





Microsoft Azure HDInsight est une distribution Apache Hadoop alimentée par cloud. En interne, HDInsight s‘appuie sur les données Hortonworks plateforme. HDInsight prend en charge un grand nombre de projets Apache Big Data tels que Spark, Hive, HBase, Storm, Tez, Sqoop, Oozie et bien d‘autres encore. La suite de projets HDInsight peut être administrée via Apache Ambari.
 Ce billet énumère les étapes nécessaires à la mise en place d‘un cluster HDInsight, à la configuration de l‘interface SnapLogic et à la création d‘un cluster HDInsight. Hadooplex sur HDInsight, ainsi que la construction et l‘exécution d‘un pipeline de flux de données Spark sur HDInsight. Nous commençons par créer un cluster HDInsight à partir du portail MS Azure.
Ce billet énumère les étapes nécessaires à la mise en place d‘un cluster HDInsight, à la configuration de l‘interface SnapLogic et à la création d‘un cluster HDInsight. Hadooplex sur HDInsight, ainsi que la construction et l‘exécution d‘un pipeline de flux de données Spark sur HDInsight. Nous commençons par créer un cluster HDInsight à partir du portail MS Azure.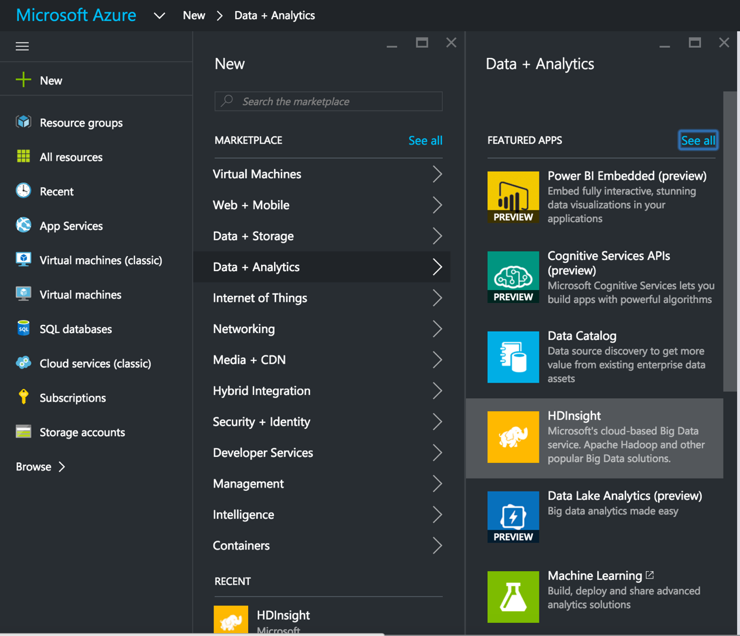
