






Snaplogic est un intégrateur visionnaire plateforme au service des entreprises de toutes tailles. Avec un nombre croissant d'exécutions mensuelles, SnapLogic s'engage à introduire des solutions innovantes qui aident les clients à gérer et à être performants à grande échelle. Au fur et à mesure que nos clients s'appuient sur les systèmes SnapLogic, ils exigent une meilleure gouvernance des données.
En réponse, nous investissons dans une solution de lignage des données basée sur la norme ouverte populaire, OpenLineage. OpenLineage apportera de la transparence aux transactions automatisées par les pipelines sans code de SnapLogic, permettant aux entreprises de comprendre les connexions au sein de leurs ensembles de données.
Pourquoi les données sont-elles importantes ?
Les entreprises ont généralement une connaissance approfondie de leurs données. Cependant, lorsqu'il s'agit de pipelines créés dans SnapLogic, la visibilité sur le flux de données est parfois limitée. L'architecture de streaming innovante de SnapLogic permet aux utilisateurs de paramétrer largement leurs pipelines, ce qui offre un haut degré de personnalisation et de flexibilité dans les processus d'intégration de données. En faisant abstraction des complexités de l'infrastructure et de l'exécution sous-jacentes, SnapLogic simplifie grandement la tâche de l'utilisateur les workflows. En revanche, il peut rendre les flux de données quelque peu opaques.
Souvent, ces pipelines acheminent dynamiquement les données en fonction des données traitées. Par conséquent, les utilisateurs n'ont pas de visibilité en temps réel sur les dépendances, les transformations (par exemple, les jointures, les filtres, les agrégations) et les autres processus qui se produisent dans leur paysage de données complexe.
Par exemple, si un rapport s'appuie sur les résultats de plusieurs pipelines de données, il peut être difficile d'évaluer leur exactitude ou leur fraîcheur sans disposer d'informations claires sur les sources, les origines et l'historique de la transformation des données. Le lignage des données permet de combler ces lacunes et d'améliorer la clarté et la compréhension du flux de données.
La transparence qu'il offre dans les processus de données de SnapLogic peut être utile :
- Analyse d'impact : Identification des dépendances en aval d'une source de données jusqu'au niveau de la colonne.
- Analyse des causes profondes : Identifier l'origine d'un problème en retraçant le flux de données et les transformations en cours de route.
- Qualité et intégrité des données : Garantir l'exactitude et la cohérence des données entre les systèmes
- Migration/intégration des données : Cartographie des chemins d'accès aux données pour simplifier les migrations et les intégrations de données entre les environnements avec un minimum de perturbations.
- Gestion du cycle de vie des données : Suivi des données au niveau des colonnes, de leur création à leur élimination, pour une conservation et un archivage efficaces.
- Gouvernance et conformité : Établir une piste d'audit au niveau des colonnes pour les actifs de données
Le data lineage est inestimable dans toute organisation traitant de gros volumes de données, mais il est particulièrement crucial dans les secteurs soumis à des exigences légales spécifiques. Deux réglementations clés qui ont accru l'intérêt pour les solutions de lignage des données sont le BCBS 239 du Comité de Bâle sur le contrôle bancaire et le Règlement général sur la protection des données(RGPD) de l'Union européenne.
Le BCBS 239 exige que les banques assurent la transparence des flux de données qui alimentent leurs rapports sur les risques, ce qui nécessite une solide gouvernance des données et un suivi détaillé des données. Le GDPR exige des entreprises qu'elles divulguent les pratiques de gestion des données des consommateurs (le "droit de savoir") et qu'elles honorent les demandes de suppression de données des utilisateurs (le "droit à l'oubli"). Par conséquent, pour se conformer à la réglementation, les organisations doivent suivre les sources de données dans les rapports.
Pourquoi OpenLineage ?
OpenLineage est un projet communautaire géré par des contributeurs issus de projets open-source populaires tels qu'Amundsen, DataHub, Pandas et Spark. À la suite d'efforts similaires tels que OpenTelemetry et OpenTracing, OpenLineage a gagné en popularité et a été activement adopté par de nombreux fournisseurs dans l'ensemble de l'industrie.
Comme le souligne Julien Le Dem, l'un des cofondateurs d'OpenLineage: "Le lignage des données est l'épine dorsale du DataOps. Le lignage peut aider à réduire la fragmentation et la duplication des efforts entre les acteurs de l'industrie, et permettre le développement de divers outils et solutions en termes d'opérations de données, de gouvernance et de conformité."
