Qu‘est-ce que l‘ETL ?
L‘ETL (Extract, Transform, Load) est un processus d‘intégration de données comprenant trois étapes clés : l‘extraction de données à partir de sources disparates, leur transformation pour répondre aux besoins opérationnels et leur chargement dans un système de destination à des fins d‘analyse et d‘établissement de rapports. Ce processus est fondamental pour l‘entreposage des données, car il permet de consolider, de gérer et d‘utiliser efficacement les données à des fins d‘intelligence économique.
Comment fonctionne l‘ETL ?
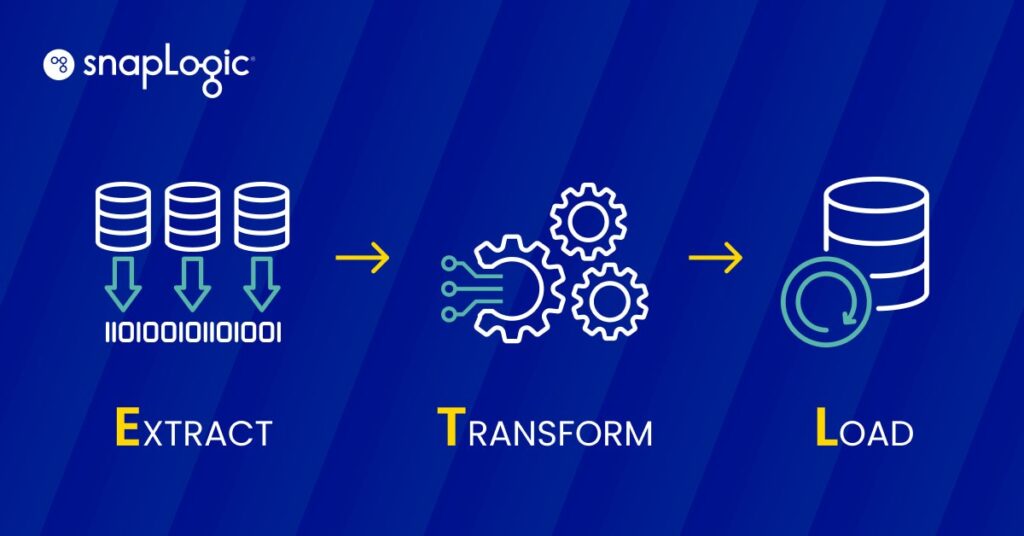
L‘ETL fonctionne selon un processus en trois étapes conçu pour gérer efficacement l‘extraction, la transformation et le chargement des données dans un référentiel central.
- Extraction : Cette première étape consiste à extraire des données de diverses sources, qui peuvent être des bases de données, des feuilles de calcul ou d‘autres formats. L‘objectif est de rassembler les données nécessaires dans leur format d‘origine, indépendamment de la structure ou du type de la source.
- Transformation : Une fois les données extraites, elles passent par une phase de transformation au cours de laquelle elles sont nettoyées et converties pour répondre aux exigences du système cible. Cette étape peut impliquer le filtrage, le tri, la validation et l‘agrégation des données pour s‘assurer qu‘elles répondent aux normes de qualité et de format à des fins d‘analyse.
- Chargement : La dernière étape consiste à charger les données transformées dans un système de destination, tel qu‘un entrepôt de données ou une base de données. Cette étape est cruciale car elle rend les données accessibles pour l‘analyse commerciale et les processus de prise de décision.
Chaque étape est essentielle pour garantir que les données sont utilisables, sécurisées et stockées efficacement, ce qui fait de l‘ETL un processus essentiel pour les initiatives d‘entreposage de données et de veille stratégique.
Qu‘est-ce qu‘un pipeline ETL ?
Un pipeline ETL formalise le processus de déplacement et de transformation des données décrit plus haut dans cet article. Il s‘agit d‘une séquence d‘opérations mises en œuvre dans un outil ETL pour garantir que les données sont extraites des systèmes sources, transformées correctement et chargées dans un entrepôt de données ou d‘autres systèmes à des fins d‘analyse.
Flux de travail structuré : Le pipeline ETL englobe les trois principales étapes de l‘ETL - l‘extraction, la transformation et le chargement - dans un flux de travail structuré. Cette approche structurée facilite la gestion des flux de données et garantit que chaque phase est achevée avant que la suivante ne commence.
L‘automatisation : Les pipelines ETL automatisent les tâches répétitives et routinières de traitement des données. Cette automatisation permet l‘ingestion continue des données, leur transformation selon les règles et les exigences de l‘entreprise et le chargement ultérieur des données traitées dans des systèmes analytiques ou opérationnels pour la veille économique, le reporting et la prise de décision.