Après avoir sélectionné HDInsight, nous ajoutons le nom du cluster, le type de cluster et d‘autres détails nécessaires pour démarrer le cluster HDInsight. Pour l‘exécution des pipelines Spark, sélectionnez le type de cluster comme Spark, le système d‘exploitation comme Linux et la version comme Spark 1.6.1 (HDI 3.4).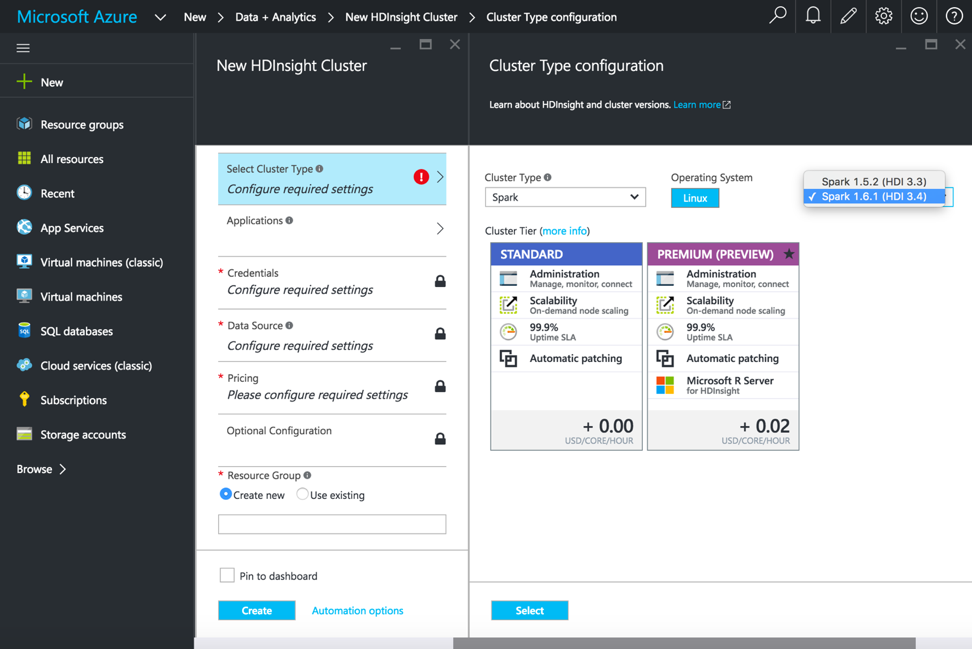
Une fois que le cluster HDInsight est opérationnel, connectez-vous à la console pour créer et configurer un SnapLogic Hadoooplex.
Dans le tableau de bord, assurez-vous que le maître Hadooplex et le nœud se sont enregistrés dans le plan de contrôle de SnapLogic.
À ce stade, nous sommes prêts à créer et à exécuter un pipeline Spark sur HDInsight. Ici, je vais créer un pipeline Spark très basique pour démontrer la lecture d‘un fichier et le renvoyer vers le blob de stockage Azure avec quelques transformations simples.
A partir de la SnapLogic Designer je crée un nouveau pipeline Spark.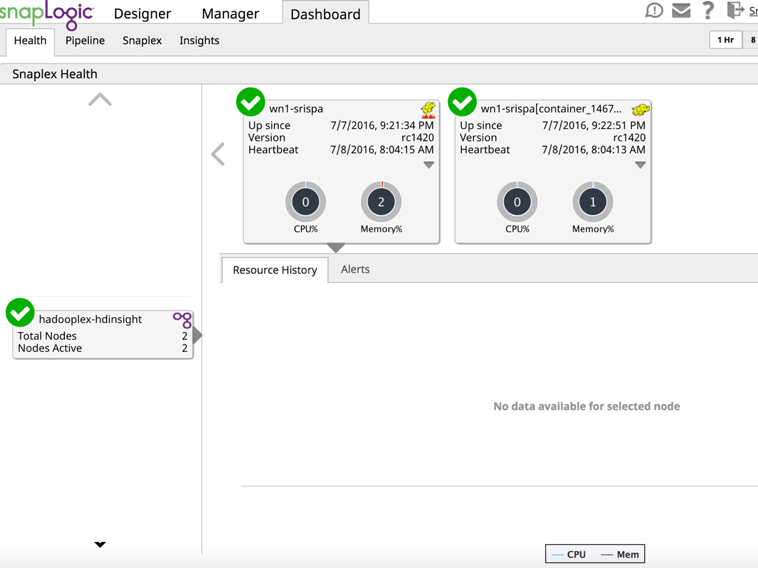
À ce stade, nous sommes prêts à créer et à exécuter un pipeline Spark sur HDInsight. Ici, je vais créer un pipeline Spark très basique pour démontrer la lecture d‘un fichier et le renvoyer vers le blob de stockage Azure avec quelques transformations simples.
Dans le volet SnapLogic Designer, je crée un nouveau pipeline Spark.
