





Come SnapLogic semplifica il complesso processo di caricamento dei dati Salesforce in Amazon Redshift
Mentre lavoravo a un complesso progetto di integrazione di dati Salesforce, ho iniziato a costruire qualcosa che, per me, si è trasformato in un'opera d'arte. Perché lo penso? Ve lo spiego. Ho lavorato con molti strumenti di integrazione di dati e applicazioni, ma nessuno mi ha dato la stessa soddisfazione artistica di SnapLogic Intelligent Integration Platform. Non c'è alcun codice coinvolto: è tutto drag and drop e semplice scripting. Eppure la soluzione risolve il problema molto complesso del caricamento dei dati di Salesforce nel data warehouse Amazon Redshift cloud .
In base alla mia esperienza con altri strumenti di integrazione, nessuno è riuscito a risolvere questo problema in modo così semplice, elegante e artistico. Infatti, ho stampato e incorniciato la pipeline di integrazione SnapLogic che ho costruito per questo caso d'uso e l'ho appesa alla parete della mia stanza di studio.
Prima di entrare nei dettagli di come ho costruito la pipeline, vorrei innanzitutto definire il problema.
La sfida: Spostare i dati di Salesforce in Redshift
Qualche tempo fa, ho aiutato Box, un'azienda leader nella gestione dei contenuti di cloud e cliente di SnapLogic, con un progetto di integrazione molto impegnativo. Il team di Box aveva formulato questi requisiti.
"Vogliamo estrarre i dati di Salesforce in un data warehouse, in questo caso Amazon Redshift. Ma gli oggetti di dati di Salesforce vengono aggiornati frequentemente e vengono aggiunti regolarmente nuovi campi. Pertanto, gli schemi delle tabelle di Redshift 'Load' devono essere modificati e i nuovi campi estratti da Salesforce. Inoltre, in Redshift sono state definite numerose viste del database che dipendono dagli schemi delle tabelle di "caricamento". Tutte le viste dovranno essere aggiornate".
Attualmente è un processo manuale per modificare gli schemi delle tabelle di Redshift in modo che corrispondano alle entità di Salesforce, aggiornare lo script SOQL di Salesforce per recuperare i nuovi campi dati di Salesforce, caricare i dati nelle tabelle di Redshift e, infine, aggiornare gli schemi delle viste di Redshift dipendenti. Se si moltiplica questa operazione per il numero di entità Salesforce, diventa un compito molto noioso.
E ora l'arte!
Pipeline SnapLogic: Integrazione in low-code dei dati di Salesforce
La prima pipeline confronta i campi entità di Salesforce con lo schema della tabella Redshift 'Load' associata per determinare le differenze, esegue un aggiornamento della tabella Redshift 'Load' e infine crea l'istruzione SOQL di Salesforce.
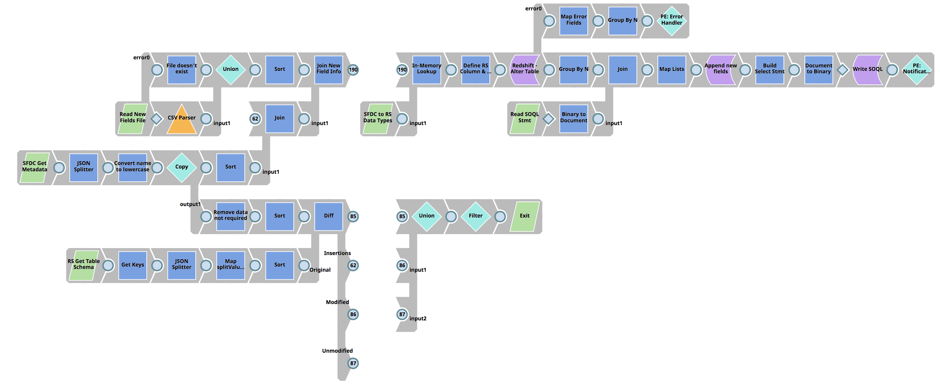
Passi più dettagliati:
- Utilizza l'API dei metadati di Salesforce per restituire tutti i campi di un'entità di Salesforce.
- Recuperare lo schema della tabella per la tabella di carico Redshift dell'entità Salesforce associata
- Utilizzate il Diff Snap per determinare le differenze tra i campi entità di Salesforce e le colonne della tabella di caricamento di Redshift.
- Con l'output del Diff Snap (le differenze tra le Entità di Salesforce e la tabella di carico di Redshift), unire i metadati di Salesforce per ottenere tutte le informazioni sui campi delle Entità di Salesforce.