Intégration et planification : Dans un pipeline ETL, les tâches sont généralement planifiées et gérées par un outil d‘orchestration, qui coordonne l‘exécution des différents travaux en fonction de la disponibilité des données, des dépendances et de la réussite des tâches précédentes. Cette planification est cruciale pour maintenir la fraîcheur et la pertinence des données, en particulier dans les environnements commerciaux dynamiques où les besoins en données évoluent en permanence.
Surveillance et maintenance : Un pipeline ETL efficace comprend également des capacités de surveillance permettant de suivre les flux de données, de gérer les erreurs et de garantir la qualité des données. La maintenance consiste à mettre à jour les transformations et les processus en fonction des changements apportés aux systèmes sources ou aux besoins de l‘entreprise.
Quelle est la différence entre ETL et ELT ?
La différence entre ETL (Extract, Transform, Load) et ELT (Extract, Load, Transform) réside principalement dans l‘ordre et l‘emplacement de la transformation des données, ce qui a un impact sur le traitement des données. réside principalement dans l‘ordre et l‘emplacement de la transformation des données, ce qui a un impact sur le traitement des données les workflows, en particulier lors du traitement de gros volumes de données provenant de diverses sources.
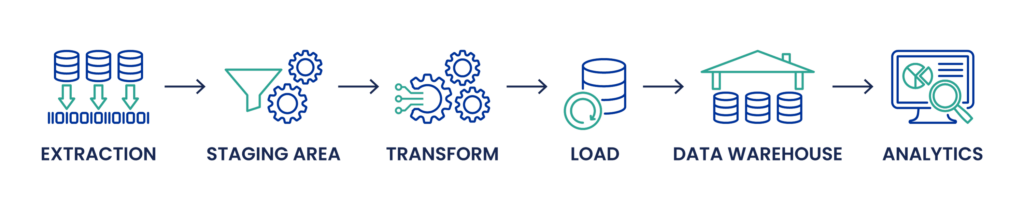
Processus ETL : Dans le processus ETL traditionnel, les données sont d‘abord extraites des systèmes sources, qui peuvent être des bases de données relationnelles, des fichiers plats, des API, etc. Ces données extraites sont ensuite transformées dans une zone de transit, où le nettoyage des données, la déduplication et d‘autres processus de transformation ont lieu pour garantir la qualité et la cohérence des données. Le processus de transformation peut impliquer des requêtes SQL complexes, la manipulation de différents types de données et des tâches d‘ingénierie des données telles que le mappage des schémas et la gestion des métadonnées. Ce n‘est qu‘après ces transformations que les données sont chargées dans la base de données cible ou l‘entrepôt de données, comme Snowflake ou Microsoft SQL Server, pour être utilisées dans l‘analyse des données, la veille stratégique et la visualisation.
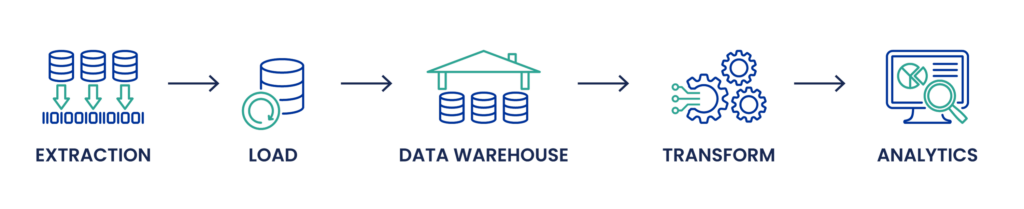
Processus ELT : L‘ELT, quant à lui, inverse les deux dernières étapes de l‘ETL. Les données sont d‘abord extraites et chargées dans un lac de données ou un magasin de données moderne comme Google BigQuery ou Amazon Redshift, souvent sous leur forme brute. Cette approche est particulièrement avantageuse lorsqu‘il s‘agit de traiter des quantités massives de données, notamment des données non structurées provenant d‘appareils IoT, de bases de données NoSQL ou de fichiers JSON et XML. La transformation intervient après le chargement, en tirant parti des puissants moteurs de traitement des données de ces plateformes. Cette méthode permet une plus grande flexibilité dans la gestion des schémas de données et peut gérer les besoins de traitement des données en temps réel, ce qui permet des ajustements plus agiles du pipeline de données et facilite les applications d‘apprentissage automatique et d‘intelligence artificielle.