En collaborant avec les fournisseurs de l'industrie, SnapLogic a rencontré de nombreux formats, chacun nécessitant des adaptateurs uniques pour la communication. C'est précisément le défi que relève OpenLineage, avec un format normalisé déjà largement adopté et de plus en plus utilisé par les fournisseurs.
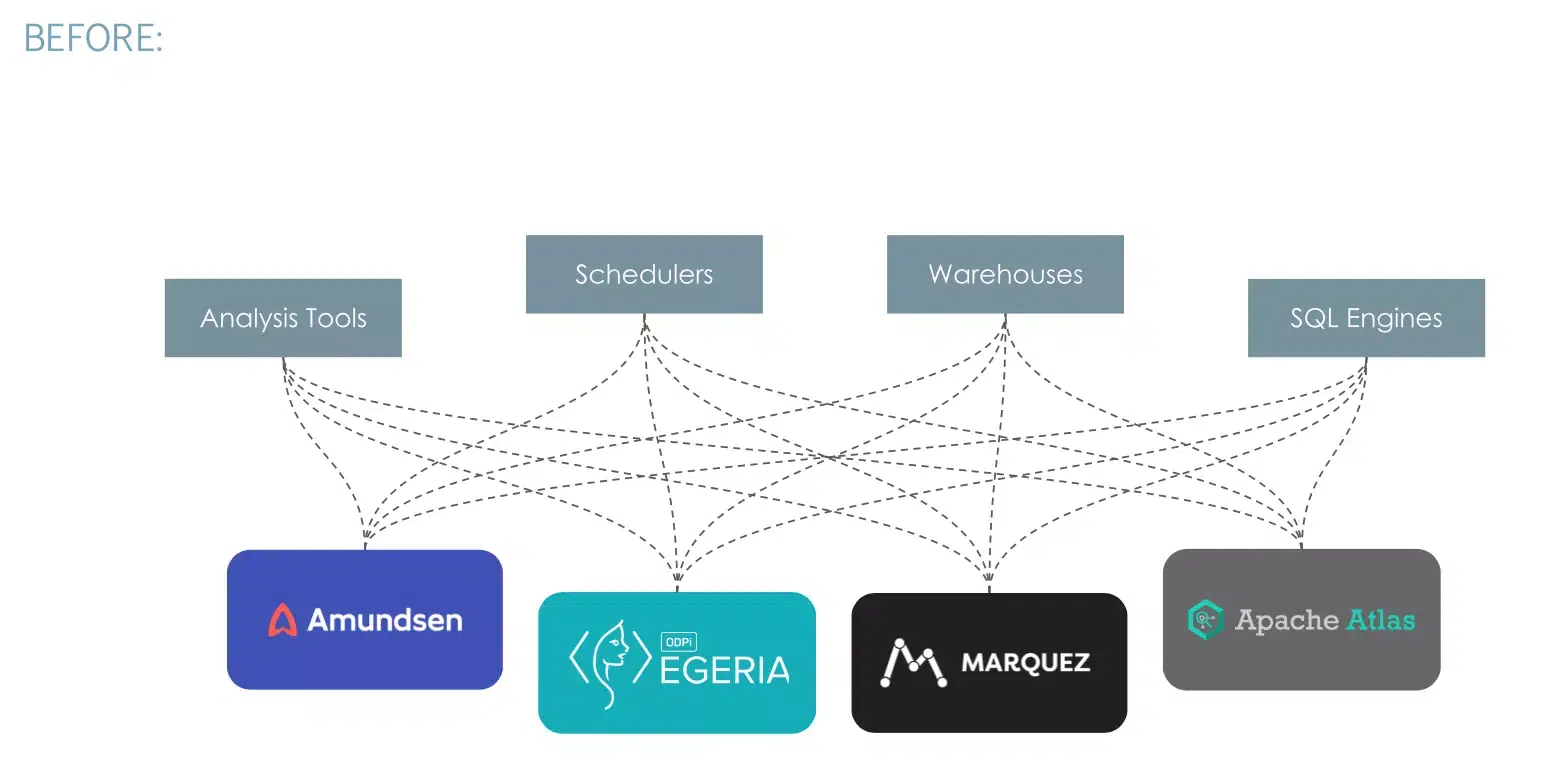
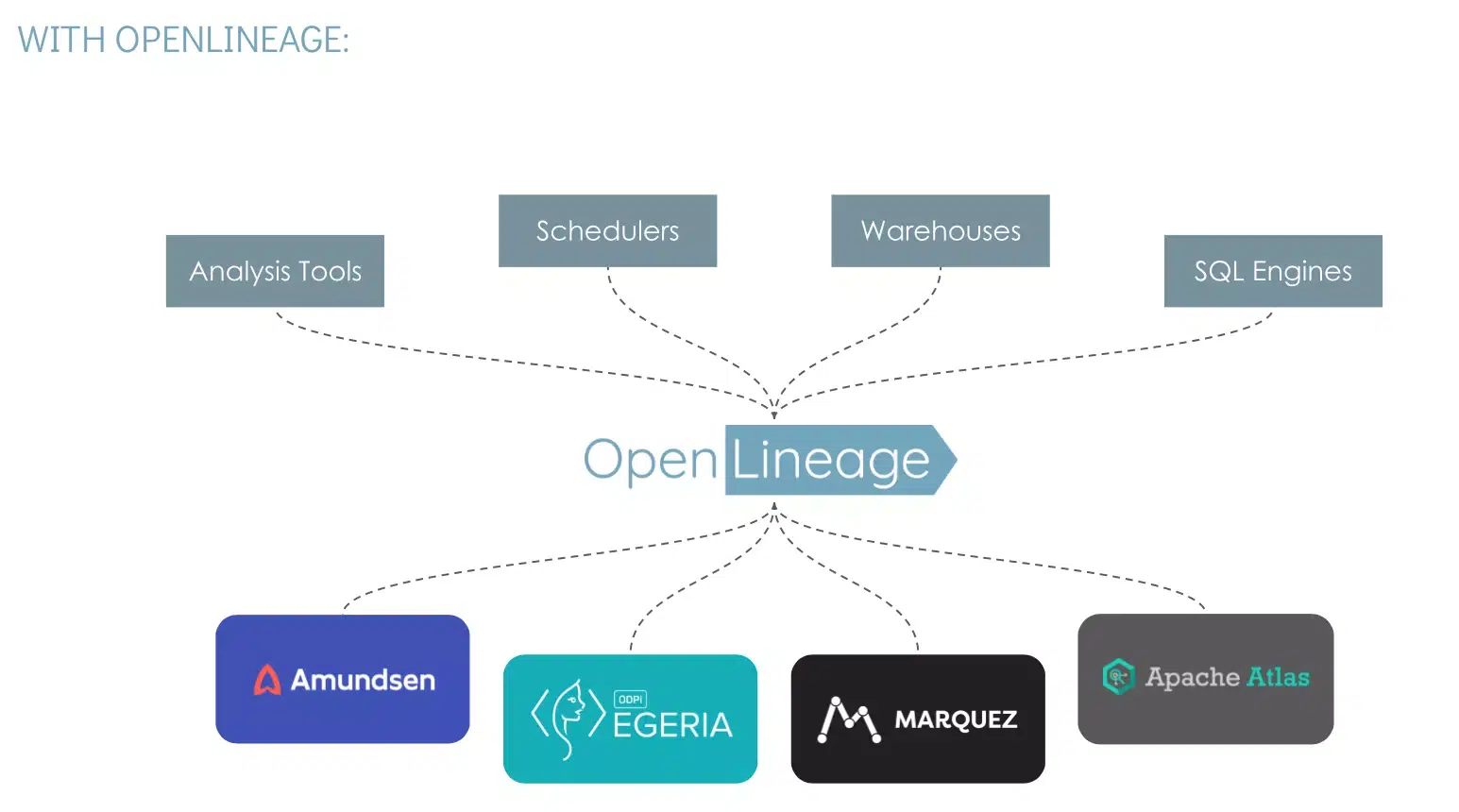
Dans les écosystèmes de données complexes d'aujourd'hui, il est primordial de comprendre le cheminement des données. Les organisations qui cherchent à améliorer la gouvernance des données, à garantir la qualité et la conformité des données ou à optimiser l'efficacité opérationnelle et l'analyse d'impact ont besoin d'une méthode standardisée pour suivre le parcours et les transformations des données à travers leurs systèmes. L'adoption d'OpenLineage par Snaplogic offre une perspective cohérente au niveau de la colonne sur le mouvement des données à travers l'organisation, favorisant la transparence et l'intégration tout en maintenant la neutralité des fournisseurs.
Vous voulez commencer ? Le lignage des données est disponible en tant que fonction d'abonnement dans SnapLabs. Contactez votre CSM pour l'essayer.








