





La création de pipelines d‘intégration est rapide et facile grâce à l‘approche " clics et non code " de SnapLogic. De nombreux utilisateurs de SnapLogic construisent des pipelines simples et complexes en quelques minutes.
Récemment mis à la disposition de tous les utilisateurs de SnapLogic, le SnapLogic Patterns Catalog est une bibliothèque de modèles de pipelines qui peuvent être utilisés pour gagner encore plus de temps en éliminant la nécessité de construire des pipelines à partir de zéro. Introduit en 2014, le SnapLogic Patterns Catalog permet aux utilisateurs de sélectionner des pipelines d‘intégration pré-construits et réutilisables qui peuvent être configurés grâce à un assistant étape par étape dans l‘Enterprise Integration Cloud. Avec des modèles prêts à l‘emploi, vous pouvez passer moins de temps à réinventer la roue, à essayer de comprendre quels connecteurs ou Snaps utiliser, et obtenir des résultats commerciaux rapidement.
Les utilisateurs ayant accès à la communauté SnapLogic peuvent choisir parmi une bibliothèque de modèles examinés et certifiés par l‘équipe SnapLogic. Le catalogue de modèles SnapLogic propose des modèles dans quatre catégories principales : Data Warehousing Patterns, Application Integration Patterns, ETL Patterns et SnapLogic-Specific Patterns.
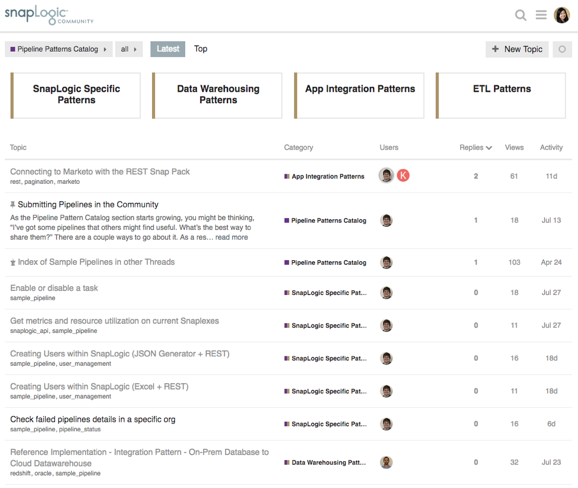
Les principaux modèles d‘intégration d‘applications sont les suivants
- Jira Search to Email Pattern (Modèle de recherche par courriel)
- Modèle d‘authentification Marketo OAuth 2.0
- Mise à jour programmée par lots des données des employés d‘Oracle vers Workday
- Intégrer les contacts Salesforce dans Azure Storage (WASB)
Les principaux modèles ETL sont les suivants
- Ingérer les données de Google Storage dans Google BigQuery
- Charger les données de plusieurs fichiers CSV dans deux tables Oracle ou plus
- Intégrer un grand nombre de petits fichiers sous la forme d‘un fichier séquentiel
- Recherche d‘adresses dans plusieurs bases de données
Les principaux modèles d‘entreposage de données sont les suivants :
- Ingérer les données de la base de données dans le lac de données Hadoop
- Déplacer des données d‘AWS S3 vers Snowflake Data Warehouse
- Lire et écrire dans Azure Blob Storage (WASB)
- Déplacer des données Teradata vers Azure SQL Data Warehouse
Les principaux modèles spécifiques à SnapLogic sont les suivants :
- Création d‘utilisateurs dans SnapLogic
- Activer ou désactiver une tâche
- Gestion des erreurs et pipeline de réessais
- Obtenir les métriques et l‘utilisation des ressources sur les Snaplex actuels
Comment utiliser le catalogue de modèles
Les clients, partenaires et employés de SnapLogic peuvent sélectionner des modèles pour atteindre leur objectif d‘intégration. Chaque modèle comprend une brève description du cas d‘utilisation sur ce que l‘utilisateur peut réaliser en utilisant le pipeline, ainsi que les cibles, les sources et les Snaps utilisés.
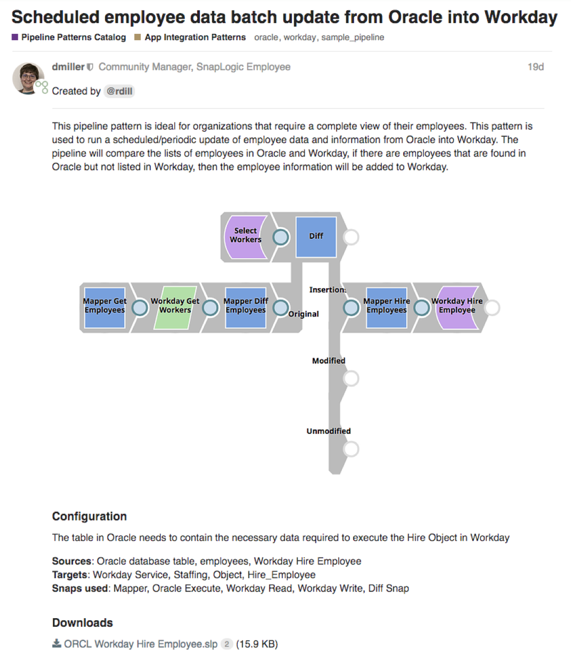
Une fois que l‘utilisateur a sélectionné le modèle de son choix, il peut le télécharger à partir de la communauté SnapLogic et le charger dans SnapLogic plateforme.
Étape 1 : Cliquez sur l‘icône de téléchargement dans SnapLogic Designer.
Étape 2 : Sélectionnez le fichier modèle dans le dossier contenant les téléchargements.
Étape 3 : Une fois le pipeline téléchargé, nommez le modèle de pipeline.
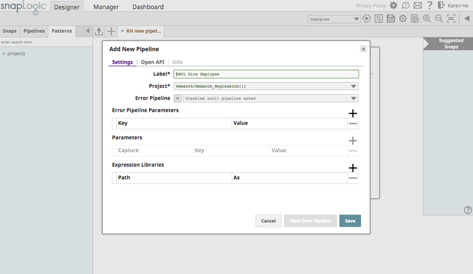
Étape 4 : L‘assistant s‘affiche et l‘utilisateur peut le configurer rapidement.

De nouveaux modèles seront introduits et ajoutés au catalogue de modèles en permanence. Les utilisateurs peuvent également demander un ou plusieurs modèles qui ne sont pas encore disponibles dans le catalogue, et ils peuvent également soumettre des modèles à partager avec leurs pairs. Une fois les patrons soumis examinés et certifiés par l‘équipe SnapLogic, les utilisateurs seront récompensés par des points de fidélité SnapLogic !
Commencez dès aujourd‘hui et explorez le catalogue de modèles SnapLogic.





