Dans ce dernier billet de la série consacrée au livre blanc de Mark Madsen, Will Data Lake Drown Data Warehouse ? Will the Data Lake Drown the Data Warehouse, je résume le rôle de SnapLogic dans le lac de données de l‘entreprise.
SnapLogic est la seule intégration unifiée de données et d‘applications plateforme en tant que service(iPaaS). La plateforme d‘intégration élastique SnapLogic dispose de plus de 350 connecteurs intelligents préconstruits - appelés Snaps - pour tout connecter, d‘AWS Redshift à Zuora, et d‘une architecture de flux qui prend en charge les exigences d‘intégration d‘entreprise en temps réel, basées sur les événements et à faible latence, ainsi que le volume élevé, la variété et la vélocité de l‘intégration des big data dans la même interface conviviale et en libre-service.
L‘architecture distribuée et orientée web de SnapLogic s‘adapte naturellement à la consommation et au déplacement de grands ensembles de données résidant dans les locaux, sur le site cloud, ou les deux, et à leur acheminement vers et depuis le lac de données. La plate-forme d‘intégration élastique SnapLogic fournit un grand nombre des services de base d‘un lac de données, notamment la gestion des flux de travail, le flux de données, le mouvement des données et les métadonnées.
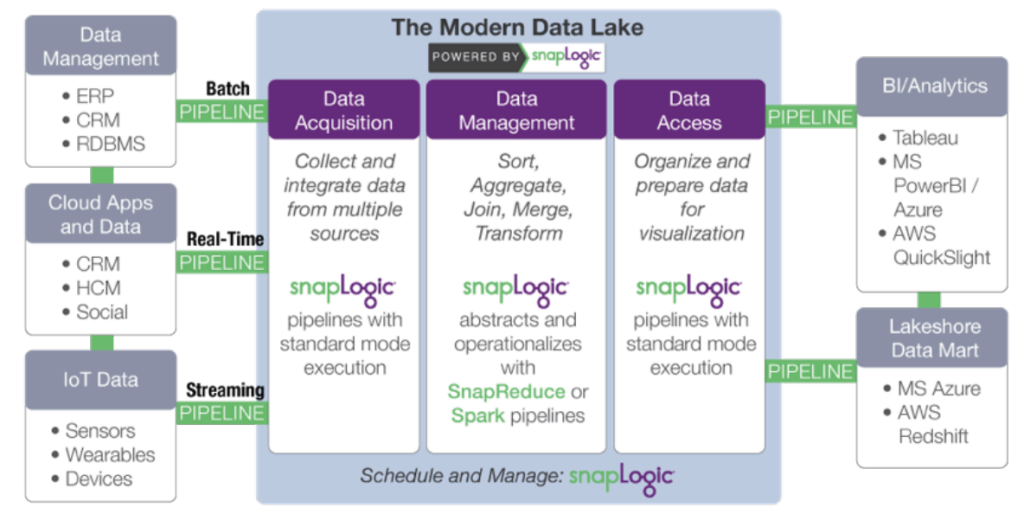
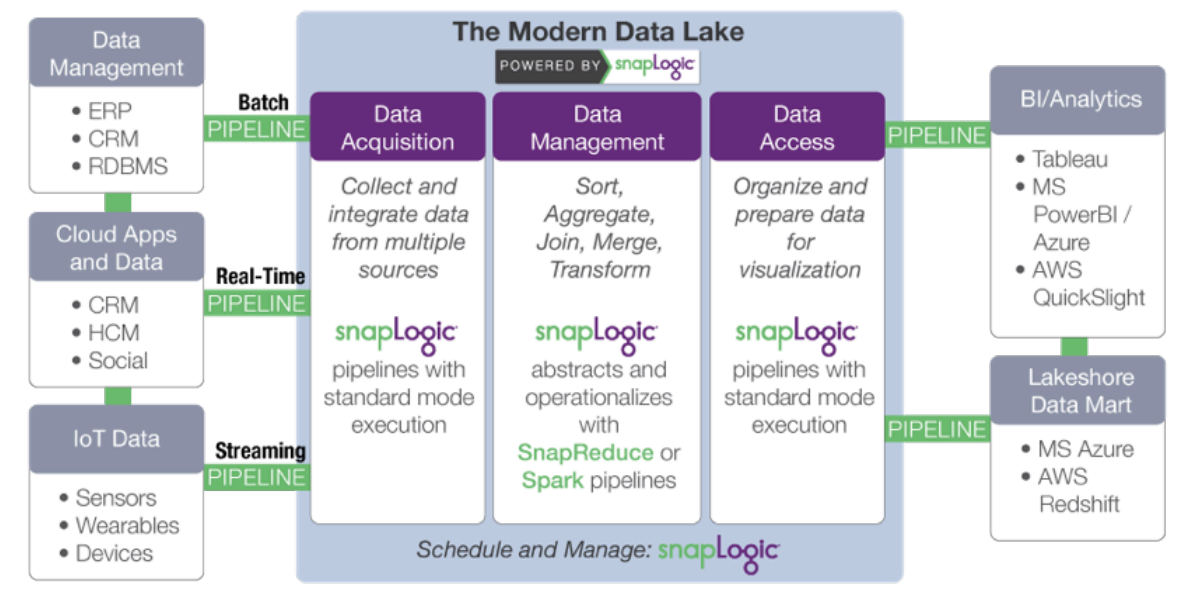
Plus précisément, SnapLogic accélère le développement d‘un lac de données moderne grâce à :
- Acquisition de données : collecte et intégration de données provenant de sources multiples. SnapLogic va plus loin que les outils de développement tels que Sqoop et Flume grâce à un concepteur visuel de pipeline basé sur cloud et à des connecteurs prédéfinis pour plus de 350 sources de données structurées et non structurées, applications d‘entreprise et API.
- Transformation des données : ajout d‘informations et transformation des données. Réduire les tâches manuelles associées à la
