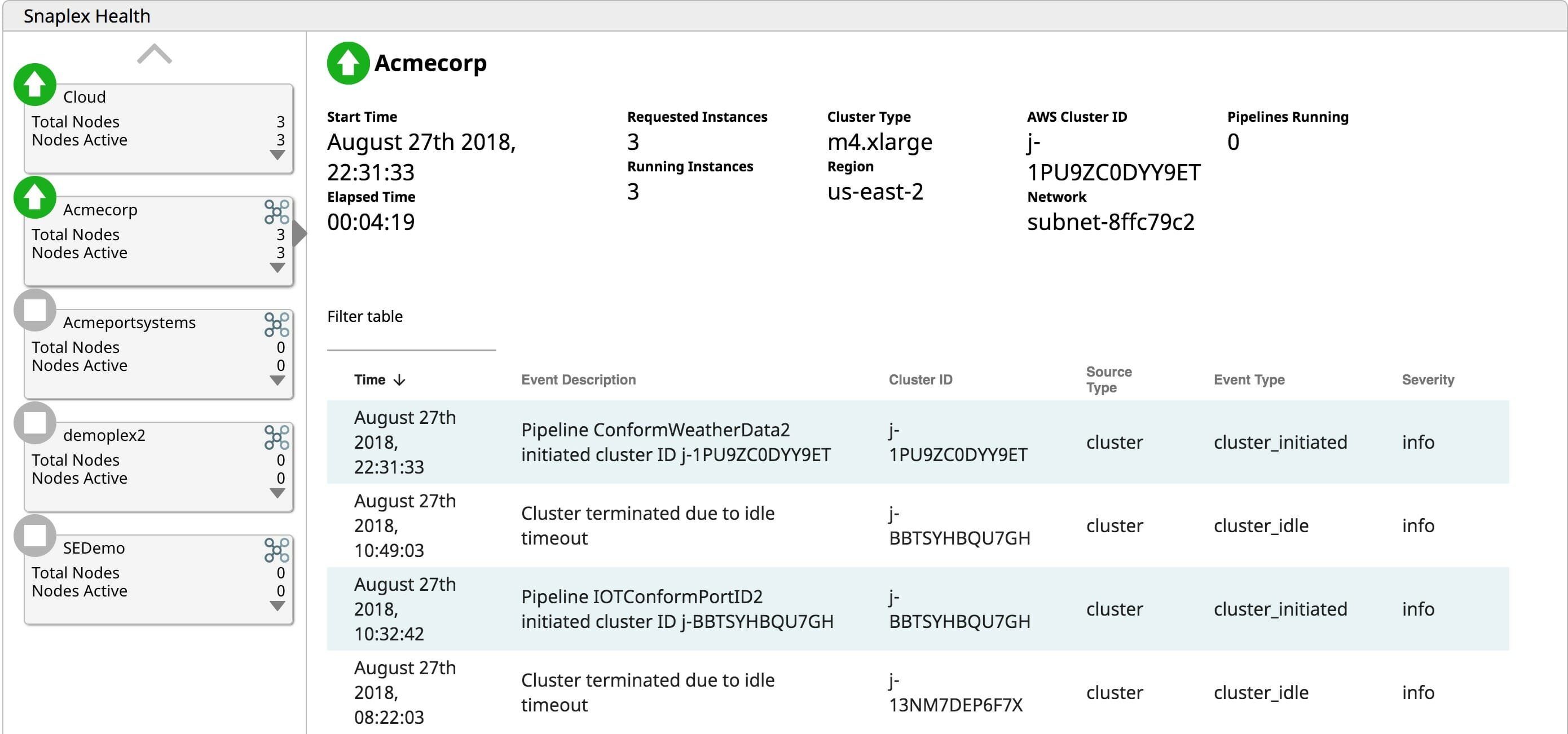
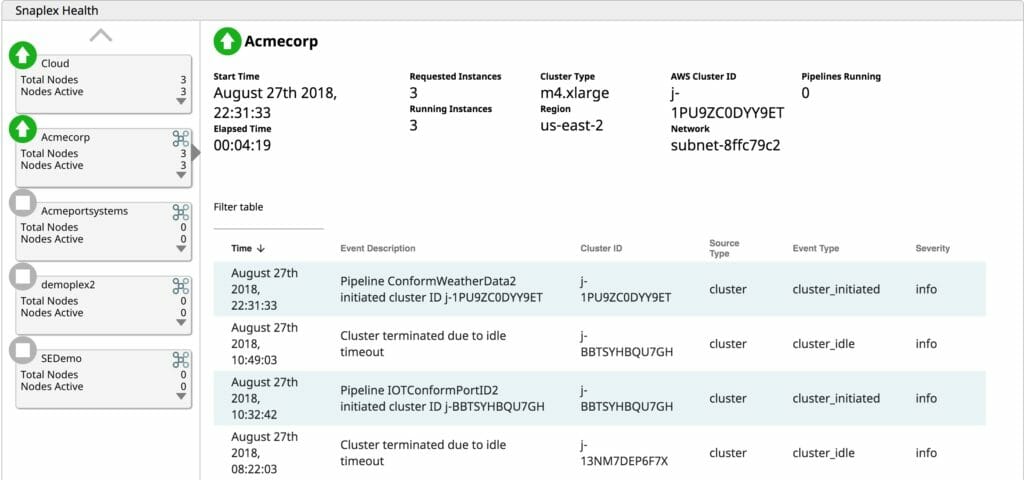
Grâce à la capacité de gestion du cycle de vie de SnapLogic eXtreme, les utilisateurs peuvent activer des clusters à la demande lorsque le traitement est nécessaire. Si aucun travail n‘a besoin d‘être exécuté, payer pour un cluster inactif n‘est qu‘un gaspillage d‘OpEx. SnapLogic eXtreme fait évoluer les clusters de manière élastique en fonction des besoins, à mesure que le traitement augmente. Grâce à cette capacité de mise à l‘échelle élastique, il n‘est plus nécessaire de dimensionner les clusters en fonction des pics de charge. L‘augmentation de la capacité de traitement en fonction des besoins permet aux entreprises de ne payer que pour ce qu‘elles utilisent, évitant ainsi de gaspiller de l‘OpEx sur des serveurs inactifs. Enfin, eXtreme arrête le cluster en cours d‘exécution lorsqu‘il n‘y a plus de tâches en attente à traiter. Pourquoi payer pour faire fonctionner des serveurs qui n‘apportent aucune valeur ajoutée à l‘entreprise ? La fourniture d‘un environnement d‘exécution big data entièrement géré et automatisé, basé sur cloud, permet aux entreprises d‘économiser de précieuses dépenses d‘exploitation.
Les initiatives en matière de big data reçoivent de l‘aide
Les fonctionnalités d‘eXtreme apportent rapidité et agilité à une organisation. SnapLogic eXtreme permet aux organisations d‘en faire plus avec moins de ressources grâce à l‘utilisation de son interface de conception visuelle. Les capacités de libre-service permettent aux utilisateurs techniques de lancer des initiatives plus rapidement sur le marché et d‘obtenir rapidement des informations significatives, ce qui est essentiel dans l‘environnement rapide d‘aujourd‘hui. Après tout, Forrester prédit que "d‘ici 2021, les entreprises guidées par la connaissance voleront 1,8 trillion de dollars de revenus par an à leurs concurrents qui ne le sont pas".
L‘augmentation continue du volume et de la variété des données et leur analyse pour en tirer des informations commerciales cachées ne montrent aucun signe de ralentissement. Si les technologies big data fournissent les bons outils pour le travail, elles offrent un environnement opérationnel difficile qui nécessite un ensemble de compétences spécialisées et difficiles à trouver pour réussir. SnapLogic eXtreme permet de réduire le temps, les ressources et l‘expertise nécessaires à la création et à l‘exploitation d‘architectures big data sur le site cloud. Si votre entreprise a des difficultés avec son initiative big data, découvrez SnapLogic eXtreme.