





Dans mon dernier billet de cette série sur les pipelines SnapLogic Ultra, je vais aborder les trois piliers d‘une mise en œuvre réussie et de la gestion des pipelines de données : la performance, la mise à l‘échelle et la haute disponibilité.
- Performance : Les performances d‘un Ultra Pipeline dépendent largement des temps de réponse des applications du système final auxquelles la tâche se connecte. Un Ultra Pipeline contenant un grand nombre de Snaps d‘extrémité à latence élevée peut observer un encombrement des documents, remontant tout le long des Snaps en amont jusqu‘au feedmaster, jusqu‘à ce que la file d‘attente du feedmaster ne puisse plus contenir les messages. Cette situation peut être évitée en créant plusieurs instances de la tâche Ultra Pipeline ou en utilisant le Snap Router pour répartir la charge de documents. Plusieurs instances d‘Ultra Pipeline garantissent que même si l‘une d‘entre elles est lente, d‘autres sont disponibles pour consommer des documents et maintenir le flux de la file d‘attente du feedmaster. De même, un Router Snap peut être utilisé dans chaque instance du pipeline pour distribuer les documents sur plusieurs Snaps d‘extrémité, afin d‘améliorer les performances et d‘ajouter une capacité de traitement parallèle à une instance. Cela s‘ajoute à la capacité de calcul parallèle intégrée d‘un pipeline, qui implique qu‘à un moment donné, chaque Snap d‘un pipeline traite un document différent.
- Mise à l‘échelle : La mise à l‘échelle peut être obtenue en augmentant le nombre d‘instances d‘une tâche Ultra Pipeline. Le nombre total d‘instances requises pour une tâche Ultra Pipeline est une fonction directe du temps de réponse attendu, de l‘utilisation des ressources du nœud lorsqu‘une seule instance de la tâche est en cours d‘exécution et de la charge fonctionnelle sur le Snaplex provenant d‘autres exécutions du pipeline. Lorsque les nœuds d‘exécution sont fortement utilisés, l‘ajout de nœuds d‘exécution supplémentaires permet de distribuer horizontalement les instances de la tâche et de les étendre à l‘ensemble du Snaplex.
- Haute disponibilité: Afin d‘éviter toute interruption de service et de permettre une haute disponibilité, il est fortement recommandé d‘utiliser un équilibreur de charge avec deux feedmasters et deux nœuds d‘exécution comme architecture minimale pour la configuration d‘Ultra Pipeline. Une telle architecture peut également être utilisée pour éviter un point de défaillance unique d‘un feedmaster ou d‘un nœud d‘exécution.
Gestionnaire
Chaque tâche d‘Ultra Pipeline est répertoriée dans le menu Gestionnaire/projet/tâche. Pour visualiser le nombre de documents reçus ou traités par chaque instance de la tâche, un menu déroulant listant les détails de la tâche peut être utilisé :

Utilisez le lien Détails sur une tâche pour afficher les statistiques d‘exécution du pipeline et surveiller les documents reçus par chaque Snap dans l‘instance d‘Ultra Pipeline.
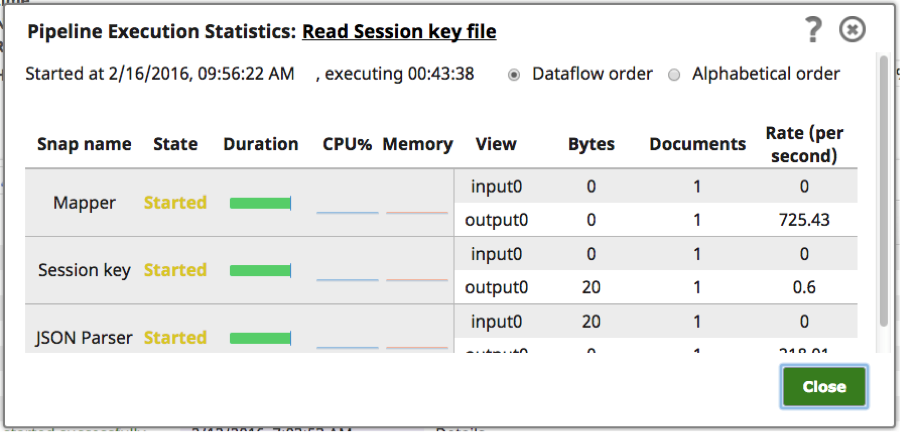
Comme la vue détaillée ne répertorie que les documents reçus par cette instance de la tâche, un contrôle plus avancé peut être nécessaire en cas d‘instances multiples pour obtenir une vue d‘ensemble des documents, des files d‘attente et des abonnés. J‘ai travaillé avec des clients de SnapLogic sur ce type d‘initiative en utilisant nos API et j‘ai obtenu de bons résultats.
Prochaines étapes :
- Jetez un coup d‘œil à ma série de billets sur les pipelines SnapLogic Ultra et n‘hésitez pas à me faire part de vos questions ou commentaires. Conception des Ultra Pipelines, Types de vues, Gestion des erreurs et des exceptions)
- Découvrez nos vidéos et la prochaine session SnapLogic Live
- En savoir plus sur nos offres de services professionnels






