





I sistemi ETL (extract, transform, and load) legacy sono in uso da oltre un decennio e raccolgono dati da diverse fonti, li standardizzano e li archiviano in un unico repository centrale. Tuttavia, gli studi rilevano che nove decision maker IT su dieci affermano che i sistemi legacy impediscono loro di sfruttare le tecnologie digitali di cui hanno bisogno per diventare più efficienti e far crescere la propria azienda.
Le ricerche dimostrano che le aziende moderne possono avere fino a 400 applicazioni, comprese quelle che generano enormi quantità di dati come i social media o le piattaforme mobili. L'esigenza del momento è quella di gestire in tempo reale questi grandi e crescenti volumi di dati, in formati diversi e con carichi di lavoro mutevoli. Per questo motivo, è in atto uno spostamento verso processi ETL moderni che eliminano le integrazioni point-to-point di dati eterogenei e offrono elevata scalabilità e prestazioni. Secondo alcuni studi, mentre alcuni anni fa il 72% dell'integrazione delle applicazioni avveniva on-premise, oggi la percentuale si attesta ad appena il 42%, il che indica una crescente adozione dell'elaborazione ETL basata su cloud.
Anche se questo può essere vero, molte organizzazioni sono ancora riluttanti ad abbandonare la loro configurazione legacy. Dopo aver investito tempo, sforzi e risorse considerevoli nella creazione di sistemi on-premise, il passaggio a processi moderni per queste organizzazioni significa cambiare mentalità e rielaborare l'intera supply chain. Inoltre, secondo Gartner, l'83% dei progetti di migrazione dei dati fallisce o supera il budget e i tempi previsti. Ciò è dovuto principalmente alle complessità legate all'esecuzione della migrazione vera e propria, che comprendono:
- Liberare i dati aziendali intrappolati dai record legacy
- Convalida dei dati
- Trasferimento di codice ETL, compresa la ristrutturazione o l'ottimizzazione
- Adattamento alla nuova piattaforma
- Identificare gli strumenti giusti da utilizzare
- Stabilire la sincronizzazione dei dati tra sistemi o applicazioni.
- Garantire che la comunicazione con altre applicazioni dipendenti dal legacy non sia compromessa.
Dite ciao a SNAPAHEAD
Per aiutare le aziende a rendere più semplice e veloce il passaggio da un sistema legacy a un moderno ETL, Agilisium ha unito le forze con SnapLogic per sviluppare SNAPAHEAD. SNAPAHEAD è un acceleratore di migrazione per l'integrazione dei dati da legacy a cloud , utilizzato prevalentemente con la piattaforma AWS. Con SnapLogic come piattaforma di integrazione dei dati, le aziende possono connettere in modo semplice e veloce l'intero ecosistema di applicazioni, API, database, big data, data warehouse, macchine e dispositivi con altri servizi remoti per creare la loro base di dati cloud e ricavare informazioni di business.
SNAPAHEAD automatizza la conversione del codice ETL legacy in pipeline conformi a SnapLogic, con un solo clic. Agilisium utilizza una combinazione di lift-and-shift e refactoring per migrare tutte le pipeline ETL legacy a SnapLogic. SNAPAHEAD riduce lo sforzo di implementazione del 25% e può facilmente portare a un risparmio sui costi fino al 30%.
