






Le ML Data Preparation Snap Pack automatise la plupart des tâches de préparation des données qui se présentent lors du développement d‘un modèle d‘apprentissage automatique. Il offre aux data scientists une alternative visuelle, par glisser-déposer, au codage manuel fastidieux des opérations de préparation des données. Les data scientists peuvent passer moins de temps à nettoyer les données et plus de temps à effectuer des tâches stratégiques - et amusantes - comme l‘élaboration d‘un modèle d‘apprentissage automatique.
Le ML Data Preparation Snap Pack comprend les snaps suivants :
- De catégorique à numérique : Convertir les colonnes catégorielles en colonnes numériques en utilisant un codage entier ou un codage à chaud.
- Nettoyer les valeurs manquantes : Remplacez les valeurs manquantes dans les ensembles de données en supprimant ou en imputant des valeurs.
- Date Time Extractor : Extraction de composants à partir d‘objets de type datetime.
- Synthèse d‘éléments : Créez automatiquement des caractéristiques à partir de plusieurs ensembles de données qui partagent une relation de type un à un ou un à plusieurs entre eux.
- Correspondance : Faire correspondre des enregistrements provenant de différentes sources de données qui représentent la même entité sans s‘appuyer sur une clé commune.
- Numérique à catégorique : Convertissez des colonnes numériques en colonnes catégorielles en utilisant des intervalles ou des binages personnalisés.
- Analyse en composantes principales : Effectuer une analyse en composantes principales pour réduire la dimensionnalité.
- Échantillon : Générer des ensembles de données échantillons à partir d‘un ensemble de données d‘entrée à l‘aide d‘algorithmes d‘échantillonnage.
- Échelle : Mettre à l‘échelle les valeurs dans les colonnes pour spécifier des plages ou appliquer des transformations statistiques.
- Shuffle (Mélanger) : Randomiser l‘ordre des lignes de données dans l‘ensemble de données.
- Convertisseur de type : détermine les types de valeurs dans les colonnes. Quatre types sont pris en charge : entier, virgule flottante, texte et date.
Transformez vos données catégorielles en données numériques
Il est souvent plus facile de former un modèle sur des données numériques que sur des données catégorielles. Mais dans de nombreux cas, vos données brutes contiennent des informations catégorielles. C‘est à ce moment-là que la conversion de données catégorielles en données numériques s‘avère utile. Pour plus d‘informations sur la conversion de données catégorielles en données numériques
Ci-dessous, nous avons généré un fichier CSV à l‘aide du générateur CSV Snap. Le fichier CSV contient la colonne catégorie. Nous utilisons l‘encliquetage catégorique vers numérique pour encoder les valeurs de cette colonne. Nous appliquons à la fois l‘encodage d‘un nombre entier et l‘encodage d‘un nombre chaud pour voir les différences.
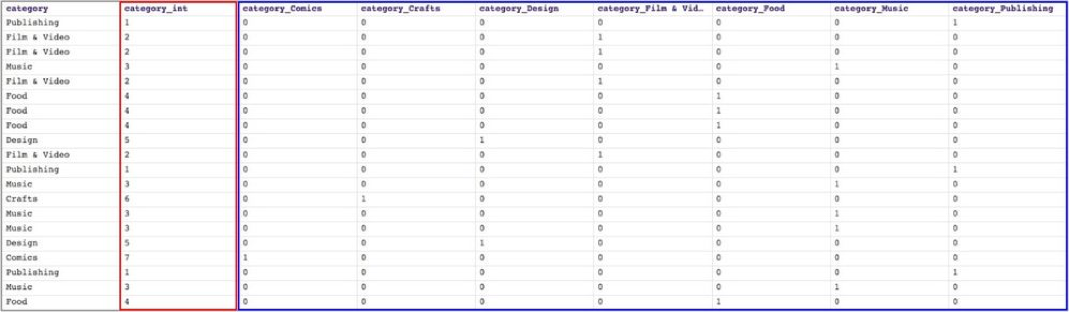
Le tableau ci-dessous montre le résultat de l‘opération Categorical to Numeric Snap. La première colonne correspond aux données originales du générateur CSV Snap. La colonne en rouge (category_int) est le résultat de l‘encodage des nombres entiers. Les colonnes en bleu (category_Comics, category_Crafts, category_Design, category_Film & Video, category_Food, category_Music, et category_Publishing) sont le résultat du One Hot Encoding. Maintenant que la colonne catégorielle est composée d‘entiers ou de données numériques, les data scientists peuvent facilement déplacer les données pour construire leur modèle d‘apprentissage automatique.
Les ML Snap Packs sont inclus dans SnapLogic Data Science, une extension de l‘Intelligent Integration Platform qui fournit une approche visuelle par glisser-déposer pour développer et déployer des modèles d‘apprentissage automatique. Découvrez nos autres ML Snap Packs : ML Core Snap Pack et ML Analytics Snap Pack.
Pour en savoir plus sur le Snap Pack de préparation des données ML, consultez le billet de blog " SnapLogic November 2018 Release : Révolutionnez votre entreprise grâce à l‘intégration intelligente. "

