Ce billet illustre deux de nos scénarios les plus fréquemment rencontrés par les clients :
a) Un exemple de traitement XML complexe, et
b) Un exemple concret de ce à quoi pourrait ressembler l‘ embarquement et le débarquement des RH avec les données de Workday.
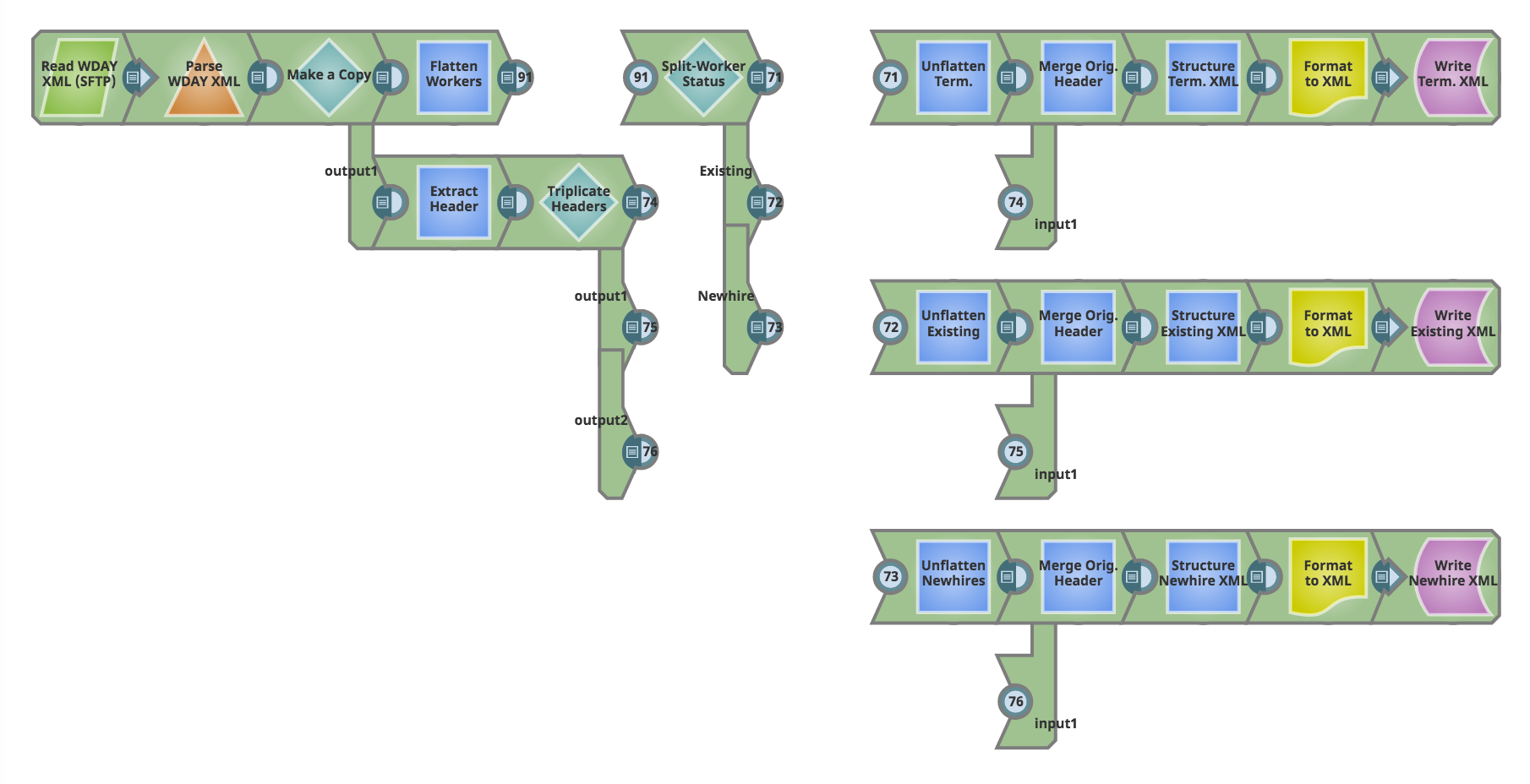
Vous trouverez ci-dessous une capture d‘écran du pipeline et une description détaillée de ce qu‘il tente de réaliser.