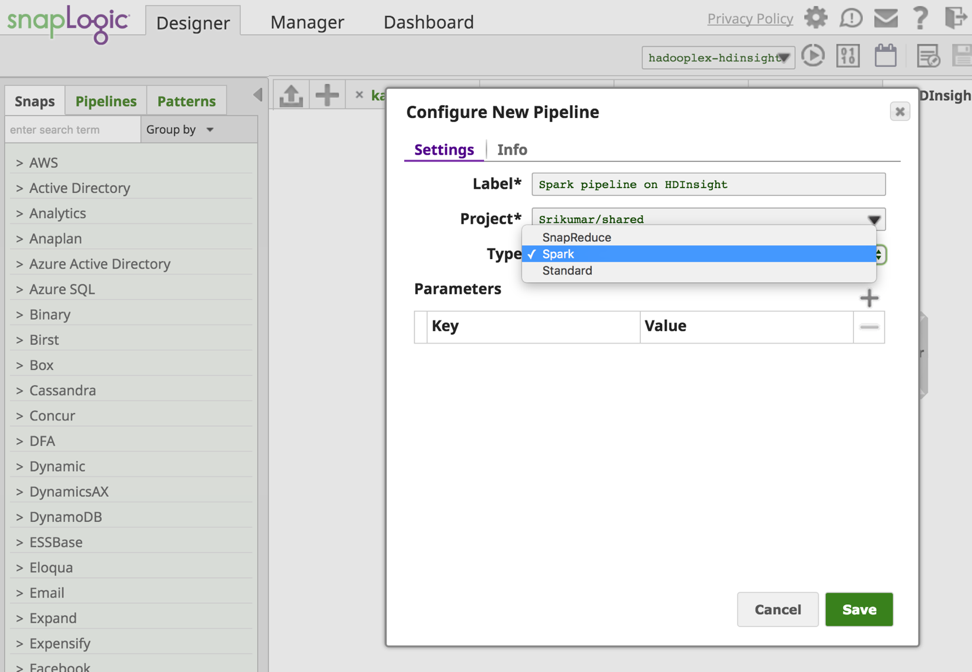
Les Snaps nécessaires sont maintenant ajoutés pour construire le pipeline. Vous trouverez ci-dessous l‘instantané du pipeline.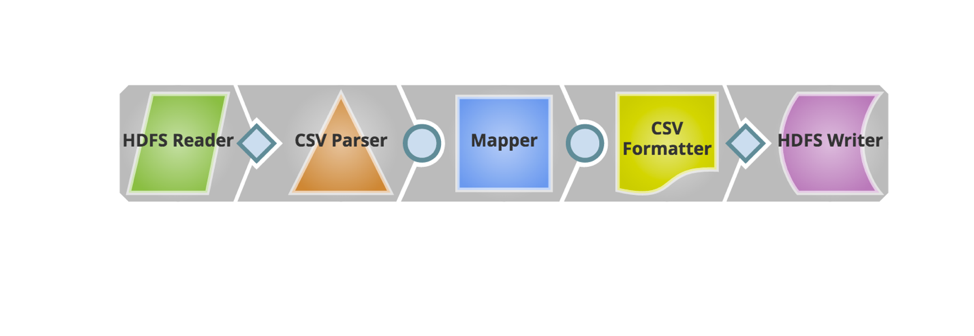
HDInsight utilise le stockage Azure Blob comme magasin de big data pour HDFS. SnapLogic prend en charge le protocole Windows Azure Storage Blob (WASB), qui est une extension de l‘API HDFS.
L‘étape suivante consiste à configurer un compte Azure Storage et à lire/écrire des données à partir du Azure Storage Blob à l‘aide de HDFS Reader & Writer.