Come funziona SNAPAHEAD
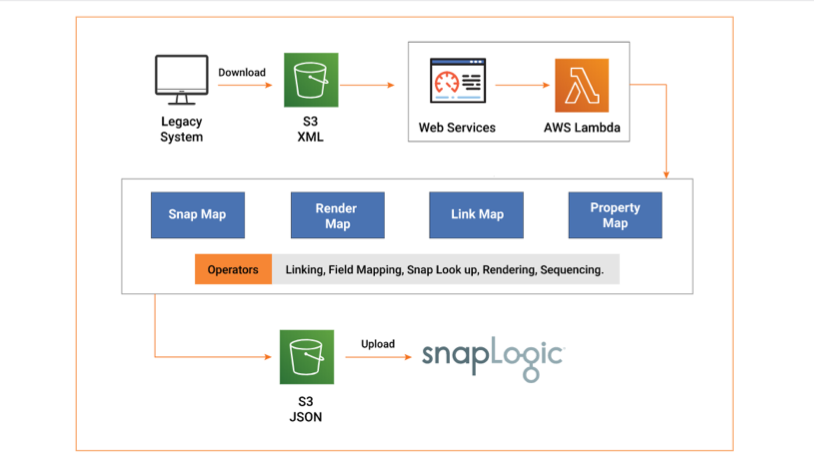
SNAPAHEAD prende in input il file XML generato dalla configurazione legacy. Lo strumento comprende il flusso di dati dall'origine alla destinazione, decodificando ogni trasformazione dei dati. SNAPAHEAD mappa quindi le trasformazioni negli snap corrispondenti di SnapLogic, che sono connettori intelligenti precostituiti che eseguono l'integrazione vera e propria. Gli snap, una volta messi insieme, costituiscono la pipeline di dati finale.
L'architettura di SNAPAHEAD può essere suddivisa in quattro grandi sezioni:
- Mappa degli snap: Questa sezione contiene una struttura simile a un dizionario che mappa la logica ETL con gli snap in SnapLogic. Esegue il compito di unire i due pezzi di funzionalità che sono logicamente equivalenti.
- Mappa dei collegamenti: Le strutture riunite dalla Snap Map sono collegate tra loro dalla Link Map. È questa che decide le fasi successive della pipeline, controllando così il flusso dei dati.
- Mappa delle proprietà: Ogni codice ETL legacy è dotato di un proprio insieme di configurazioni e caratteristiche o campi come la posizione delle tabelle o le proprietà della matrice, per citarne alcune. Il Property Mapper identifica tali parametri e li definisce negli snap equivalenti.
- Mappa di rendering: Gli snap consegnati a SnapLogic possono essere visti come una catena di funzioni che formano la pipeline. L'interfaccia utente include una disposizione ben definita per definire il posizionamento di questa pipeline sullo schermo. La Render Map automatizza questo aspetto per le pipeline renderizzate dagli strumenti.
SNAPAHEAD utilizza i bucket di storage Amazon S3 per archiviare i file con il codice legacy in ingresso e le pipeline SnapLogic in uscita. AWS Lambda, una piattaforma di elaborazione event-driven e serverless, costituisce la spina dorsale dell'acceleratore. AWS Lambda si occupa dei processi di elaborazione, dell'esecuzione del codice in risposta agli eventi e della gestione automatica delle risorse in base ai requisiti.
Come iniziare con SNAPAHEAD
Dal punto di vista dell'utente, la distribuzione di SNAPAHEAD è semplice. L'utente interagisce con SNAPAHEAD tramite un'interfaccia utente (UI) intuitiva e lo strumento genera una pipeline conforme a SnapLogic.
Guardate il breve video dimostrativo qui sotto per scoprire come iniziare a lavorare con SNAPAHEAD:
Come si può vedere dal video, la mappatura da legacy a Snaps può essere eseguita in pochi semplici passaggi:
Passo 1: accedere al bucket S3 dall'interfaccia utente di SnapLogic
Passo 2: caricare il file XML con le mappature del codice ETL legacy nel bucket S3
Fase 3: una volta caricato il file, fare clic su SNAPAHEAD
Fase 4: quando l'utente fa clic su SNAPAHEAD, il trigger basato su eventi in AWS Lambda viene notificato. AWS Lambda attiva automaticamente l'acceleratore SNAPAHEAD.
Passo 5: l'acceleratore legge il file ed esegue le conversioni della pipeline
Fase 6: Gli snap in uscita vengono resi in un file JSON
Passo 7: SNAPAHEAD invia il file JSON al bucket S3.
Passo 8: Scaricare il file JSON
Passo 9: caricare il file JSON in SnapLogic. La pipeline di dati di SnapLogic è pronta per ulteriori azioni.
Secondo Gartner, entro il 2022 almeno il 65% delle grandi organizzazioni avrà implementato una piattaforma di integrazione ibrida per alimentare la propria trasformazione digitale. SnapLogic è il vostro primo passo!
Ottenere. Imposta. SNAPAHEAD!





