





Dans le livre blanc intitulé " How to Build an Enterprise Data Lake : Important Considerations Before You Jump In, Mark Madsen, expert du secteur, a exposé les principes qui doivent guider la conception de votre nouvelle architecture de référence et certaines des différences par rapport à l‘entrepôt de données traditionnel. Dans son article de suivi, "Will the Data Lake Drown the Data Warehouse", il pose la question suivante : "Qu‘est-ce que cela signifie pour les outils que nous utilisons depuis dix ans ?"
Dans ce dernier article de la série des articles tirés de ce document (voir le premier article ici et le deuxième article ici), Mark explique comment aborder l‘intégration des big data à l‘aide d‘un exemple :
"La meilleure façon d‘appréhender le défi que représente la construction d‘un lac de données est de se concentrer sur l‘intégration dans l‘environnement Hadoop. Un point de départ commun est l‘idée de déplacer l‘ETL et le traitement des données des outils traditionnels vers Hadoop, puis de pousser les données de Hadoop vers un entrepôt de données ou une base de données comme Amazon Redshift afin que les utilisateurs puissent continuer à travailler avec les données d‘une manière familière. Si nous examinons certains aspects spécifiques de ce scénario, le problème de l‘utilisation d‘une nomenclature en tant que guide technologique devient évident. Par exemple, le traitement des journaux d‘événements web est lourd et coûteux dans une base de données, c‘est pourquoi de nombreuses entreprises transfèrent cette charge de travail vers Hadoop".
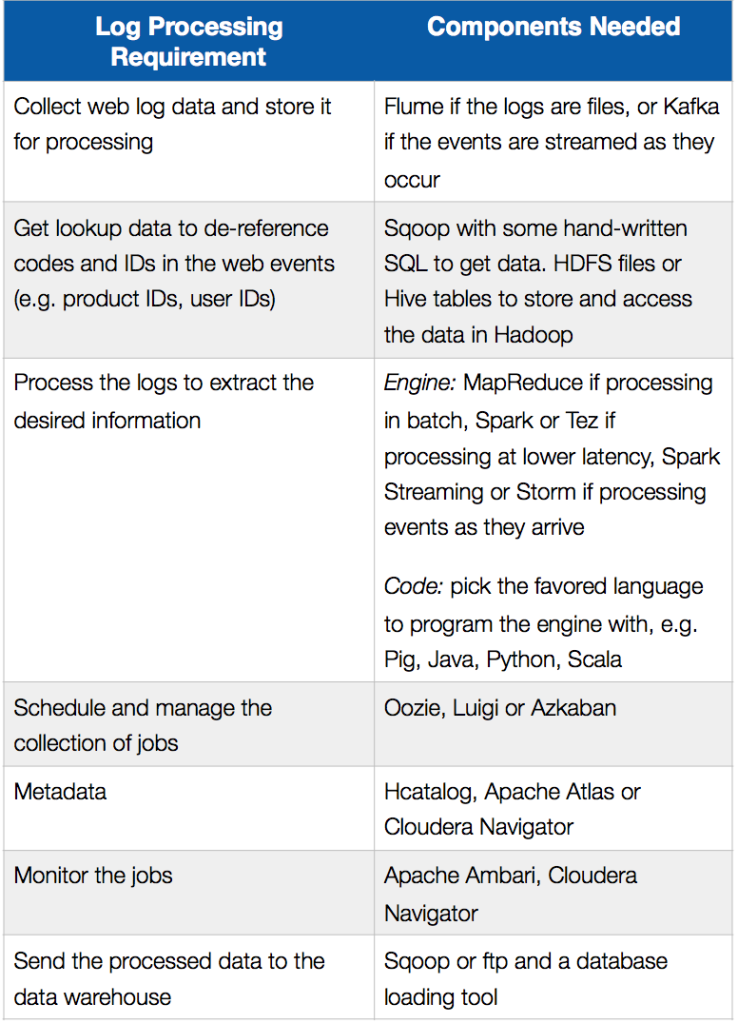
Le tableau suivant résume les exigences en matière de traitement des journaux dans un scénario de déchargement ETL et les composants qui pourraient être utilisés pour les mettre en œuvre dans Hadoop :
Il passe ensuite en revue les défis en matière de développement et les compromis liés à ce type d‘approche, avant de conclure :
"La construction d‘un lac de données nécessite de réfléchir aux capacités requises dans le système. Il s‘agit d‘un problème plus important que le simple fait d‘installer et d‘utiliser des projets open source au-dessus de Hadoop. Tout comme l‘intégration des données est le fondement de l‘entrepôt de données, une capacité de traitement des données de bout en bout est au cœur du lac de données. Le nouvel environnement a besoin d‘un nouveau cheval de bataille".
Prochaines étapes :
- Télécharger le livre blanc : Comment construire un lac de données d‘entreprise : Considérations importantes avant de se lancer. Vous pouvez également regarder l‘enregistrement webinar et consulter les diapositives sur le blog de SnapLogic.
- Télécharger le livre blanc : Le lac de données va-t-il noyer l‘entrepôt de données ?
- Regardez cette démonstration de SnapReduce et de SnapLogic Hadooplex pour découvrir notre approche "Hadoop for Humans" de l‘intégration des big data.