Principales différences :
- Volume et variété des données : L‘ELT est généralement mieux adapté aux scénarios de big data dans lesquels de grands ensembles de données sont ingérés à partir de différentes sources. Il gère efficacement les données non structurées et automatise les transformations de données au sein du système de stockage des données.
- Performance et évolutivité : ELT peut offrir de meilleures performances pour de grands volumes de données et est très évolutif grâce aux puissantes capacités de traitement des magasins de données modernes basés sur le site cloud.
- Flexibilité : Les ELT offrent une plus grande souplesse dans l‘interrogation et la gestion des données, car les transformations sont appliquées en fonction des besoins dans le lac de données ou l‘entrepôt.
En résumé, le choix entre l‘ETL et l‘ELT dépend des besoins spécifiques en matière de gestion des données, de la nature des sources de données, des cas d‘utilisation prévus pour les données et de l‘infrastructure de données existante. L‘ELT gagne en popularité dans les environnements qui privilégient la flexibilité, l‘évolutivité et le traitement des données en temps réel, tandis que l‘ETL reste pertinent pour les scénarios nécessitant un nettoyage et une transformation intensifs des données avant qu‘elles ne puissent être stockées ou analysées.
Free eBook: ETL vs. ELT : lequel convient le mieux à votre organisation ?
Qu‘est-ce que l‘ETL traditionnel par rapport à l‘ETL Cloud ?
L‘ETL traditionnel et l‘ETL Cloud représentent deux méthodologies de traitement des processus d‘extraction, de transformation et de chargement des données, chacune étant adaptée à des environnements technologiques et à des besoins commerciaux différents.
ETL traditionnel : Les processus ETL traditionnels sont conçus pour fonctionner dans une infrastructure sur site. Il s‘agit de serveurs physiques et d‘espaces de stockage que l‘entreprise possède et entretient. Dans cet environnement, les outils ETL font généralement partie d‘un réseau fermé et sécurisé. Les principales caractéristiques sont les suivantes
- Contrôle et sécurité : L‘infrastructure étant sur site, les entreprises ont un contrôle total sur leurs systèmes et leurs données, ce qui peut être crucial pour les secteurs ayant des exigences strictes en matière de sécurité des données et de conformité.
- Investissement initial : L‘ETL traditionnel nécessite un investissement initial important en matériel et en infrastructure.
- Maintenance : Nécessite une maintenance permanente du matériel et des logiciels, y compris des mises à jour et des dépannages, ce qui peut nécessiter beaucoup de ressources.
- Défis liés à l‘évolutivité : La mise à l‘échelle nécessite du matériel physique supplémentaire, ce qui peut être lent et coûteux.
Cloud ETL : Cloud ETL, d‘autre part, exploite les environnements informatiques cloud , où les ressources sont virtuellement extensibles et gérées par des fournisseurs tiers. Cette approche a gagné en popularité en raison de sa flexibilité, de son évolutivité et de sa rentabilité. Ses caractéristiques sont les suivantes
- Évolutivité et flexibilité : Cloud L‘ETL peut facilement augmenter ou diminuer les ressources en fonction des besoins de traitement, souvent de manière automatique. Cette flexibilité est précieuse pour gérer les charges de travail variables et le traitement des données volumineuses (big data).
- Réduction des dépenses d‘investissement : Avec cloud ETL, les entreprises évitent les coûts initiaux importants associés à l‘ETL traditionnel, payant plutôt pour ce qu‘elles utilisent, souvent sur la base d‘un abonnement.
- Amélioration de la collaboration et de l‘accessibilité : les solutions Cloud offrent une meilleure accessibilité aux équipes distribuées, permettant une collaboration entre différents sites géographiques.
- Intégration avec les services de données modernes : Cloud Les outils ETL sont conçus pour s‘intégrer de manière transparente à d‘autres services cloud , notamment les analyses avancées, les modèles d‘apprentissage automatique, et plus encore, offrant ainsi un pipeline de traitement des données complet.
Le choix entre l‘ETL traditionnel et l‘ETL cloud dépend de plusieurs facteurs, notamment la stratégie de données de l‘entreprise, les besoins en matière de sécurité, les contraintes budgétaires et les cas d‘utilisation spécifiques. Cloud L‘ETL offre une approche moderne qui s‘aligne sur les initiatives de transformation numérique et prend en charge des environnements décisionnels plus dynamiques et axés sur les données. L‘ETL traditionnel, bien que parfois contraint par sa nature physique, reste un choix solide pour les organisations qui ont besoin d‘un contrôle étroit sur leur infrastructure de données et leurs opérations.