la mise en forme des données et rend les data scientists et les analystes plus efficaces. SnapLogic inclut des Snaps pour des tâches telles que les transformations, les jointures et les unions sans script. - Accès aux données : organisation et préparation des données en vue de leur diffusion et de leur visualisation. Rendre les données traitées sur Hadoop
ou Spark soient facilement accessibles aux applications hors cluster et aux magasins de données, tels que les progiciels statistiques et les outils de veille stratégique.
L‘approche agnostique de SnapLogic ( plateforme) dissocie la spécification du traitement des données de l‘exécution. Lorsque les exigences en matière de volume de données ou de temps de latence changent, le même pipeline peut être utilisé en changeant simplement les données cibles plateforme. SnapReduce de SnapLogic permet à SnapLogic de fonctionner en mode natif sur Hadoop en tant que ressource gérée par YARN qui évolue de manière élastique pour alimenter l‘analyse des big data, tandis que Spark Snap aide les utilisateurs à créer des pipelines de données basés sur Spark, idéalement adaptés aux processus itératifs à forte intensité de mémoire. Qu‘il s‘agisse de MapReduce, de Spark ou d‘un autre cadre de traitement des big data, SnapLogic permet aux clients de s‘adapter à l‘évolution des besoins en matière de lac de données, sans s‘enfermer dans un cadre spécifique.
Nous l‘appelons "Hadoop pour les humains ".
Prochaines étapes :
- Télécharger le livre blanc : Comment construire un lac de données d‘entreprise : Considérations importantes avant de se lancer. Vous pouvez également regarder l‘enregistrement webinar et consulter les diapositives sur le blog de SnapLogic.
- Télécharger le livre blanc : Le lac de données va-t-il noyer l‘entrepôt de données ?
- Regardez cette démonstration de SnapReduce et de SnapLogic Hadooplex pour découvrir notre approche "Hadoop for Humans" de l‘intégration des big data.