- Utilizzare lo snap in memoria ed eseguire una ricerca per far corrispondere il tipo di campo di Salesforce con il tipo di dati di Redshift.
- Aggiungere le nuove colonne allo schema della tabella di caricamento di Redshift, utilizzando lo snap di esecuzione di Redshift.
- Caricare la versione precedente del file di istruzioni SOQL di Salesforce e unirlo all'elenco dei nuovi campi dati di Salesforce.
- Aggiornare il file di istruzioni SOQL per includere nuovi campi e scrivere su SLDB.
Quindi, estrarre i dati da Salesforce utilizzando l'istruzione SOQL e caricarli in blocco in Redshift:
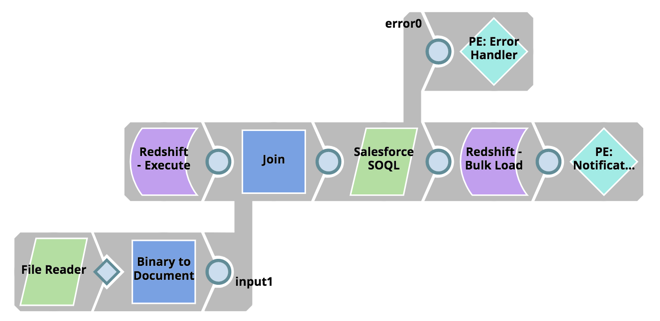
- Leggere lo script dell'istruzione SOQL aggiornato da SLDB
- Recuperare la data dell'ultima modifica dalla tabella di caricamento di Redshift.
- Utilizzare l'API SOQL di Salesforce, utilizzando lo snap SOQL di Salesforce, e recuperare tutti i record dalla data dell'ultima modifica.
- Utilizzando il Redshift Bulk Load Snap, caricare in blocco i dati in Redshift.
Infine, si determinano le dipendenze delle viste delle tabelle di Redshift, si recuperano gli schemi delle viste da Redshift (cioè la tabella pg_views), si creano gli script SQL per eliminare, creare e concedere i permessi alle viste e si eseguono le istruzioni SQL su Redshift:
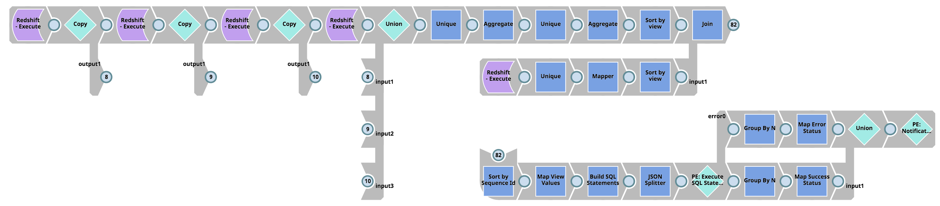
Tutte le pipeline descritte in precedenza accettano parametri di pipeline, quindi possiamo utilizzare un approccio orientato agli oggetti e riutilizzare queste pipeline per tutte le entità di Salesforce e le tabelle di Redshift. Ciò si ottiene semplicemente utilizzando lo snap di esecuzione della pipeline e passando i nomi delle entità di Salesforce, i nomi delle tabelle di Redshift, i nomi delle pipeline e così via. Anche in questo caso, la configurazione del Pipeline Execute Snap è sufficiente:
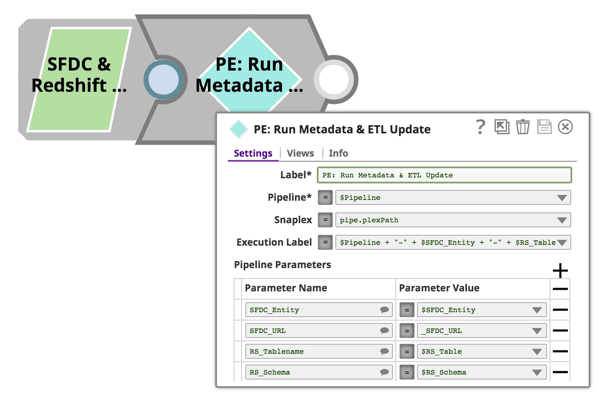
A mio avviso, l'arte sta nel fatto che tutte queste funzionalità sono ottenute rapidamente e senza alcuna codifica. Le pipeline sono visivamente belle dal punto di vista tecnico, se si considera la logica sottostante e il lavoro pesante svolto dal runtime SnapLogic.
Volete utilizzare gli oltre 500 connettori precostituiti (Snaps) di SnapLogic per integrare tutti i dati e le applicazioni più disparate? Iniziate una prova gratuita oggi stesso.