Dans l‘onglet "Accounts" de HDFS Reader (ou HDFS Writer), nous cliquerons sur le bouton "Add Account" pour configurer les détails du compte. Dans les "Options de création de compte", choisissez l‘emplacement où enregistrer la configuration du compte et sélectionnez le type de compte "Azure Storage", puis cliquez sur le bouton "OK". 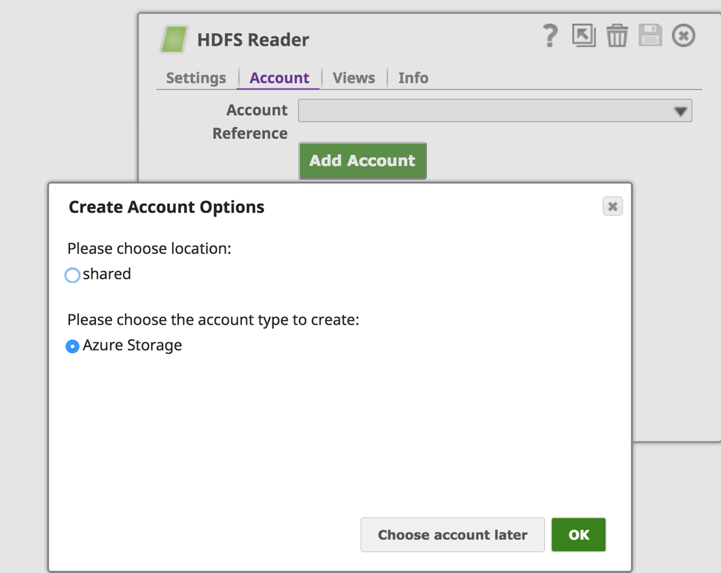
Dans le dialogue "Create Account", entrez le nom du compte Azure et la clé d‘accès principale. Ces informations sont disponibles sur le portail Azure -> Compte de stockage -> Paramètres -> Clés d‘accès.
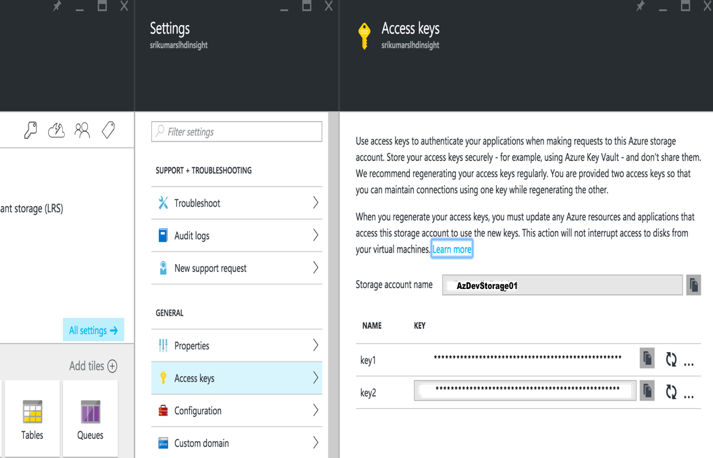
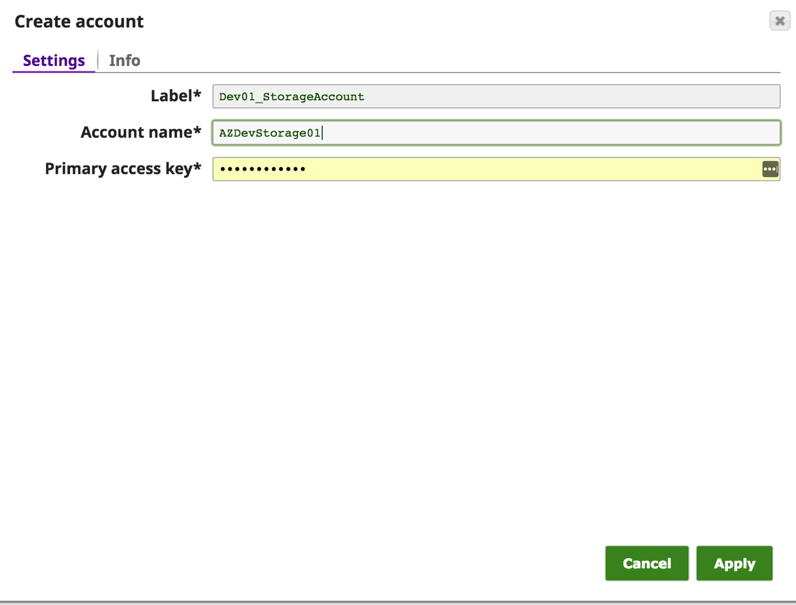
Sauvegardez le compte et vous pouvez maintenant accéder aux données du blob Azure à l‘aide de wasb:///containername/path_to_file.
