





YARN est le prérequis pour Enterprise Hadoop. Il permet de gérer les ressources des clusters Hadoop et d‘étendre la puissance d‘Hadoop aux nouvelles technologies afin qu‘elles puissent bénéficier d‘un stockage et d‘un traitement rentables et linéaires, d‘un stockage et d‘un traitement linéaires et rentables. Il fournit aux éditeurs de logiciels indépendants et aux développeurs un cadre cohérent pour l‘écriture d‘applications d‘accès aux données fonctionnant dans Hadoop.
Les clients qui construisent un lac de données s‘attendent à pouvoir exploiter les données sans les déplacer vers d‘autres systèmes, en tirant parti des ressources de traitement du lac de données. Les applications qui utilisent YARN tiennent cette promesse, en réduisant les coûts opérationnels tout en améliorant la qualité et le temps de visibilité.
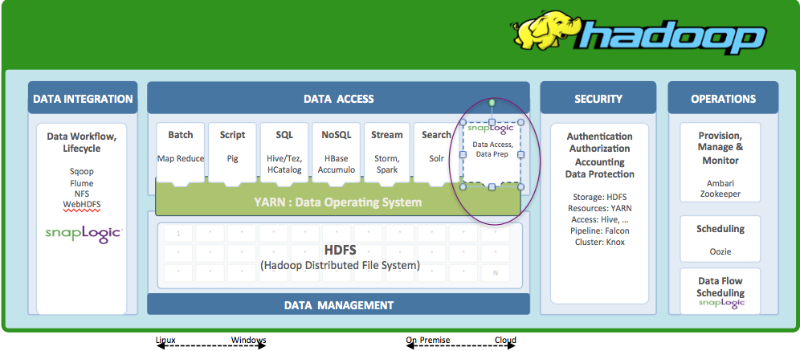
Intégration avec YARN
Pour exploiter la puissance de YARN, une application tierce peut soit utiliser YARN nativement, soit utiliser un framework YARN (Apache Tez, Apache slider, etc.) et si elle n‘utilise pas YARN, elle lit probablement directement à partir de HDFS.
Il existe trois grandes options pour l‘intégration dans YARN.
- Contrôle total ou YARN natif : Contrôle fin des ressources du cluster, ce qui permet une mise à l‘échelle élastique.
- Interaction à travers un cadre YARN existant comme MapReduce : Limitée à l‘une des options suivantes : batch, interactive ou temps réel. Pas de prise en charge de la mise à l‘échelle élastique à l‘aide de YARN.
- Interaction avec des applications fonctionnant déjà sur un framework YARN tel que Hive : Limitée à des applications ou à des cas d‘utilisation très spécifiques, par exemple l‘utilisation de Hive. Pas de prise en charge de la mise à l‘échelle élastique à l‘aide de YARN.
De toute évidence, toute application qui dispose d‘un contrôle total et qui est native, offre un avantage significatif pour pouvoir faire des choses très avancées dans Hadoop en utilisant les capacités de YARN.
Cette différence est nécessaire car l‘espace devient à la fois plus intéressant et plus confus. Les fournisseurs Hadoop comme Hortonworks proposent des certifications Yarn Native et Yarn Ready. Yarn Ready signifie qu‘une application peut travailler avec n‘importe quelle application compatible avec Yarn, comme Hive, alors que Yarn Native signifie un contrôle total et un accès précis aux ressources du cluster.
SnapLogic est Yarn Native. Cela signifie qu‘à mesure que les volumes de données ou les charges de travail augmentent, la SnapLogic Elastic Integration plateforme peut s‘étendre automatiquement et de manière élastique en utilisant plus de nœuds dans le cluster Hadoop à la demande, et lorsque ces charges de travail diminuent, elles se réduisent automatiquement. Dans SnapLogic, cela s‘appelle la Hadooplex. Cet article de blog passe en revue des exemples de Pipelines d‘intégration de big data SnapLogic.
Cet article a été publié à l‘origine sur LinkedIn. Ravi Dharnikota est conseiller principal chez SnapLogic. Il travaille en étroite collaboration avec les clients sur leur architecture de référence big data et cloud .