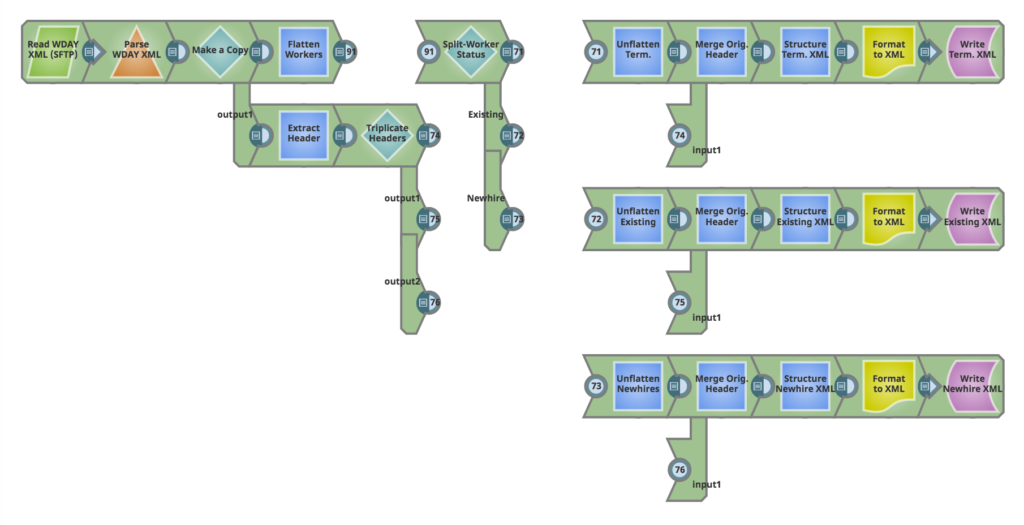
Passons en revue cette filière.
A gauche, nous commençons par lire un extrait XML de Workday, qui contient,
a) les nouveaux embauchés
b) les travailleurs licenciés, et
c) Actifs (qui ne sont ni des nouveaux embauchés ni des travailleurs licenciés)
Notre objectif dans ce pipeline est de séparer ces trois types de travailleurs et de les écrire dans leurs propres fichiers XML. Ces fichiers XML cibles représentent des flux destinés à un ou plusieurs systèmes qui traitent l‘intégration et la désinsertion des employés.
L‘extrait Employés de Workday fournit également des données agrégées dans l‘en-tête XML. Ces informations d‘en-tête sont présentes dans notre extrait source. Notre objectif est également de préserver cet en-tête et de l‘introduire dans chacun des XML cibles, avec une mise à jour d‘un champ d‘en-tête spécifique (nombre de travailleurs) qui reflète le nombre total de travailleurs écrits dans chaque fichier XML cible.
Visite guidée du pipeline
Dès que nous lisons la source Worker XML et que nous séparons le fichier, nous en faisons une copie. Le long du chemin supérieur, nous traitons la charge utile XML. Le long du chemin inférieur de la copie, nous extrayons et préservons l‘en-tête pour l‘utiliser ultérieurement. Examinons chacun de ces chemins séparément.
A. Traitement des données utiles XML
Nous commençons par supprimer la hiérarchie dans les données relatives aux travailleurs en utilisant un séparateur JSON (aplatir les travailleurs). Le cœur du traitement des travailleurs a lieu à l‘étape "Séparer le statut du travailleur", qui est mise en œuvre à l‘aide d‘un snap Router avec l‘option "Première correspondance" activée. Nous séparons les trois types de travailleurs en utilisant la logique ci-dessous :
a) Réintroduire le préfixe ws: :
Cela se fait en utilisant l‘action Group By N avec un champ cible $ws.
b) Réintroduire l‘en-tête XML
Nous introduisons l‘en-tête XML préservé dans le résultat de l‘étape a) ci-dessus. Plus de détails sur l‘introduction de l‘en-tête sont donnés ci-dessous.
B. Traitement de l‘en-tête XML
Nous conservons le nom de l‘élément racine (Worker_Sync) lors de la conversion :

Nous ajoutons la charge utile traitée (les travailleurs séparés par type) sous Worker_Sync par le biais du mappage : 
Enfin, nous utilisons la mise à jour du champ du nombre de travailleurs ($[‘ws:Worker_Sync‘][‘ws:Header‘][‘ws:Worker_Count‘]) dans l‘en-tête nouvellement introduit à travers :

Une fois cela fait, notre XML est prêt à être formaté et écrit dans son fichier cible (ou envoyé à un autre point de terminaison). Veuillez noter que vous devez laisser l‘élément racine vide dans le formateur XML afin d‘éviter que les balises par défaut ne soient introduites.
Hari Shankar est ingénieur-conseil en solutions SnapLogic.