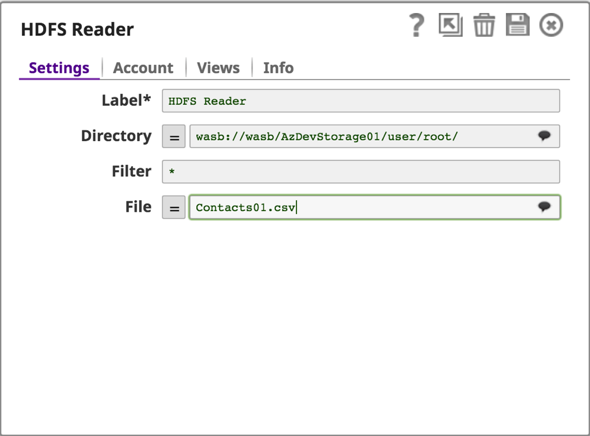
Configurez le reste du pipeline pour transformer et envoyer les données vers un dossier de sortie sur le Azure Storage Blob.
Maintenant, validons et exécutons le pipeline. La capture d‘écran ci-dessous montre la validation et l‘exécution réussies du pipeline Spark.
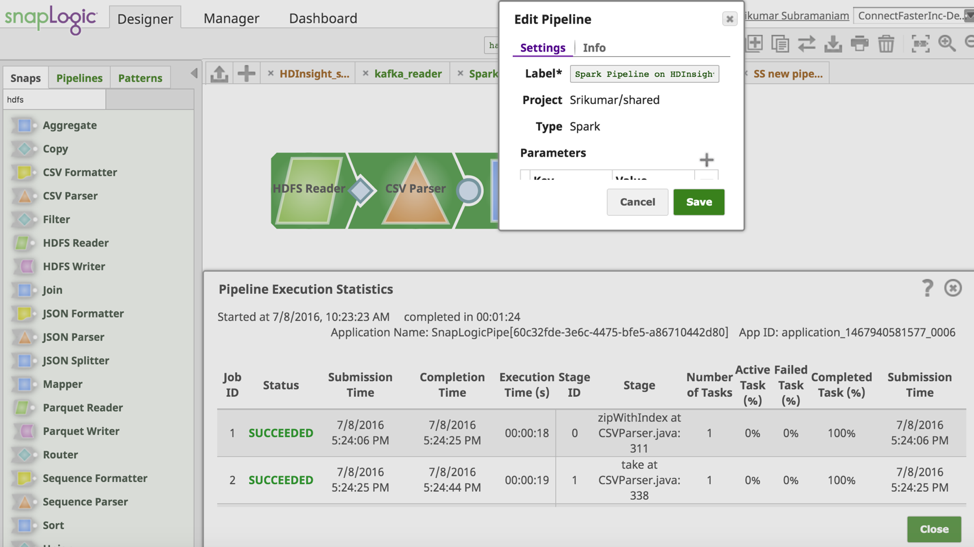
La prise en charge de HDInsight vous permet de tirer parti de la puissance de la plate-forme d‘intégration élastique SnapLogic pour accélérer vos intégrations sur Microsoft Azure plateforme. Pour en savoir plus sur SnapLogic pour Microsoft Azure , cliquez ici.






