





J‘ai la chance de travailler à la fois dans le monde universitaire et dans l‘industrie. En plus de mon travail chez SnapLogic, je suis professeur d‘informatique à l‘université de San Francisco et j‘ai travaillé sur la recherche dans les systèmes distribués, la programmation parallèle, les noyaux de systèmes d‘exploitation et les langages de programmation au cours des 20 dernières années. Ces deux fonctions ont été mutuellement bénéfiques. Je suis en mesure d‘appliquer mes recherches à des systèmes réels et j‘apporte cette expérience à la salle de classe. Chez SnapLogic, j‘ai travaillé à l‘avancement de la technologie de nos produits et, plus récemment, j‘ai fait partie de l‘équipe d‘architecture originale de notre nouveau produit d‘intégration basé sur cloud, qui est un système distribué sophistiqué. Maintenant que nous avons lancé le produit, nous pouvons discuter de nombreux aspects techniques et des décisions de conception du système.
En développant notre plate-forme d‘intégration en tant que service (iPaaS) chez SnapLogic, nous avons réévalué certains des principes de conception fondamentaux des produits d‘intégration traditionnels, hérités des premiers jours de l‘ETL. L‘une de nos innovations les plus profondes en matière d‘architecture consiste à utiliser des documents de type JSON comme principal moyen de transport des données d‘un Snap à l‘autre dans un pipeline. Les anciennes technologies d‘intégration étaient orientées vers les enregistrements, ce qui correspondait bien au monde des bases de données relationnelles de l‘époque. Cependant, nous voyons aujourd‘hui des formats hiérarchiques tels que JSON et XML utilisés à la fois au niveau de l‘interface de service, comme REST et SOAP, et au niveau du magasin de données, comme dans MongoDB.
L‘utilisation de documents comme type de données natif présente plusieurs avantages, tant pour le traitement des données que pour les utilisateurs finaux :
-
Les documents correspondent mieux aux services web modernes.
-
Les documents se traduisent par des pipelines plus succincts.
-
Un modèle de document permet aux pipelines d‘être couplés de manière souple.
-
Un modèle de document permet une plus grande réutilisation du pipeline.
- Les documents sont un surensemble des enregistrements.
Services Web modernes
Alors que certains services web utilisent encore SOAP, un nombre croissant d‘interfaces RESTful utilisent JSON comme format de données pour les requêtes et les réponses. Dans les deux cas, les données sont hiérarchiques. Notre prise en charge des documents permet à nos points d‘extrémité Snap de consommer directement des données hiérarchiques au format natif et de les envoyer aux Snaps en aval dans un pipeline. Cela signifie qu‘il n‘est pas nécessaire d‘aplatir les données en enregistrements ou de transformer un document JSON en chaîne ou en BLOB. Ce support natif permet à tous les Snaps, tels que Filter, Join, Sort, etc., de prendre des décisions basées sur n‘importe quel champ, éventuellement imbriqué, au sein d‘un document. Les données du document résultant peuvent alors être envoyées directement à un Snap de sortie qui se connecte éventuellement à un autre service web qui consomme du JSON. Notre modèle de document natif facilite le traitement des données web modernes dans leur format natif.
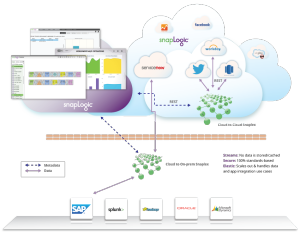
Bien que XML et JSON soient tous deux hiérarchiques, nous remarquons qu‘un nombre croissant de services web et d‘API exposent les données au format JSON en raison de sa légèreté et de sa représentation plus compacte. XML a tendance à gonfler les données de manière significative avec ses encapsulations de méta-tags.
Pipelines succincts
Notre modèle de document conduit finalement à des pipelines plus succincts car il n‘est pas nécessaire de traduire JSON ou XML en enregistrements plats, puis d‘effectuer le traitement, et enfin de reconvertir les enregistrements en JSON ou XML. Cela permet aux utilisateurs de se concentrer sur le traitement des données et non sur la traduction des formats de données, ce qui rend le travail dans SnapLogic plus productif et moins sujet aux erreurs. La réduction du nombre d‘étapes de traduction des données améliore également les performances du pipeline en termes de débit et de latence.
Accouplement lâche
La génération précédente de produits d‘intégration reliait les composants de flux de données par des liens typés. Cela signifie que pour connecter un composant à un autre, tous les champs et types de sortie devaient être correctement liés aux champs et types d‘entrée du composant de destination. Cette correspondance est nécessaire entre chaque composant d‘un graphe de flux de données. Bien que ce couplage conduise à un certain degré de sécurité des types, il est également très difficile de manipuler des pipelines connectés de cette manière. En fait, SnapLogic a déposé un brevet sur la liaison prédictive des champs afin de faciliter la construction de pipelines basés sur une liaison stricte des champs.
Étant donné que notre principal type de données est un document, presque tous les Snaps consomment ou produisent des documents. Il n‘est plus nécessaire de relier les champs pour connecter les Snaps. Cela permet aux utilisateurs de mettre en place des pipelines plus rapidement, car il suffit de connecter les Snaps, de les essayer et de les réorganiser. La mise en correspondance explicite des champs est toujours possible ; par exemple, le champ first_name peut être mis en correspondance avec FirstName, mais cela se fait désormais dans un Snap de mise en correspondance distinct. Cela présente l‘avantage supplémentaire de pouvoir encapsuler les mappages de champs afin de pouvoir les réutiliser facilement dans le même pipeline ou dans des pipelines différents.
Réutilisation des pipelines
En ce qui concerne le couplage lâche, le modèle de document supporte mieux la réutilisation des pipelines. Sans lien strict entre les champs, les pipelines imbriqués sont beaucoup plus faciles à assembler grâce à la réutilisation d‘autres pipelines. D‘une certaine manière, nous sommes passés d‘une approche typée statique à une approche typée dynamique, telle qu‘on la trouve dans les langages de programmation. L‘approche dynamique conduit à des pipelines plus compacts qui sont plus faciles à interconnecter. Cette facilité d‘interconnexion favorise également les tests unitaires des sous-pipelines, ce qui permet d‘obtenir une exécution correcte plus rapidement.
Les documents en tant qu‘enregistrements
Chez SnapLogic, nous sommes conscients que si les services web modernes et les datastores se dirigent vers JSON, les entreprises utilisent toujours des bases de données relationnelles pour les données transactionnelles normalisées. L‘avantage des documents est qu‘ils constituent un surensemble des enregistrements relationnels. Lors de la conversion d‘un enregistrement en document, nous combinons les noms des colonnes du schéma avec les données des champs pour créer un document clé/valeur. Cela nous permet de consommer des enregistrements et d‘en produire selon les besoins, tout en bénéficiant de tous les avantages du modèle de document. En outre, nous prenons en charge les opérations ETL traditionnelles telles que JOIN, AGGREGATE et SORT sur les documents. Cela permet de traiter les données principalement relationnelles de manière transparente, mais aussi d‘étendre ces opérations ETL de manière à prendre en charge les documents hiérarchiques.
Conclusion
En réponse à l‘évolution des points finaux d‘intégration et des formats de données, nous avons repensé de nombreux aspects du fonctionnement de l‘intégration dans notre nouvelle plateforme d‘intégration en tant que service. Notre approche centrée sur JSON englobe les interfaces web modernes et prend en charge les données relationnelles de manière transparente. Cette prise en charge native des documents est l‘une des nombreuses innovations architecturales que nous avons développées pour aider les entreprises à connecter à la fois les services web et les bases de données traditionnelles.



